一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
B站番剧默认评语前500条的爬取
2.主题式网络爬虫爬取的内容与数据特征分析
爬取的内容:
用户名,评语,发布时间,好评数,差评数,对番剧的评分
数据特征分析:
1、对评语做一个词云
2、对评分做数据统计
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
先获取当前页面和下一页页面的Url,分析下一页页面与当前页面的共同点和不同点,网页源代码对比页面上的信息分析,得出结果,然后用requests中的get获取页面信息,利用xpath来获取第一页评语页面的数据,利用页面数据底层的‘下一页的线索’的逐级获取每一页的数据,并在获取数据后存储在指定位置
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
按F12打开页面,观察html代码,可以看到每一个评语对应着代码上的一个li标签,同时每一个li标签下都包含每一个评语详情页面的数据。

2.Htmls页面解析
解析网站页面,并解析要获取的内容,通过解析可以发现我们想要获取的数据是在div标签下,div class="review-content"标签中
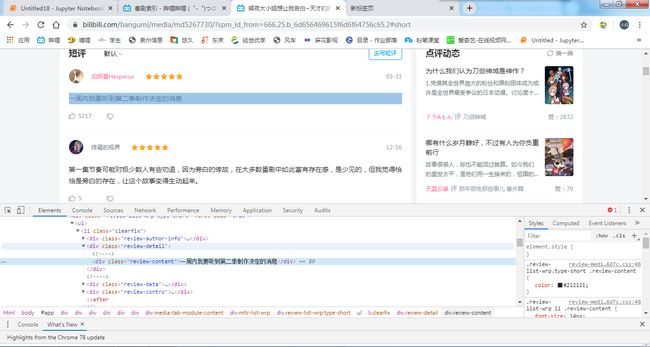
3.节点(标签)查找方法与遍历方法
得到当前节点的孩子遍历当前节点的孩子,每一个孩子去得到他们的孩子
节点的查找利用xpath方法,解析网页下的节点。用获取下一页面的URI的不同来遍历所有的标签
(必要时画出节点树结构)
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
1 import os 2 import csv 3 import xlwt 4 import time 5 import requests 6 import pandas as pd 7 8 curcount = 0 9 10 def main(): 11 url = 'https://api.bilibili.com/pgc/review/short/list?media_id=5267730&ps=20&sort=0' 12 crawling(url) 13 header = ('用户', '评语', '日期时间', '点赞数', '倒彩数', '评分') 14 csv = pd.read_csv('huiye.csv', encoding='utf-8')#row0 = [u'ID',u'name',u'av',u'play_num',u'comment_num'] 15 csv.to_excel('huiye.xlsx',header=header,index=False,sheet_name='data') 16 17 def crawling(url): 18 print(f'正在爬取:{url}') 19 global curcount 20 headers = {"User-Agent":'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36'} 21 json_content = requests.get(url, headers).json() 22 total = json_content['data']['total'] 23 infolist = [] 24 for item in json_content['data']['list']: 25 info = { 26 'author': item['author']['uname'],#用户名称 27 'content': item['content'],#评价 28 'ctime': time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(item['ctime'])),#日期时间 29 'likes': item['stat']['likes'],#喜欢的人数数 30 'disliked': item['stat']['disliked'],#不喜欢的人数 31 'score': item['score'],#评分 32 } 33 infolist.append(info) 34 with open('huiye.txt','a',encoding='utf-8') as f: 35 f.write(info['content']+"\n") 36 savefile(infolist) 37 38 39 curcount += len(infolist) 40 print(f'当前进度{curcount}/{500}') 41 if curcount >= total: 42 print('爬取完毕。') 43 return 44 45 nexturl = f'https://api.bilibili.com/pgc/review/short/list?' \ 46 f'media_id=5267730&ps=20&sort=0&cursor={json_content["data"]["next"]}' 47 time.sleep(1) 48 if curcount < 500: 49 crawling(nexturl) 50 51 52 def savefile(infos): 53 with open('huiye.csv', 'a', encoding='utf-8') as sw: 54 fieldnames = ['author', 'content', 'ctime', 'likes', 'disliked', 'score']# 定义字段的名称 55 writer = csv.DictWriter(sw, fieldnames=fieldnames)# 初始化一个字典对象 56 writer.writerows(infos)# 传入相应的字典数据 57 58 59 if __name__ == '__main__': 60 if os.path.exists('huiye.csv'):#如果WorkingCell.csv是一个存在的目录,则返回True。否则返回False。 61 os.remove('huiye.csv')#删除文件 62 if os.path.exists('huiye.txt'):#如果WorkingCell.csv是一个存在的目录,则返回True。否则返回False。 63 os.remove('huiye.txt')#删除文件 64 if os.path.exists('辉夜.txt'):#如果WorkingCell.csv是一个存在的目录,则返回True。否则返回False。 65 os.remove('辉夜.txt')#删除文件 66 if os.path.exists('huiye.xlsx'):#如果WorkingCell.csv是一个存在的目录,则返回True。否则返回False。 67 os.remove('huiye.xlsx')#删除文件 68 main()



2.对数据进行清洗和处理
2.1使用DataFrame进行数据加载
1 import pandas as pd 2 titanic=pd.DataFrame(pd.read_excel('huiye.xlsx')) 3 titanic.head(20)
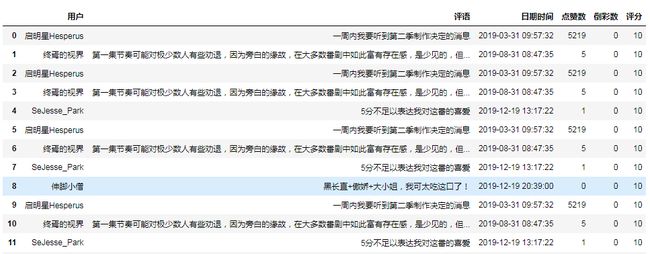
2.2数据重复值处理
1 titanic.duplicated()


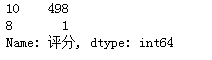
2.3好评数
1 titanic['评分'].isnull().value_counts()
3.文本分析(可选):jieba分词、wordcloud可视化
1 from wordcloud import WordCloud, ImageColorGenerator 2 from PIL import Image 3 import matplotlib.pyplot as plt 4 import numpy as np 5 path='huiye.txt' 6 bg_mask = np.array(Image.open('辉夜大小姐.jpg')) 7 text = open(path,encoding='utf-8').read() 8 my_wordcloud = WordCloud(background_color='white', # 设置背景颜色 9 mask=bg_mask, # 设置背景图片 10 max_words=500, # 设置最大显示的字数 11 font_path=r'C:\Windows\Fonts\STZHONGS.TTF', # 设置中文字体,使的词云可以显示 12 max_font_size=250, # 设置最大字体大小 13 random_state=30, # 设置有多少种随机生成状态, 即有多少种配色方案 14 scale=5 15 ) 16 myword = my_wordcloud.generate(text) 17 18 plt.imshow(myword) 19 plt.axis('off') 20 plt.show()

4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
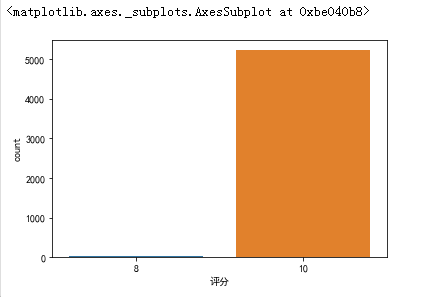
柱状图
1 import seaborn as sns 2 import matplotlib.pyplot as plt 3 plt.rcParams['font.sans-serif']=['SimHei'] 4 plt.rcParams['axes.unicode_minus'] = False 5 sns.countplot(titanic["评分"])
好评数和倒彩数的关系
sns.regplot(titanic["点赞数"],titanic["倒彩数"])
5.数据持久化

6.附完整程序代码
# -*- coding: utf-8 -*- # 时间 : 2019/12/19 12:23 # 作者 : zhuangjiangming # 文件 : 辉夜的短评.py # IDE: PyCharm #导入包 import os import csv import xlwt import time import requests import numpy as np import pandas as pd from PIL import Image import matplotlib.pyplot as plt from wordcloud import WordCloud, ImageColorGenerator curcount = 0 def main(): url = 'https://api.bilibili.com/pgc/review/short/list?media_id=5267730&ps=20&sort=0' crawling(url) header = ('用户', '评语', '日期时间', '点赞数', '倒彩数', '评分')#列表首行 csv = pd.read_csv('huiye.csv', encoding='utf-8') csv.to_excel('huiye.xlsx',header=header,index=False,sheet_name='data') def crawling(url): print(f'正在爬取:{url}') global curcount headers = {"User-Agent":'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36'} json_content = requests.get(url, headers).json() total = json_content['data']['total'] infolist = [] for item in json_content['data']['list']: info = { 'author': item['author']['uname'],#用户名称 'content': item['content'],#评价 'ctime': time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(item['ctime'])),#日期时间 'likes': item['stat']['likes'],#喜欢的人数数 'disliked': item['stat']['disliked'],#不喜欢的人数 'score': item['score'],#评分 } infolist.append(info) with open('huiye.txt','a',encoding='utf-8') as f: f.write(info['content']+"\n") savefile(infolist) curcount += len(infolist) print(f'当前进度{curcount}/{500}') if curcount >= total: print('爬取完毕。') return nexturl = f'https://api.bilibili.com/pgc/review/short/list?' \ f'media_id=5267730&ps=20&sort=0&cursor={json_content["data"]["next"]}' time.sleep(1) if curcount < 500: crawling(nexturl) def savefile(infos): with open('huiye.csv', 'a', encoding='utf-8') as sw: fieldnames = ['author', 'content', 'ctime', 'likes', 'disliked', 'score']# 定义字段的名称 writer = csv.DictWriter(sw, fieldnames=fieldnames)# 初始化一个字典对象 writer.writerows(infos)# 传入相应的字典数据 if __name__ == '__main__': if os.path.exists('huiye.csv'):#如果WorkingCell.csv是一个存在的目录,则返回True。否则返回False。 os.remove('huiye.csv')#删除文件 if os.path.exists('huiye.txt'): os.remove('huiye.txt') if os.path.exists('辉夜.txt'): os.remove('辉夜.txt') if os.path.exists('huiye.xlsx'): os.remove('huiye.xlsx') main()
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
我从这些图里了解到了观看这部番剧的B站用户大部分都喜欢这部番剧,大部分的人的评语都是太喜欢了,期待第二季,说明这部番剧是很受B站大众人群的喜欢
2.对本次程序设计任务完成的情况做一个简单的小结。
我印象最深的是xpath方法直接就从网页中的信息获取到了网页源代码中数据所在的位置,加以调用,B站短评之间又有一些关系,利用这些关系来逐级获取之后的信息数据,前段时间的学习作为了基础,让我能更好的去编写这份程序,虽然基础不是很全面,但是却清晰的提供了我关于网站与网站之间的关系,加深了我对Python爬虫的印象。