使用#注释:
在Python中使用#进行标识注释,从#开始到当前行结束的部分都是注释。注释只对当前行起作用,并且Python没有多行注释。但是,如果出现在文本串中,将回归普通字符#的角色。
使用\连接:
一行程序最大长度建议80字符。如果一行代码写不完,可以使用连接符\ (反斜线)把它放在一行的结束位置,Python仍然将其解释为一行。
使用if语句判断:
计算机之所以能做很多自动化的任务,因为它可以自己做条件判断。
比如,输入用户年龄,根据年龄打印不同的内容,在Python程序中,可以用if语句实现:
age = 20
if age >= 18:
print ('your age is', age)
print ('adult')
print ('END')
注意:Python代码的缩进规则。具有相同缩进的代码被视为代码块,上面的3,4行 print 语句就构成一个代码块(但不包括第5行的print)。如果 if 语句判断为 True,就会执行这个代码块。
缩进请严格按照Python的习惯写法:4个空格,不要使用Tab,更不要混合Tab和空格,否则很容易造成因为缩进引起的语法错误。
注意:if 语句后接表达式,然后用:表示代码块开始。
如果你在Python交互环境下敲代码,还要特别留意缩进,并且退出缩进需要多敲一行回车:
>>> age = 20
>>> if age >= 18:
... print ('your age is', age)
... print ('adult')
使用if-else进行判断:
当 if 语句判断表达式的结果为 True 时,就会执行 if 包含的代码块:
if age >= 18:
print ('adult')
如果我们想判断年龄在18岁以下时,打印出 'teenager',怎么办?
方法是再写一个 if:
if age < 18:
print ('teenager')
或者用 not 运算:
if not age >= 18:
print ('teenager')
细心的同学可以发现,这两种条件判断是“非此即彼”的,要么符合条件1,要么符合条件2,因此,完全可以用一个 if ... else ... 语句把它们统一起来:
if age >= 18:
print ('adult')
else:
print ('teenager')
利用 if ... else ... 语句,我们可以根据条件表达式的值为 True 或者 False ,分别执行 if 代码块或者 else 代码块。
注意: else 后面有个“:”。
Python中的常见的比较操作符:
相等 ==
不相等 !=
小于 <
不大于 <=
大于 >
不小于 >=
属于 in...
这些操作符的执行结果都是返回布尔值True或者False。如果向想同时进行多重判断,可以使用布尔操作符and,or或者not连接来决定最终表达式的布尔值。布尔操作符的优先级没有比较表达式的代码高,也就是说表达式先计算,然后再比较,为了避免混乱,可以用小括号将表达式括起来。
小栗子:x=7 5
如果对同一个变量做多个and比较操作,Python允许下面的用法: 5
这个表达式和5
什么是真值:
一个成假赋值不一定明确表示为False,下面的情况也会被认为是False。
布尔 : False
null 类型 : None
整型 0
浮点型: 0.0
空字符串:' '
空列表: [ ]
空元组:()
空字典:{}
空集合:set()
剩下的都会被认为为真值。
如果你在判断一个表达式不是一个简单的变量,Python会先计算表达式的值,然后返回布尔型结果。栗子: if color=="red":
使用while进行循环:
和for循环不同,while循环不会迭代list或者tuple元素,而是跟据表达式判断循环是否结束。
N=10
x=0
while x
print(x)
x=x+1
while循环每次先判断是否x
在循环体内,x = x + 1 会让 x 不断增加,最终因为 x < N 不成立而退出循环。
如果没有这一个语句,while循环在判断 x < N 时总是为True,就会无限循环下去,变成死循环,所以要特别留意while循环的退出条件。
使用break跳出循环:
用 for 循环或者 while 循环时,如果要在循环体内直接退出循环,可以使用 break 语句。
比如计算1至100的整数和,我们用while来实现:
sum = 0
x = 1
while True:
sum = sum + x
x = x + 1
if x > 100:
break
print sum
while True 本身是一个死循环,但是在循环体内,我们还判断了 x > 100 条件成立时,用break语句退出循环,这样也可以实现循环的结束。break是退出整个循环体。
使用continue跳到循环开始:
栗子:读入一个整数,如果是奇数就输出它的平方,如果是偶数则跳过。使用q结束循环
In [1]: while True:
...: value= input("Integer,please [q to quit] : ")
...: if value=="q": #停止循环
...: break
...: number=int(value)
...: if number %2 ==0: #判断偶数
...: continue
...: print (number,"squared is",number*number)
循环外使用else:
如果循环正常结束(没有使用break跳出),程序将进入到可选的else段。当使用循环来遍历一数据结构的时候,找到满足条件的解使用break跳出;循环结束,即没有找到可行解时,将执行else部分代码段:
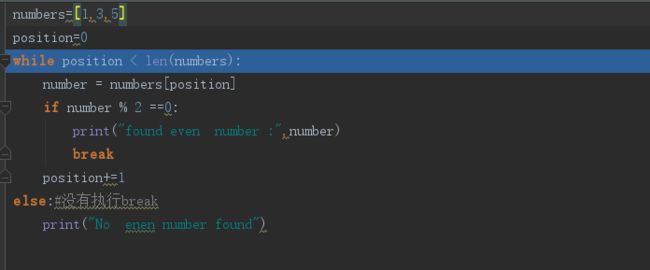
上面执行结果为:No enen number found
使用for迭代:
Python频繁的使用迭代器。它允许数据结构长度未知和具体实现未知的情况下遍历整个数据结构,并且支持迭代快速读写中的数据,以及不能一次读入计算机内存的数据流的处理。
列表,字符串,元组,字典,集合等都是Python中可迭代的对象。元组或列表在一次迭代过程产生一项,而字符串迭代会产生一个字符,对于一个字典进行迭代可以返回字典中的键,所使用字典的values()函数可以实现对值的迭代,使用字典的items()函数可以以元组的形式返回键值对。
list=["hello","word","allow","python"]
string="hdsfjmck"
dict={"room":"ballroom","weapon":"lead pipe","person":"xiaom"}
for lists in list:
print(lists)
for chart in string:
print(chart)
for keys,values in dict.items():
print(keys,":",values)
循环外使用else:
类似于while,for循环也可以使用可选的else代码段,用来判断for循环是否正常结束(没有调用break跳出),否则执行else段。

使用zip()并行迭代:
在迭代的时候可以使用zip()进行并行迭代,zip()函数在最短序列用完的时候就会停止。
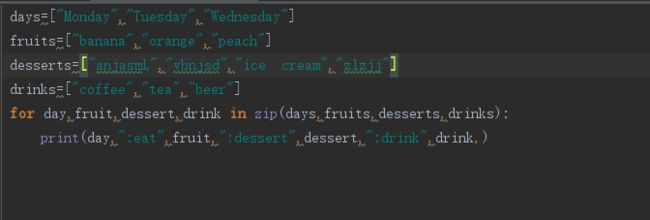
上面的只能遍历到desserts的前三个,以最短序列为准。
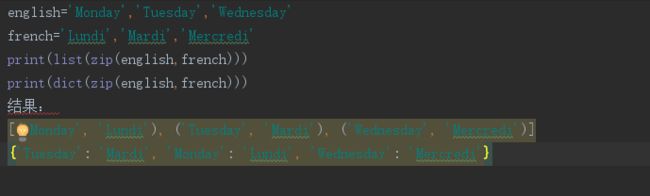
现使用zip()函数配对两个元组。函数的返回值既不是元组也不是列表,而是一个整合在一起的可迭代变量,配合dict()函数和zip()函数的返回值可以得到一个字典。
使用range()生成自然数序列:
range()函数返回在特定区间的自然数序列,不需要创建和存储复杂的数据结构,例如列表和元组。rang()函数的用法:rang(start,stop,step)。start默认值为0,唯一要求的参数是stop,产生的最后一个数是stop的前一个,并且step的默认值是1。也可以反向创建自然数序列,这时step的值为-1。
像zip(),rang()这些函数的返回的是一个可以迭代的对象,所以可以使用for...in的皆否进行遍历,或者把这个对象转化为一个序列(例如列表)。
for x in range(0,3) list(range(0,3))
推导式:
推导式是一个或者多个迭代器快速简洁地创建数据结构的一种方法。
列表推导式:
最简单的形式:[ expression for item in iterable]
栗子:number_list=[number for number in range(1,6)]-->[1, 2, 3, 4, 5]
列表推到把循环放在方括号内,也可以加上条件表达式:
[expression for item in iterable if condition]
栗子:number_list=[number for number in range(1,6) if number % 2 ==0 ] -->[2, 4]
对于多重循环,对应的推导式中会有很多个for...语句。
栗子:外层循环在前面
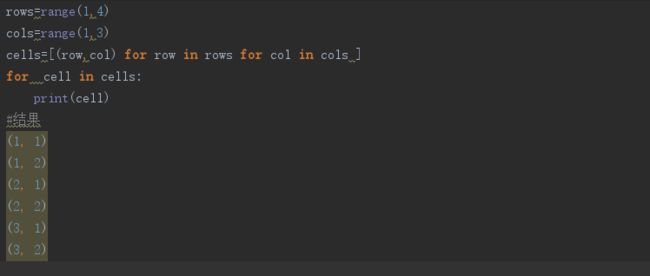
字典推导式:
字典生成式样式:{key_expression : value_expression for expression in iterable}
类似于列表推导,字典推导也有if条件判断以及多个for循环迭代语句:

在程序中,对字符串‘letters’中出现的字母进行循环,计算出每个字母出现的次数,对于上图的程序来说,两次调用word.count(letter)浪费时间,因为字符串中t和e都出现了两次,第一次调用word.count()时已经计算得到相应的值。通过修改推导式,可以解决这个问题:
letter_counts={letter : word.count(letter) for letter in set(word) }
通过set()将迭代值去重。
集合推导式:
集合最简的推导式和列表,字典的类似:{expression for expression in iterable}
最长的版本(if tests,multiple for clauses)对于集合也可行:
a_set={number for number in range(1,6) if number % 3 ==1 } -->{1, 4}
生成器推导式:
元组是没有推导式的。下面的表达式是生成器推导式,返回的是一个生成器对象:
number_thing=(number for number in range(1,6)) -->type(number_thing)-->generator
他是将数据传递给迭代器的一种方式:
for number in number_thing:
print(number) -->1 2 3 4 5
通过对生成器的推导式调用list()函数,可以使它类似于列表推导式:
number_list=list(number_thing)-->[1, 2, 3, 4, 5]
一个生成器只能运行一次。列表,集合,字符串,字典都存储在内存中,但那时生成器仅在运行中产生值,不会被保存下来,所以不能重新使用或者备份一个生成器。
可以通过生成器推导式创建生成器,也可以通过使用生成器函数创建。
注:本文内容来自《Python语言及其应用》欢迎购买原书阅读