各国GDP数据可视化 数据来自世界银行
导入资源包,如下:
Pandas, numpy, seaborn 和 matplotlib
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns导入数据
数据下载
Country_GDP= pd.read_csv("Country_GDP.csv",sep=";")
df = pd.DataFrame(Country_GDP)显示列名
Country_GDP.columns典型数据处理
1.增加一列数据,显示从2013年到2018年各国GDP增加率
df['increaseRate2013-2018'] = (df["2018"] - df["2013"])/df["1990"] *1002.按照'increaseRate2013-2018'列的升序显示数据,并将新值付给新的df
df = df.sort_values(by='increaseRate2013-2018',ascending=True)3.如果在打印时,看到显示在屏幕上的数列数过少,可以使用pd.set_option('display.max_rows',20)来进行设置
pd.set_option('display.max_rows',20)4.删除一些不需用用的行值 使用df['Country Name']找到Country Name列,并查找等于"World值得的列,找到这一列后,显示它的index. 最后使用df.drop删除
df=df.drop(df[df['Country Name']=="World"].index,axis=0)
df=df.drop(df[df['Country Name']=="High income"].index,axis=0)
df=df.drop(df[df['Country Name']=="OECD members"].index,axis=0)
df=df.drop(df[df['Country Name']=="Post-demographic dividend"].index,axis=0)
df=df.drop(df[df['Country Name']=="Europe & Central Asia"].index,axis=0)
df=df.drop(df[df['Country Name']=="European Union"].index,axis=0)
df=df.drop(df[df['Country Name']=="IBRD only"].index,axis=0)
df=df.drop(df[df['Country Name']=="Middle income"].index,axis=0)
df=df.drop(df[df['Country Name']=="Low & middle income"].index,axis=0)
df=df.drop(df[df['Country Name']=="IDA & IBRD total"].index,axis=0)
df=df.drop(df[df['Country Name']=="Post-demographic dividend"].index,axis=0)
df=df.drop(df[df['Country Name']=="Late-demographic dividend"].index,axis=0)
df=df.drop(df[df['Country Name']=="Upper middle income"].index,axis=0)
df=df.drop(df[df['Country Name']=="Late-demographic dividend"].index,axis=0)
df=df.drop(df[df['Country Name']=="North America"].index,axis=0)
df=df.drop(df[df['Country Name']=="East Asia & Pacific"].index,axis=0)
df=df.drop(df[df['Country Name']=="Euro area"].index,axis=0)
df=df.drop(df[df['Country Name']=="Early-demographic dividend"].index,axis=0)
df=df.drop(df[df['Country Name']=="East Asia & Pacific (excluding high income)"].index,axis=0)
df=df.drop(df[df['Country Name']=="East Asia & Pacific (IDA & IBRD countries)"].index,axis=0)
df=df.drop(df[df['Country Name']=="Late-demographic dividend"].index,axis=0)
df=df.drop(df[df['Country Name']=="Latin America & Caribbean"].index,axis=0)
df=df.drop(df[df['Country Name']=="Latin America & the Caribbean (IDA & IBRD coun..."].index,axis=0)
df=df.drop(df[df['Country Name']=="Latin America & Caribbean (excluding high income)"].index,axis=0)
df=df.drop(df[df['Country Name']=="Lower middle income"].index,axis=0)
df=df.drop(df[df['Country Name']=="Latin America & the Caribbean (IDA & IBRD coun..."].index,axis=0)
df=df.drop(df[df['Country Name']=="Europe & Central Asia (IDA & IBRD countries)"].index,axis=0)
df=df.drop(df[df['Country Name']=="Middle East & North Africa"].index,axis=0)
df=df.drop(df[df['Country Name']=="South Asia (IDA & IBRD)"].index,axis=0)
df=df.drop(df[df['Country Name']=="Europe & Central Asia (excluding high income) "].index,axis=0)
df=df.drop(df[df['Country Name']=="Arab World"].index,axis=0)
df=df.drop(df[df['Country Code']=="TLA"].index,axis=0)
df=df.drop(df[df['Country Code']=="ECA"].index,axis=0)
df=df.drop(df[df['Country Code']=="SAS"].index,axis=0)
df=df.drop(df[df['Country Code']=="ECA"].index,axis=0)
df=df.drop(df[df['Country Code']=="IDA"].index,axis=0)
df=df.drop(df[df['Country Code']=="SSF"].index,axis=0)
df=df.drop(df[df['Country Code']=="TSS"].index,axis=0)
df=df.drop(df[df['Country Code']=="SSA"].index,axis=0)
df=df.drop(df[df['Country Code']=="CEB"].index,axis=0)
df=df.drop(df[df['Country Code']=="PRE"].index,axis=0)
df=df.drop(df[df['Country Code']=="LDC"].index,axis=0)
df=df.drop(df[df['Country Code']=="IDB"].index,axis=0)
df=df.drop(df[df['Country Code']=="IDX"].index,axis=0)
df=df.drop(df[df['Country Code']=="FCS"].index,axis=0)
df=df.drop(df[df['Country Code']=="IDB"].index,axis=0)
df=df.drop(df[df['Country Code']=="HPC"].index,axis=0)
df=df.drop(df[df['Country Code']=="OSS"].index,axis=0)
df=df.drop(df[df['Country Code']=="SST"].index,axis=0)
df=df.drop(df[df['Country Code']=="LIC"].index,axis=0)
df=df.drop(df[df['Country Code']=="MNA"].index,axis=0)
df=df.drop(df[df['Country Code']=="TMN"].index,axis=0)
5.查看前10行数据
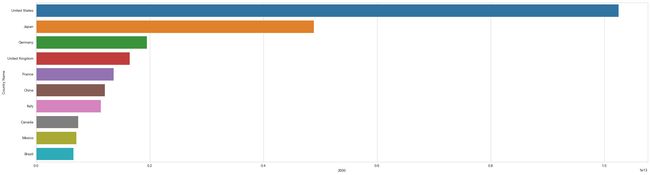
df.iloc[0:10,]图像可视化
sns.set_style("whitegrid")
plt.figure(figsize=(30,8))
df = df.sort_values(by='2000',ascending=False)
sns.barplot(x='2000', y='Country Name',data=df.iloc[0:10,], orient='h')结果
References:
GDP (current US$)