Python高级应用程序设计任务要求
用Python实现一个面向主题的网络爬虫程序,并完成以下内容:
(注:每人一题,主题内容自选,所有设计内容与源代码需提交到博客园平台)
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
基于requests库实现的携程网爬虫爬取航班信息
2.主题式网络爬虫爬取的内容与数据特征分析
爬取任意城市的航班信息,做数据保存和数据可视化
分析每个城市的航班路程多少和价格高低
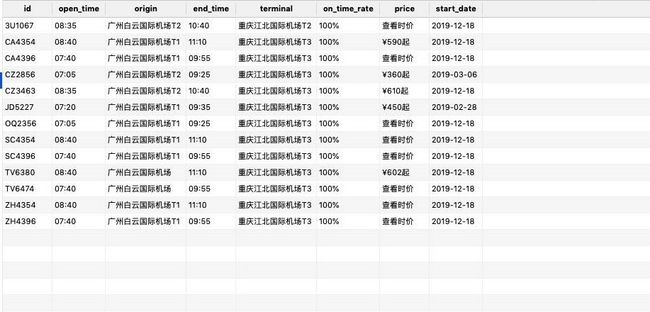
爬取内容:航空公司,起飞时间,起点,落地时间,终点,准点率,价格,出发日期
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:①使用requests库与bs4来实现
②使用浏览器的开发者工具,找到携程网的源码,进行分析
③根据网站的url可以知道该网站为静态网站
④想实现输入地点与目的地就可以爬出数据(但是做不出来,只能通过浏览器更改url的方式去爬取,以后学习跟多会想办法实现)
⑤把数据写入Excel中
⑥通过nokebook进行数据可视化和数据清洗
技术难点:①需要找到页面的headers,需要用到开发者工具去找(F12)
②编写代码难度大,参考了几个CSDN博客中的爬虫,但是都因为网站更新无法使用
③做不到更为便捷的爬取信息的方法,用户体验差
④Python录入Excel及其不方便,会覆盖原来的信息,录入时有麻烦
⑤携程网有好几种不同的查询方法,我爬取的是城市,然后我输入的url是日期的,就爬取失败
⑥python的很多库非常难安装,比如sklearn库,查百度查了非常久
⑦不知道为什么seaborn库无法导入csv文件
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
主体为携程的航班时刻查询,表头,表中,表尾,是一个静态网页
2.Htmls页面解析
爬取网页的url = https://flights.ctrip.com/domestic/schedule/
因为携程网会有非常多不同的查询方法,然后我爬取是用城市,所以需要用这个网页打开来选择地址进行爬取
每个网页都有20条航班数据
https://flights.ctrip.com/domestic/schedule/sha.can.html 进过分析在网页的后面有所不同,城市会改变
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
遍历方法:通过开发者工具可以看到每个li标签里都存放着对应首字母开头的地方航班,每个a标签的内容是地方航班的名称以及链接,
得到所有的li标签,再得到每个li标签里的a标签,所有的航班都存放在tbody标签中,每个tr标签对应着一个航班的信息,我们只要通过分析每个tr标签,
就可以得到想要的数据
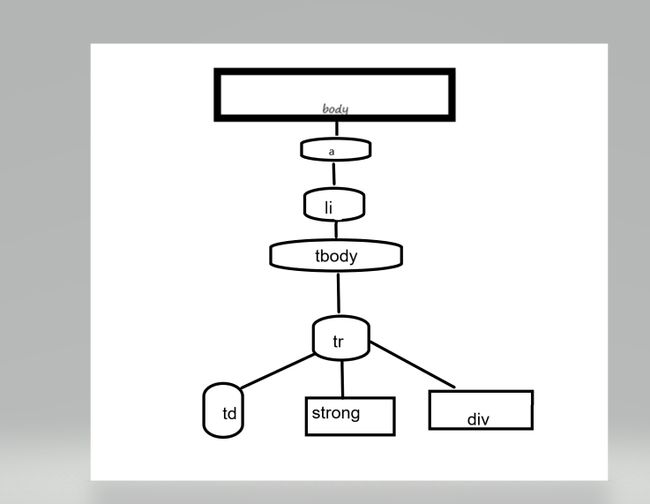
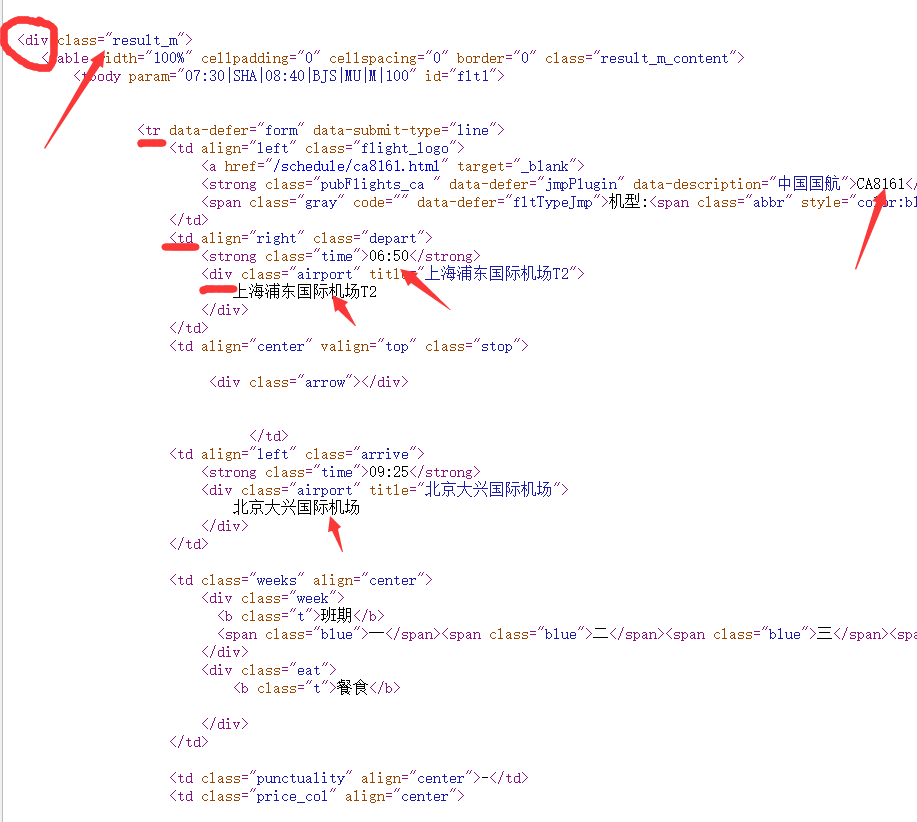
需要爬取得数据源码格式都差不多相同,所以就不放图了
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
采用文件格式进行代码编写
air_list.py
import requests
from bs4 import BeautifulSoup
import lxml
headers = {
'authority': 'flights.ctrip.com',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'sec-fetch-site': 'same-origin',
'referer': 'https://flights.ctrip.com/domestic/schedule/can.sha.p2.html',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'airlineSearchString=can=^%^E5^%^B9^%^BF^%^E5^%^B7^%^9E^&sha=^%^E4^%^B8^%^8A^%^E6^%^B5^%^B7(SHA)^&ctu=^%^E6^%^88^%^90^%^E9^%^83^%^BD(CTU)^&szx=^%^E6^%^B7^%^B1^%^E5^%^9C^%^B3(SZX); _abtest_userid=60ace6b4-14ea-4077-8ed2-99b8281b0e39; _RSG=Mlaa3B7qrCCJ.5Hlo5p03B; _RDG=28ac7565a7375721f320bc2cebb6a391b4; _RGUID=c335d072-c392-4bd6-b0c0-cc5caf445f93; _ga=GA1.2.956839008.1573723290; _RF1=183.14.28.253; _gid=GA1.2.1606880167.1576575644; Session=SmartLinkCode=csdn^&SmartLinkKeyWord=^&SmartLinkQuary=_UTF.^&SmartLinkHost=blog.csdn.net^&SmartLinkLanguage=zh; MKT_CKID=1576575643793.wvsyk.2yit; MKT_CKID_LMT=1576575643794; MKT_Pagesource=PC; gad_city=31f35a60e938dff697ddea628b5bea7c; ASP.NET_SessionId=g5syx543pa1gpazldabkohfe; ASP.NET_SessionSvc=MTAuMTQuMy41Mnw5MDkwfG91eWFuZ3x8MTU3NjUxMzkzNTk4Mg; _bfa=1.1573723286179.2ro82c.1.1574999099133.1576575640866.3.10; _bfs=1.8; _jzqco=^%^7C^%^7C^%^7C^%^7C1576575643995^%^7C1.2045907305.1573723290255.1576575770256.1576575800279.1576575770256.1576575800279.0.0.0.9.9; __zpspc=9.3.1576575643.1576575800.7^%^233^%^7Cblog.csdn.net^%^7C^%^7C^%^7C^%^7C^%^23; _bfi=p1^%^3D101021^%^26p2^%^3D101021^%^26v1^%^3D10^%^26v2^%^3D9; appFloatCnt=7',
}
def get_air_list(url):
response = requests.get(url, headers=headers)
soup=BeautifulSoup(response.text,"lxml")
table=soup.find("table",attrs={"class":"result_m_content"})
trs=table.find_all("tr")
result_list=[]
for r_index,tr in enumerate(trs):
tr_list=[]
tds=tr.find_all("td")
for c_index,td in enumerate(tds):
if c_index==0:
strong=td.find("strong")
tr_list.append(strong.text)
if c_index==1 or c_index==3:
strong=td.find("strong")
tr_list.append(strong.text)
div = td.find("div")
tr_list.append(div.text.replace("\n","").strip())
if c_index==5 or c_index==6:
tr_list.append(td.text.replace("\n","").strip())
if c_index==7:
input=td.find("input")
tr_list.append(input['value'])
result_list.append(tr_list)
return result_list
一开始我想直接把取得的数据直接保存为xlsx,但是会一直覆盖
excel_write.py
import xlwt
def write(path, rows):
"""
将数据写入Excel文件\n
:param path: 文件路径,包含文件名称
:param rows: 二维数组数据列表
"""
workbook = xlwt.Workbook(encoding='utf-8')
# 创建表
worksheet = workbook.add_sheet('sheet 0')
# 写数据
for row_index in range(len(rows)):
row = rows[row_index]
for col_index in range(len(row)):
cell = row[col_index]
worksheet.write(row_index, col_index, label=cell)
# 保存
workbook.save(path)
所以只能保存到数据库中
数据持久化
sqllite_opr.py
#!/usr/bin/env python
# coding=utf-8
import pymysql
import logging
import threading
import datetime
import sqlite3
def connectdb():
#print('连接到mysql服务器...')
# 打开数据库连接
cx = sqlite3.connect("flight.db")
return cx
def create_table():
sql='''CREATE TABLE flight(
id VARCHAR (50) NOT NULL ,
open_time VARCHAR (50) NOT NULL ,
origin VARCHAR (50) NOT NULL ,
end_time VARCHAR (50) NOT NULL ,
terminal VARCHAR (50) NOT NULL ,
on_time_rate VARCHAR (50) NOT NULL ,
price VARCHAR (50) NOT NULL ,
start_date VARCHAR (50) NOT NULL ,
PRIMARY KEY (id)
)'''
con = connectdb()
cur = con.cursor()
cur.execute(sql)
con.commit()
con.close()
def exist(cur,list):
sql="SELECT * from flight where id ='{}' ".format(list[0])
logging.info("查询sql:{}".format(sql))
s = cur.execute(sql)
count = cur.fetchall()
if count:
# 已经存在
return True
else:
return False
def batch_insert(tow_dim_list):
con = connectdb()
cur = con.cursor()
try:
for list in tow_dim_list:
if not exist(cur,list):
sql = "insert into flight VALUES ('{}','{}','{}','{}','{}','{}','{}','{}')".format(list[0], list[1],list[2],list[3],list[4],list[5],list[6],list[7])
logging.info("sql:{}".format(sql))
cur.execute(sql)
con.commit()
except Exception as e:
print("插入数据库出现异常:{}".format(str(e)))
con.rollback()
finally:
cur.close()
con.close()
if __name__ == '__main__':
connectdb()
最后写一个mian.py就可以执行爬虫了
# -*- coding: utf-8 -*-
import air_list
import sqllite_opr
#创建数据库
# sqllite_opr.create_table()
url=input("请输入要爬取的连接:")
get_air_list = air_list.get_air_list(url)
sqllite_opr.batch_insert(get_air_list)
print("插入完成")

剩下几个文件是我还没能写出来的代码,我就不放上来了
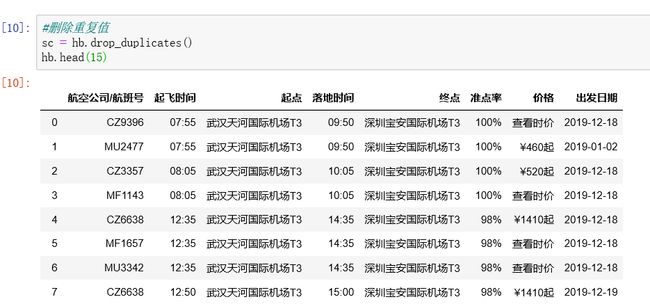
2.对数据进行清洗和处理
#价格最便宜的10个航班
#价格最便宜的10个航班
print(hb.sort_values('价格',ascending=False).head(10))

#获取空值 hb["价格"].isnull().value_counts()

查看异常
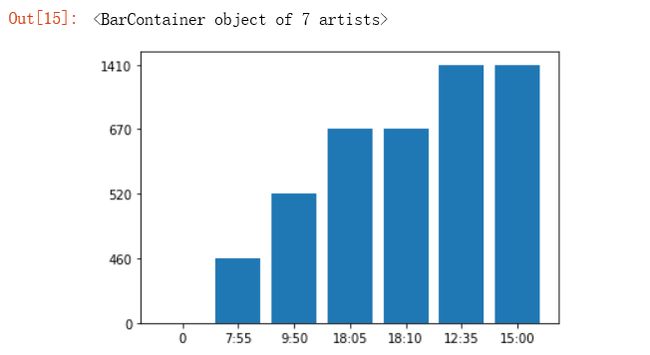
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
#根据得到的数据,绘制垂直树状图 plt.bar(['0','7:55','9:50','18:05','18:10','12:35','15:00'],['0','460','520','670','670','1410','1410'],label="机票在不同时间的价格")
#价格与准点率散点图 plt.scatter(df.价格,df.准点率,color='K',s=25,marker='o')

#查看终点 import pandas as pd hb['终点'].value_counts()

6.附完整程序代码
# -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup import lxml headers = { 'authority': 'flights.ctrip.com', 'upgrade-insecure-requests': '1', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36', 'sec-fetch-mode': 'navigate', 'sec-fetch-user': '?1', 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', 'sec-fetch-site': 'same-origin', 'referer': 'https://flights.ctrip.com/domestic/schedule/can.sha.p2.html', 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9', 'cookie': 'airlineSearchString=can=^%^E5^%^B9^%^BF^%^E5^%^B7^%^9E^&sha=^%^E4^%^B8^%^8A^%^E6^%^B5^%^B7(SHA)^&ctu=^%^E6^%^88^%^90^%^E9^%^83^%^BD(CTU)^&szx=^%^E6^%^B7^%^B1^%^E5^%^9C^%^B3(SZX); _abtest_userid=60ace6b4-14ea-4077-8ed2-99b8281b0e39; _RSG=Mlaa3B7qrCCJ.5Hlo5p03B; _RDG=28ac7565a7375721f320bc2cebb6a391b4; _RGUID=c335d072-c392-4bd6-b0c0-cc5caf445f93; _ga=GA1.2.956839008.1573723290; _RF1=183.14.28.253; _gid=GA1.2.1606880167.1576575644; Session=SmartLinkCode=csdn^&SmartLinkKeyWord=^&SmartLinkQuary=_UTF.^&SmartLinkHost=blog.csdn.net^&SmartLinkLanguage=zh; MKT_CKID=1576575643793.wvsyk.2yit; MKT_CKID_LMT=1576575643794; MKT_Pagesource=PC; gad_city=31f35a60e938dff697ddea628b5bea7c; ASP.NET_SessionId=g5syx543pa1gpazldabkohfe; ASP.NET_SessionSvc=MTAuMTQuMy41Mnw5MDkwfG91eWFuZ3x8MTU3NjUxMzkzNTk4Mg; _bfa=1.1573723286179.2ro82c.1.1574999099133.1576575640866.3.10; _bfs=1.8; _jzqco=^%^7C^%^7C^%^7C^%^7C1576575643995^%^7C1.2045907305.1573723290255.1576575770256.1576575800279.1576575770256.1576575800279.0.0.0.9.9; __zpspc=9.3.1576575643.1576575800.7^%^233^%^7Cblog.csdn.net^%^7C^%^7C^%^7C^%^7C^%^23; _bfi=p1^%^3D101021^%^26p2^%^3D101021^%^26v1^%^3D10^%^26v2^%^3D9; appFloatCnt=7', } def get_air_list(url): response = requests.get(url, headers=headers) soup=BeautifulSoup(response.text,"lxml") table=soup.find("table",attrs={"class":"result_m_content"}) trs=table.find_all("tr") result_list=[] for r_index,tr in enumerate(trs): tr_list=[] tds=tr.find_all("td") for c_index,td in enumerate(tds): if c_index==0: strong=td.find("strong") tr_list.append(strong.text) if c_index==1 or c_index==3: strong=td.find("strong") tr_list.append(strong.text) div = td.find("div") tr_list.append(div.text.replace("\n","").strip()) if c_index==5 or c_index==6: tr_list.append(td.text.replace("\n","").strip()) if c_index==7: input=td.find("input") tr_list.append(input['value']) result_list.append(tr_list) return result_list #!/usr/bin/env python # coding=utf-8 import pymysql import logging import threading import datetime import sqlite3 def connectdb(): #print('连接到mysql服务器...') # 打开数据库连接 # 用户名:hp, 密码:Hp12345.,用户名和密码需要改成你自己的mysql用户名和密码,并且要创建数据库TESTDB,并在TESTDB数据库中创建好表Student cx = sqlite3.connect("flight.db") return cx def create_table(): sql='''CREATE TABLE flight( id VARCHAR (50) NOT NULL , open_time VARCHAR (50) NOT NULL , origin VARCHAR (50) NOT NULL , end_time VARCHAR (50) NOT NULL , terminal VARCHAR (50) NOT NULL , on_time_rate VARCHAR (50) NOT NULL , price VARCHAR (50) NOT NULL , start_date VARCHAR (50) NOT NULL , PRIMARY KEY (id) )''' con = connectdb() cur = con.cursor() cur.execute(sql) con.commit() con.close() def exist(cur,list): sql="SELECT * from flight where id ='{}' ".format(list[0]) logging.info("查询sql:{}".format(sql)) s = cur.execute(sql) count = cur.fetchall() if count: # 已经存在 return True else: return False def batch_insert(tow_dim_list): con = connectdb() cur = con.cursor() try: for list in tow_dim_list: if not exist(cur,list): sql = "insert into flight VALUES ('{}','{}','{}','{}','{}','{}','{}','{}')".format(list[0], list[1],list[2],list[3],list[4],list[5],list[6],list[7]) logging.info("sql:{}".format(sql)) cur.execute(sql) con.commit() except Exception as e: print("插入数据库出现异常:{}".format(str(e))) con.rollback() finally: cur.close() con.close() if __name__ == '__main__': connectdb() # -*- coding: utf-8 -*- import air_list import sqllite_opr #创建数据库 第一次运行要加上 后面可以删除 # sqllite_opr.create_table() url=input("请输入要爬取的连接:") get_air_list = air_list.get_air_list(url) sqllite_opr.batch_insert(get_air_list) print("插入完成")
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
①一般在正午坐飞机价格会比较高
②机票价格变动非常大
③北上广深的航班量比较大
④重庆到广州的机票非常便宜
⑤去往广州的飞机非常多
2.对本次程序设计任务完成的情况做一个简单的小结。
经过这次实践学习了爬虫,我明白了我还有许多地方的不足之处,还需要不断的去学习,去练习,这次设计任务
完成的不是很好,有几个地方没有攻破,就用了最笨的方法去做,但是爬虫是给人们带来方便的,我这样并没有
这么方便了,同时也没考虑到携程网这么难爬取,没有提前做好功课就去爬取,以至于几次想要放弃,所以以后
要有更加充分的时间去学习和分析问题,最主要是爬取的数据都是有点怪的数据,很难做成可视化,这点是我没有
考虑清楚的一个方面。