转载: How to Structure a Data Science Team: Key Models and Roles to Consider
Share:
If you’ve been following the direction of expert opinion in data science and predictive analytics, you’ve likely come across the resolute recommendation to embark on machine learning. As James Hodson in Harvard Business Review recommends, the smartest move is to reach for the “low hanging fruit” and then scale for expertise in heavier operations.
Just recently we talked about machine-learning-as-a-service (MLaaS) platforms. The main takeaway from the current trends is simple. Machine learning becomes more approachable for midsize and small businesses as it gradually turns into a commodity. The leading vendors – Google, Amazon, and Microsoft – provide APIs and platforms to run basic ML operations without a private infrastructure and deep data science expertise. In the early stages, taking this lean and frugal approach would be the smartest move. As analytics capabilities scale, a team structure can be reshaped to boost operational speed and extend an analytics arsenal.
How to implement this incremental approach? This time we talk about data science team structures and their complexity.
Data science team structures
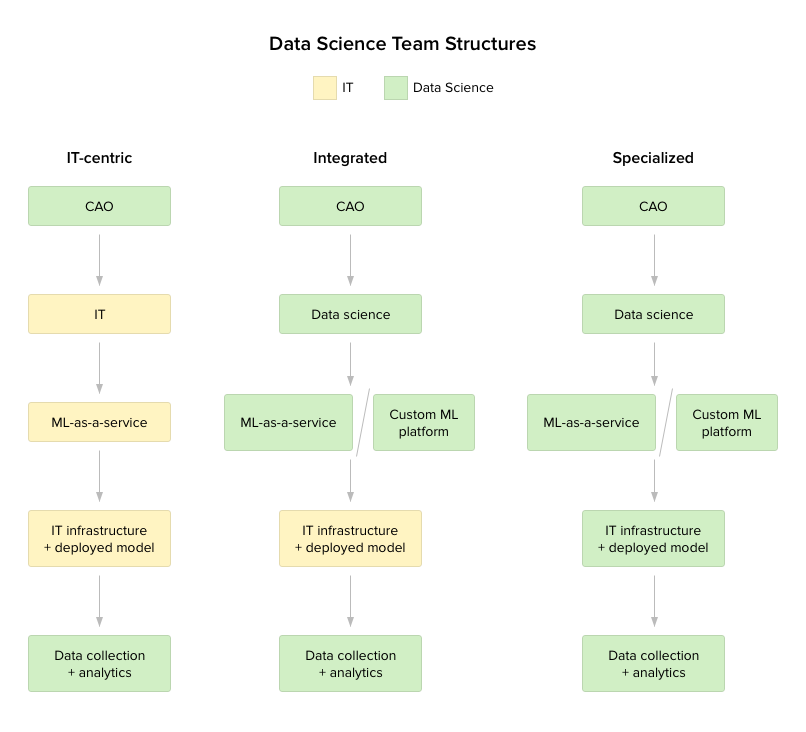
Embarking on data science and predictive analytics requires a clear understanding of how the initiative is going to be introduced, maintained, and further scaled in terms of team structure. We recommend considering three basic team structures that match different stages of machine learning adoption.
IT-centric structure
Sometimes, hiring data scientists is not an option, and you must leverage talent that’s already in-house. The main analytics and leadership role would be a “business translator,” usually referred to as a chief analytics officer (CAO) or chief data officer (CDO). The latter term gradually becomes redundant as most data processes are reshaped towards predictive analytics. This person should be capable of leading the initiative. We’ll take a more detailed look at the position below.
All the rest – data preparation, training models, creating user interfaces, and model deployment within a corporate IT infrastructure – can be largely managed by the IT department (if your organization actually has a fully functioning, in-house IT department). This approach is fairly limited, but it can be realized by using MLaaS solutions. Environments like Azure Machine Learning or Amazon Machine Learning are already equipped with approachable user interfaces to clean datasets, train models, evaluate them, and deploy.
Azure Machine Learning, for instance, supports its users with detailed documentation for a low entry threshold. This allows for fast training and early deployment of models even without an expert data scientist on board.
On the other hand, MLaaS solutions present their limitations in terms of machine learning methods and cost. All operations, from data cleaning to model evaluation, have their separate prices. And considering that the number of iterations to train an effective model can’t be estimated in advance, working with MLaaS platforms entails some budget uncertainty.
Pros of IT-centric structure:
Leverage new investments with existing IT resources
Computing infrastructure is provided and maintained by an external service
In-house specialists can be trained to further realize predictive analytics potential
Cross-silo management is reduced as all operations are held within the IT department
Less time-to-market for relatively simple machine learning tasks requiring one or a few models
Cons of IT-centric structure:
Limited machine learning methods and data cleaning procedures that these services provide
Model training, testing, and prediction should be paid for. This entails uncertainty of eventual cost per prediction as the number of needed iterations can’t be estimated in advance
Integrated structure
With the integrated structure, a data science team focuses on dataset preparation and model training, while IT specialists take charge of the interfaces and infrastructure supporting deployed models. Combining machine learning expertise with IT resource is the most viable option for constant and scalable machine learning operations.
Unlike the IT-centric approach, the integrated method requires having an experienced data scientist on a team and an elaborate recruitment effort beforehand. This ensures better operational flexibility in terms of available techniques. Besides end-to-end and yet limited services, you can leverage deeper machine learning tools and libraries – like Tensor Flow or Theano – that are designed for researchers and experts with data science backgrounds. With this effort allocation, you can address highly specific business problems and choose between as-a-service and custom-built ML solutions.
Pros of integrated structure:
Leveraging existing IT resources and investments
Data scientists focus on innovation
Utilizing full potential of both as-a-service and custom ML applications
Start with one or two data scientists, then train and onboard more homegrown experts
Using custom model combinations (ensemble models) that yield better or broader predictions
Cons of integrated structure:
Computing infrastructure is required in case of custom ML use
Cross-silo management takes considerable effort
Significant investments into data science talent acquisition
Data science talent engagement and retention challenges
Specialized data science department
To reduce management effort and build an all-encompassing machine learning framework, you can run the entire machine learning workflow within an independent data science department. This approach entails the highest cost. All operations, from data cleaning and model training to building front-end interfaces, are realized by a dedicated data science team. It doesn’t necessarily mean that all team members should have a data science background, but they should acquire technology infrastructure and service management skills.
A specialized structure model aids in addressing complex data science tasks that include research, use of multiple ML models tailored to various aspects of decision-making, or multiple ML-backed services. In the case of large organizations, specialized data science teams can supplement different business units and operate within their specific fields of analytical interest.
Pros of specialized data science department:
Centralized data science management and increased problem-solving capacities
Realizing the full potential of both as-a-service and custom ML applications
Solving complex prediction problems that require deep research or building segmented model factories (that operate automatically across different segments and business units)
Setting a fully-featured data science playground to foster innovation
Greater scalability potential
Cons of specialized data science department:
Building and maintaining a complex computational infrastructure
Heavy investments into data science talent acquisition
Data science talent engagement and retention challenges
Regardless of what structure you opt for to start, having the right data science and analytics talent is critical. Who are the people you should look for?
Data science team roles
Let’s talk about skillsets of data scientists. Unfortunately, the term data scientist expanded and became too vague in recent years. After data science appeared in the business spotlight, there is no consensus developed regarding what the skillset of a data scientist is. Matthew Mayo, Data Scientist and the Deputy Editor of KDNuggets, argues: “When I hear the term data scientist, I tend to think of the unicorn, and all that it entails, and then remember that they don’t exist, and that actual data scientists play many diverse roles in organizations, with varying levels of business, technical, interpersonal, communication, and domain skills.”
This is true. It’s hard to find unicorns, but it’s possible to grow them from people with niche expertise in data science. We at AltexSoft consider these skills when hiring machine learning specialists:
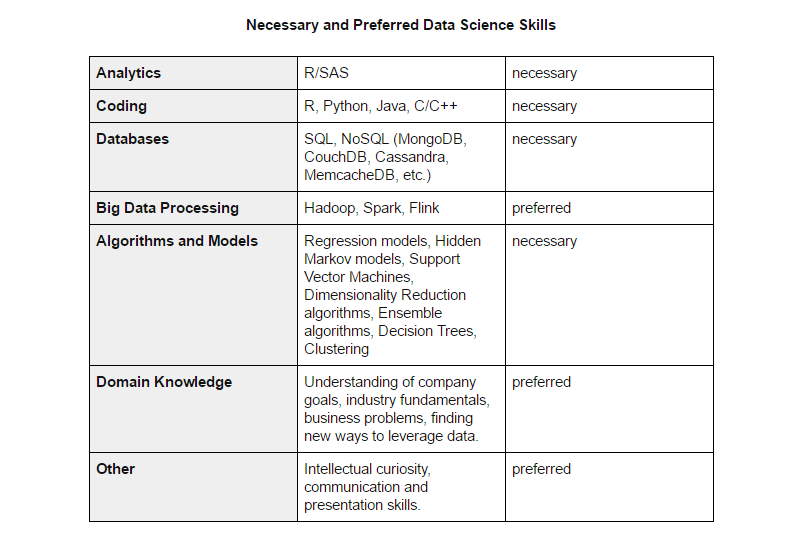
Keep in mind that even professionals with this hypothetical skillset usually have their core strengths, which should be considered when distributing roles within a team. In most cases, acquiring talents will entail further training depending on their background.
But people and their roles are two different things. For instance, if your team model is the integrated one, an individual may combine multiple roles. So, let’s disregard how many actual experts you may have and outline the roles themselves. Obviously, many skillsets across roles may intersect.
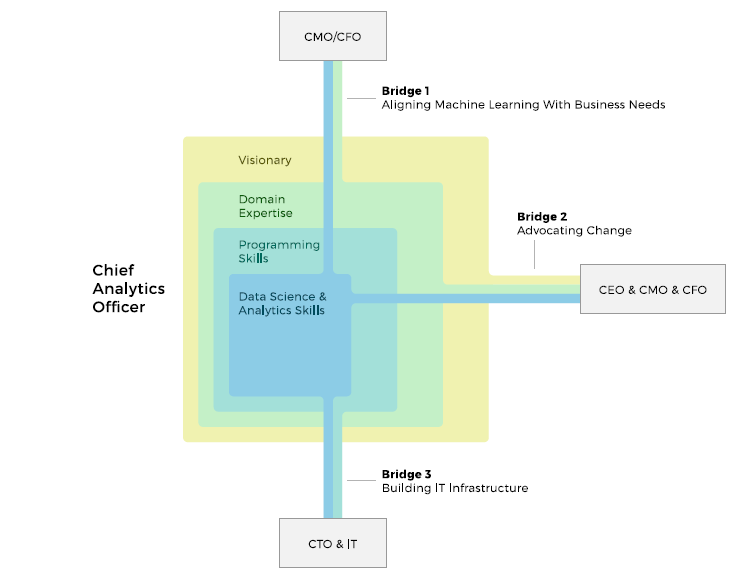
Chief Analytics Officer/Chief Data Officer. In our recent whitepaper on machine learning, we broadly discussed this key leadership role. CAO, a “business translator,” bridges the gap between data science and domain expertise acting both as a visionary and a technical lead. You may get a better idea by looking the visualization below.
Preferred skills: data science and analytics, programming skills, domain expertise, leadership and visionary abilities
Data analyst. The role implies proper data collection and interpretation activities. An analyst ensures that collected data is relevant and exhaustive while also interpreting the analytics results. Some companies, like IBM or HP, also require data analysts to have visualization skills to convert alienating numbers into tangible insights through graphics.
Preferred skills: R, Python, JavaScript, C/C++, SQL
Business analyst. A business analyst basically realizes a CAO’s functions but on the operational level. This implies converting business expectations into data analysis. If your core data scientist lacks domain expertise, a business analyst bridges this gulf.
Preferred skills: data visualization, business intelligence, SQL
Data scientist (not a data science unicorn). Assuming you aren’t hunting unicorns, a data scientist is a person who solves business tasks using machine learning and data mining techniques. If this is too fuzzy, the role can be narrowed down to data preparation and cleaning with further model training and evaluation.
Preferred skills: R, SAS, Python, Matlab, SQL, noSQL, Hive, Pig, Hadoop, Spark
Data architect. This role is critical for working with large amounts of data (you guessed it, Big Data). However, if you don’t solely rely on MLaaS cloud platforms, this role is critical to warehouse the data, define database architecture, centralize data, and ensure integrity across different sources. For large distributed systems and big datasets, the architect is also in charge of performance.
Preferred skills: SQL, noSQL, XML, Hive, Pig, Hadoop, Spark
Data engineer. Engineers implement, test, and maintain infrastructural components that data architects design. Realistically, the role of an engineer and the role of an architect can be combined in one person. The set of skills is very close.
Preferred skills: SQL, noSQL, Hive, Pig, Matlab, SAS, Python, Java, Ruby, C++, Perl
Application/data visualization engineer. Basically, this role is only necessary for a specialized data science model. In other cases, software engineers come from IT units to deliver data science results in applications that end-users face. And it’s very likely that an application engineer or other developers from front-end units will oversee end-user data visualization.
Preferred skills: programming, JavaScript (for visualization), SQL, noSQL
Team assembly and scaling
The initial challenge of talent acquisition in data science, besides the overall scarcity of experts, is the high salary expectations. According to O’Reilly Data Science Salary Survey 2016, the median annual base salary is $87,000, while in the USA the figure reaches $105,000. These numbers significantly vary depending on geography, specific technology skills, organization sizes, gender, industry, and education. If you decide to hire skilled analytics experts, the further challenges also include engagement and retention.
The intellectual curiosity in combination with the high demand challenges organizations to engage data scientists with creative and explorative projects. Due to these reasons, the IT-centric team structure – which leverages existing sources – is a promising alternative on the initial levels of machine learning adoption. Thus, engineers can acquire some analytics skills through ML-as-a-service solutions with friendly interfaces.
Another way to address the talent scarcity and budget limitations is to develop approachable machine learning platforms that would welcome new people from IT and enable further scaling. Even if no experienced data scientists can be hired, some organizations bypass this barrier by building relationships with educational institutions. In the US, there are about a dozen Ph.D. programs emphasizing data science and numerous boot camps with 12-month-or-so courses.
Critical thing to be aware of
If you ask AltexSoft’s data science experts what the current state of AI/ML across industries is, they will likely point out two main issues: 1. Business executives still need to be convinced that reasonable ROI of ML investments exists. 2. If they are convinced and understand the value proposition and market demand, they may lack technology skills and resources to make products a reality.
These barriers are mostly due to digital culture in organizations. Efficient data processes challenge C-level executives to embrace horizontal decision-making. Frontline managers with access to analytics have more operational freedom to make data-driven decisions, while top-level management oversees a strategy. This reduces management effort and eventually mitigates “gut-feeling-decision” risks. Basically, the cultural shift defines the end success of building a data-driven business. As McKinsey argues, setting a culture is probably the hardest part, while the rest is manageable.