接近一个月没写博客,6月的课程很繁忙,各种Presentation,各种考试,各种课程报告,期末考完了,写篇博客记录下之前的一个作业。
研究生期间有门课,大数据分析与决策。这门课有个作业是做个Presentation,实现基于矩阵分解的推荐算法,要求在包含超过1000万条数据的数据集上运行。
数据集
数据不难搞到,老师直接指定MovieLens数据集。MovieLens是一个含有1700万条电影评分数据的数据集,评分数据文件rating.csv里面的数据格式很简单:一个二维表,表头 userId,movieId,rating。
然后,1700多万行评分记录,整个csv文件都有几百兆,我用 vim 打开都卡了一下,用 VS Code打开更是卡的不行。
算法
算法,矩阵分解。就是把评分矩阵R(n个用户m个电影)分解成两个矩阵乘积。U矩阵是用户的特征矩阵,V矩阵是物品的特征矩阵。
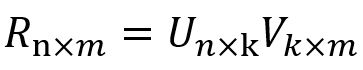
如果R矩阵里的每个评分都是已知的,那么这个矩阵分解起来就比较容易,但是现在问题是R矩阵里面大多数评分是空缺的,UV就不好分解了。这个时候可以定义一个误差函数,通过一个最优化过程来实现分解。至于预测结果,就通过UV乘积的某行某列去查就可以了。
因为之前完全没有接触过推荐算法,也没有接触过Spark,这个题目乍一看比较吓人,其实也没有多吓人。重大研究生的水平老师们都清楚,一门课而已,并非真的叫你把算法重新实现一遍,直接调库就好了。其实实现一个单机版本也没有多难,把误差函数定义好,梯度下降方法也不难写,但是考虑到:
- 评分矩阵很大很稀疏,我粗略的算了一下,直接把评分矩阵(13Wx3W)在内存里展开,需要 30GB,算上分解出来的矩阵,可能需要64G内存的电脑,远远超出32bit程序的内存限制
- 最优化的参数太多,想要收敛到最小不知道会耗费多少精力
所以直接调Spark的mllib的ALS算法,因为Spark的API不是很熟,代码也是抄的网上的:
# coding: utf-8
import sys
from os.path import join
from pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark.mllib.recommendation import ALS
reload(sys)
sys.setdefaultencoding("utf-8")
# 训练模型的时候只使用了 ratings.csv 文件
def train_model(training, num_iterations=10, rank=1, lambda_=0.01):
return ALS.train(training.rdd, iterations=num_iterations, rank=rank, lambda_=lambda_, seed=0)
def recommend_for_all(model, movies, result_path, file_out_flag=False):
def parse_recommendations(line):
res = []
for item in line[1]:
movie_name = b_movies.value[item[1]]
res.append((movie_name, float(item[2])))
return Row(user=line[0], recommendations=res)
b_movies = spark.sparkContext.broadcast(dict((int(l[0]), l[1]) for l in movies.collect()))
products_for_all_users = model.recommendProductsForUsers(10).map(parse_recommendations).toDF()
recommendation_result = products_for_all_users.repartition(1).orderBy(products_for_all_users.user).rdd \
.map(lambda l: Row(str(l.user) + "," + str(list((r[0], r[1]) for r in l.recommendations))))\
.toDF().repartition(1)
if file_out_flag: # 输出到文件
recommendation_result.write.text(result_path)
def recommend_for_users(model, movies, user_ids):
def recommend_for_one_user(model, user_id):
b_movies = spark.sparkContext.broadcast(dict((int(l[0]), l[1]) for l in movies.collect()))
recommendations = model.recommendProducts(user_id, 10)
result = []
for item in recommendations:
result.append((b_movies.value[item.product], item.rating))
print "Recommendations for user ", user_id, ": ", result
if isinstance(user_ids, list):
for user in user_ids:
recommend_for_one_user(model, user)
elif isinstance(user_ids, int):
recommend_for_one_user(model, user_ids)
def main(spark, data_path, result_path):
movies = spark.read.csv(join(data_path, "movies.csv")).rdd.map(
lambda l: Row(int(l[0]), l[1], l[2])).toDF(["movieId", "title", "genres"])
ratings = spark.read.csv(join(data_path, "ratings.csv")).rdd.map(
lambda l: Row(int(l[0]), int(l[1]), float(l[2]))).toDF(["userId", "movieId", "rating"])
all_users = ratings.select("userId").distinct()
all_movies = ratings.select("movieId").distinct()
print "Got %d ratings from %d users on %d movies." \
% (ratings.count(), all_users.count(), all_movies.count())
# 划分训练集和测试集
training, test = ratings.randomSplit([0.8, 0.2], 1)
model = train_model(training)
# 为以下所有用户作出推荐并输出到终端
#user_ids = list(u.userId for u in all_users.take(3))
#print "userIds: ", user_ids
#recommend_for_users(model, movies, user_ids)
# 为所有的用户作出推荐并输出到文件
file_out_flag = True
recommend_for_all(model, movies, result_path, file_out_flag)
import os
if __name__ == "__main__":
if len(sys.argv) == 3:
data_path = sys.argv[1] # 数据目录
result_path = sys.argv[2] # 保存结果目录
else:
print "Usage: $SPARK_HOME/bin/spark-submit --master spark://master:7077 " \
"movieLens.py /data_path/ /result/path"
sys.exit()
spark = SparkSession \
.builder \
.appName("MovieLens Recommendation") \
.getOrCreate()
real_data_path = os.environ.get('SPARK_HOME') + '/' + data_path
main(spark, real_data_path, result_path)
spark.stop()
以上程序要求机器有Python2.7,装了numpy:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy
部署
部署稍微讲究一下,因为没跑过千万级的数据,我一开始就搭建了一个Spark集群。这个Spark集群没有运行在 hdfs 上,所以我需要把数据集文件拷到每台机器上,而且文件的位置必须一模一样,不然Python脚本读文件会出错,这里我把数据集放到了Spark目录下面(通过环境变量拿路径)。
关于Spark环境的搭建,因为我没有上Hadoop,使用的也是默认的集群管理器,所以环境搭建很简单。先确保Java环境搭好,然后把Spark下载下来解压到/usr/share/spark,之后设置环境变量SPARK_HOME,把$SPARK_HOME$/bin,$SPARK_HOME$/sbin添加到PATH里就好了。
然后启动Master结点:
start-master.sh -h 0.0.0.0 -p 7077
再启动Slave结点:
start-slave.sh spark://masterIP:7077
这个时候访问 http://masterIP:8080 可以查看集群状态:

我在这里用了4台Ubuntu系统的电脑,搭了一个有23GB内存,13个核的集群。然后我在任何一台有Python脚本的电脑上用以下命令提交任务到 Master 上:
spark-submit --master spark://masterIP:7077 movieLens.py ml-20m/ result/
# movieLens.py 是代码,后面两个参数是Python的__main__()的参数。
这个配置的集群基本7分钟左右就可以在1700万条记录上跑完协同过滤算法,这个过程只能说又锻炼了一遍我配置环境的能力,看着这么大的数据在集群里这么短时间跑完还是很开心的。
