1. 分词(Word Cut)
英文:单词组成句子,单词之间由空格隔开
中文:字、词、句、段、篇
词:有意义的字组合
分词:将不同的词分隔开,将句子分解为词和标点符号
英文分词:根据空格
中文分词:三类算法
中文分词难点:歧义识别、未登录词
中文分词的好坏:歧义词识别和未登录词的识别准确率
分词工具:Jieba,SnowNLP,NlPIR,LTP,NLTK
2. 词性标注(POS Tag)
词性也称为词类或词汇类别。用于特定任务的标记的集合被称为一个标记集
词性:词类,词汇性质,词汇的语义功能,词汇的所属类别
词性取决于:1.选定的词的类别体系 2.词汇本身在语句中上下文的语法语义功能
一个词汇有多个不同的词性,词性兼类现象
词性唯一:单性词
词性多于2个:兼类词
词性标注:将单词按它们的词性分类并进行相应地标注的过程,称为词语性质标注、词性标注或简称标注。
词性标注器:一个标注器能够正确识别一个句子的上下文中的这些词的标记
词性标注方法:三类
2.1 NLTK常用词性:
CC Coordinating conjunction 连接词CD Cardinal number 基数词DT Determiner 限定词(如this,that,these,those,such,不定限定词:no,some,any,each,every,enough,either,neither,all,both,half,several,many,much,(a) few,(a) little,other,another.EX Existential there 存在句FW Foreign word 外来词IN Preposition or subordinating conjunction 介词或从属连词JJ Adjective 形容词或序数词JJR Adjective, comparative 形容词比较级JJS Adjective, superlative 形容词最高级LS List item marker 列表标示MD Modal 情态助动词NN Noun, singular or mass 常用名词 单数形式NNS Noun, plural 常用名词 复数形式NNP Proper noun, singular 专有名词,单数形式NNPS Proper noun, plural 专有名词,复数形式PDT Predeterminer 前位限定词POS Possessive ending 所有格结束词PRP Personal pronoun 人称代词PRP$ Possessive pronoun 所有格代名词RB Adverb 副词RBR Adverb, comparative 副词比较级RBS Adverb, superlative 副词最高级RP Particle 小品词SYM Symbol 符号TO to 作为介词或不定式格式UH Interjection 感叹词VB Verb, base form 动词基本形式VBD Verb, past tense 动词过去式VBG Verb, gerund or present participle 动名词和现在分词VBN Verb, past participle 过去分词VBP Verb, non-3rd person singular present 动词非第三人称单数VBZ Verb, 3rd person singular present 动词第三人称单数WDT Wh-determiner 限定词(如关系限定词:whose,which.疑问限定词:what,which,whose.)WP Wh-pronoun 代词(who whose which)WP$ Possessive wh-pronoun 所有格代词WRB Wh-adverb 疑问代词(how where when)
通用词性标记集
标记 含义 英文示例
ADJ 形容词 new, good, high, special, big, local
ADP 介词 on, of, at, with, by, into, under
ADV 副词 really, already, still, early, now
CONJ 连词 and, or, but, if, while, although
DET 限定词,冠词 the, a, some, most, every, no, which
NOUN 名词 year, home, costs, time, Africa
NUM 数词 twenty-four, fourth, 1991, 14:24
PRT 小品词 at, on, out, over per, that, up, with
PRON 代词 he, their, her, its, my, I, us
VERB 动词 is, say, told, given, playing, would
. 标点符号 . , ; !
X 其它 ersatz, esprit, dunno, gr8, univeristy
- NLTK读取已经标注的语料库:一个已标注的词符使用一个由词符和标记组成的元组来表示。str2tuple()
- 一旦我们开始做词性标注,我们将会创建分配一个标记给一个词的程序,标记是在给定上下文中最可能的标记。我们可以认为这个过程是从词到标记的映射。在Python中最自然的方式存储映射是使用所谓的字典数据类型(在其他的编程语言又称为关联数组或哈希数组)
- NLTK标记形式:(word,tag)和字典
- 将字典转换成列表:list(),sorted()
- 按值排序一个字典的习惯用法,sorted()的第一个参数是要排序的项目,它是由一个词性标记和一个频率组成的元组的列表。第二个参数使用函数itemgetter()指定排序的键。在一般情况下,itemgetter(n)返回一个函数,这个函数可以在一些其他序列对象上被调用获得这个序列的第n个元素。
from operator import itemgetter
sorted(counts.items(), key=itemgetter(1), reverse=True) - 一个词的标记依赖于这个词和它在句子中的上下文
3.自动标注
3.1默认标注器
1.最简单的标注器是为每个词符分配同样的标记。这似乎是一个相当平庸的一步,但它建立了标注器性能的一个重要的底线。为了得到最好的效果,我们用最有可能的标记标注每个词。让我们找出哪个标记是最有可能的
tags = [tag for (word, tag) in brown.tagged_words(categories='news')]
nltk.FreqDist(tags).max()
'NN'
2.创建一个将所有词都标注成NN的标注器
raw = 'I do not like green eggs and ham, I do not like them Sam I am!'
tokens = word_tokenize(raw)
default_tagger = nltk.DefaultTagger('NN')
default_tagger.tag(tokens)
[('I', 'NN'), ('do', 'NN'), ('not', 'NN'), ('like', 'NN'), ('green', 'NN'),
('eggs', 'NN'), ('and', 'NN'), ('ham', 'NN'), (',', 'NN'), ('I', 'NN'),
('do', 'NN'), ('not', 'NN'), ('like', 'NN'), ('them', 'NN'), ('Sam', 'NN'),
('I', 'NN'), ('am', 'NN'), ('!', 'NN')]
3.不出所料,这种方法的表现相当不好。在一个典型的语料库中,它只标注正确了八分之一的标识符,正如我们在这里看到的:
default_tagger.evaluate(brown_tagged_sents)
Out[13]: 0.13089484257215028
默认的标注器给每一个单独的词分配标记,即使是之前从未遇到过的词。碰巧的是,一旦我们处理了几千词的英文文本之后,大多数新词都将是名词。正如我们将看到的,这意味着,默认标注器可以帮助我们提高语言处理系统的稳定性。
3.2正则表达式标注器
正则表达式标注器基于匹配模式分配标记给词符。例如,我们可能会猜测任一以ed结尾的词都是动词过去分词,任一以's结尾的词都是名词所有格。可以用一个正则表达式的列表表示这些:
patterns = [
... (r'.ing$', 'VBG'), # gerunds
... (r'.ed$', 'VBD'), # simple past
... (r'.es$', 'VBZ'), # 3rd singular present
... (r'.ould$', 'MD'), # modals
... (r'.'s$', 'NN$'), # possessive nouns
... (r'.s$', 'NNS'), # plural nouns
... (r'^-?[0-9]+(.[0-9]+)?$', 'CD'), # cardinal numbers
... (r'.*', 'NN') # nouns (default)
... ]
请注意,这些是顺序处理的,第一个匹配上的会被使用。现在我们可以建立一个标注器,并用它来标记一个句子。做完这一步会有约五分之一是正确的。
regexp_tagger.evaluate(brown_tagged_sents)
Out[21]: 0.20326391789486245
3.3查询标注器
3.4N-gram标注
- 一元标注器基于一个简单的统计算法:对每个标识符分配这个独特的标识符最有可能的标记。例如,它将分配标记JJ给词frequent的所有出现,因为frequent用作一个形容词(例如a frequent word)比用作一个动词(例如I frequent this cafe)更常见。一个一元标注器的行为就像一个查找标注器(4),除了有一个更方便的建立它的技术,称为训练。
-
一个n-gram tagger标注器是一个一元标注器的一般化,它的上下文是当前词和它前面n-1个标识符的词性标记
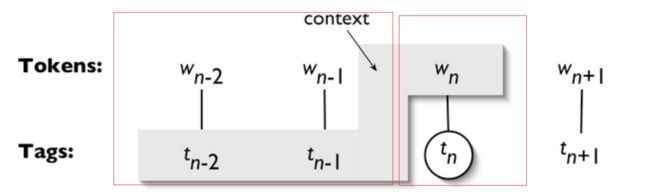
- 1-gram标注器是一元标注器另一个名称:即用于标注一个词符的上下文的只是词符本身。2-gram标注器也称为二元标注器,3-gram标注器也称为三元标注器。
5.组合标注器
尝试使用二元标注器标注标识符。
如果二元标注器无法找到一个标记,尝试一元标注器。
如果一元标注器也无法找到一个标记,使用默认标注器。
- 大多数NLTK标注器允许指定一个回退标注器。回退标注器自身可能也有一个回退标注器:
t0 = nltk.DefaultTagger('NN')
t1 = nltk.UnigramTagger(train_sents, backoff=t0)
t2 = nltk.BigramTagger(train_sents, backoff=t1)
t2.evaluate(test_sents)
0.844513...
4.文本分类
4.1 词类分类
- 在一般情况下,语言学家使用形态学、句法和语义线索确定一个词的类别
- 形态学线索
一个词的内部结构可能为这个词分类提供有用的线索。举例来说:-ness是一个后缀,与形容词结合产生一个名词,如happy → happiness, ill → illness。如果我们遇到的一个以-ness结尾的词,很可能是一个名词。同样的,-ment是与一些动词结合产生一个名词的后缀,如govern → government和establish → establishment。
英语动词也可以是形态复杂的。例如,一个动词的现在分词以-ing结尾,表示正在进行的还没有结束的行动(如falling, eating)。-ing后缀也出现在从动词派生的名词中,如the falling of the leaves(这被称为动名词)。- 句法线索
另一个信息来源是一个词可能出现的典型的上下文语境。例如,假设我们已经确定了名词类。那么我们可以说,英语形容词的句法标准是它可以立即出现在一个名词前,或紧跟在词be或very后。根据这些测试,near应该被归类为形容词:
s(2)
a. the near window
b. The end is (very) near.- 语义线索
最后,一个词的意思对其词汇范畴是一个有用的线索。
4.2 有监督分类
- 分类是为给定的输入选择正确的类标签的任务。在基本的分类任务中,每个输入被认为是与所有其它输入隔离的,并且标签集是预先定义的。这里是分类任务的一些例子:
判断一封电子邮件是否是垃圾邮件。
从一个固定的主题领域列表中,如“体育”、“技术”和“政治”,决定新闻报道的主题是什么。
决定词bank给定的出现是用来指河的坡岸、一个金融机构、向一边倾斜的动作还是在金融机构里的存储行为。
 有监督分类框架
有监督分类框架
(a)在训练过程中,特征提取器用来将每一个输入值转换为特征集。这些特征集捕捉每个输入中应被用于对其分类的基本信息,我们将在下一节中讨论它。特征集与标签的配对被送入机器学习算法,生成模型。(b)在预测过程中,相同的特征提取器被用来将未见过的输入转换为特征集。之后,这些特征集被送入模型产生预测标签。
4.2.1 性别鉴定
- 男性和女性的名字有一些鲜明的特点。以a,e和i结尾的很可能是女性,而以k,o,r,s和t结尾的很可能是男性。
创建一个分类器的第一步是决定输入的什么样的特征是相关的,以及如何为那些特征编码。
- 特征提取函数
def gender_features(word):
... return {'last_letter': word[-1]}
这个函数返回的字典被称为特征集,映射特征名称到它们的值。特征名称是区分大小写的字符串,通常提供一个简短的人可读的特征描述,例如本例中的'last_letter'。特征值是简单类型的值,如布尔、数字和字符串。
- 准备数据(一个例子和对应类标签的列表)
from nltk.corpus import names
labeled_names = ([(name, 'male') for name in names.words('male.txt')] +
... [(name, 'female') for name in names.words('female.txt')])
import random
random.shuffle(labeled_names)
- 使用特征提取器处理names数据,并划分特征集的结果链表为一个训练集和一个测试集。训练集用于训练一个新的“朴素贝叶斯”分类器。
featuresets = [(gender_features(n), gender) for (n, gender) in labeled_names]
train_set, test_set = featuresets[500:], featuresets[:500]
classifier = nltk.NaiveBayesClassifier.train(train_set)
- 测试
classifier.classify(gender_features('Neo'))
'male'
classifier.classify(gender_features('Trinity'))
'female'
- 准确度
print(nltk.classify.accuracy(classifier, test_set))
- 检查分类器,确定哪些特征对于区分名字的性别是最有效的
classifier.show_most_informative_features(5)
Most Informative Features
last_letter = 'a' female : male = 33.2 : 1.0
last_letter = 'k' male : female = 32.6 : 1.0
last_letter = 'p' male : female = 19.7 : 1.0
last_letter = 'v' male : female = 18.6 : 1.0
last_letter = 'f' male : female = 17.3 : 1.0
4.2.2选择正确的特征
def gender_features2(name):
features = {}
features["first_letter"] = name[0].lower()
features["last_letter"] = name[-1].lower()
for letter in 'abcdefghijklmnopqrstuvwxyz':
features["count({})".format(letter)] = name.lower().count(letter)
features["has({})".format(letter)] = (letter in name.lower())
return features
gender_features2('John')
{'count(j)': 1, 'has(d)': False, 'count(b)': 0, ...}
- 然而,你要用于一个给定的学习算法的特征的数目是有限的——如果你提供太多的特征,那么该算法将高度依赖你的训练数据的特性,而一般化到新的例子的效果不会很好。这个问题被称为过拟合,当运作在小训练集上时尤其会有问题。
- 一旦初始特征集被选定,完善特征集的一个非常有成效的方法是错误分析。首先,我们选择一个开发集,包含用于创建模型的语料数据。然后将这种开发集分为训练集和开发测试集。
-
训练集用于训练模型,开发测试集用于进行错误分析。测试集用于系统的最终评估。
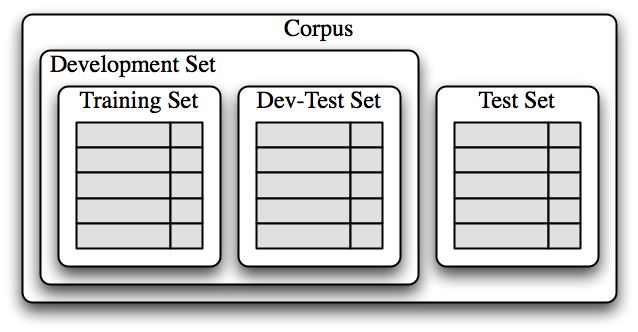 用于训练有监督分类器的语料数据组织图。语料数据分为两类:开发集和测试集。开发集通常被进一步分为训练集和开发测试集。
用于训练有监督分类器的语料数据组织图。语料数据分为两类:开发集和测试集。开发集通常被进一步分为训练集和开发测试集。 - 使用开发测试集,我们可以生成一个分类器预测名字性别时的错误列表
errors = []
for (name, tag) in devtest_names:
guess = classifier.classify(gender_features(name))
if guess != tag:
errors.append( (tag, guess, name) )
for (tag, guess, name) in sorted(errors):
... print('correct={:<8} guess={:<8s} name={:<30}'.format(tag, guess, name))
- 浏览这个错误列表,它明确指出一些多个字母的后缀可以指示名字性别。例如,yn结尾的名字显示以女性为主,尽管事实上,n结尾的名字往往是男性;以ch结尾的名字通常是男性,尽管以h结尾的名字倾向于是女性。因此,调整我们的特征提取器包括两个字母后缀的特征:
train_set = [(gender_features(n), gender) for (n, gender) in train_names]
devtest_set = [(gender_features(n), gender) for (n, gender) in devtest_names]
classifier = nltk.NaiveBayesClassifier.train(train_set)
print(nltk.classify.accuracy(classifier, devtest_set))
- 这个错误分析过程可以不断重复,检查存在于由新改进的分类器产生的错误中的模式。每一次错误分析过程被重复,我们应该选择一个不同的开发测试/训练分割,以确保该分类器不会开始反映开发测试集的特质。
4.3词性标注
- 训练一个分类器来算出哪个后缀最有信息量
- 定义一个特征提取器函数,检查给定的单词的这些后缀
- 训练一个新的“决策树”的分类器
- 决策树模型的一个很好的性质是它们往往很容易解释——我们甚至可以指示NLTK将它们以伪代码形式输出s
4.4探索上下文语境
通过增加特征提取函数,我们可以修改这个词性标注器来利用各种词内部的其他特征,例如词长、它所包含的音节数或者它的前缀。然而,只要特征提取器仅仅看着目标词,我们就没法添加依赖词出现的上下文语境特征。然而上下文语境特征往往提供关于正确标记的强大线索——例如,标注词"fly",如果知道它前面的词是“a”将使我们能够确定它是一个名词,而不是一个动词。
为了采取基于词的上下文的特征,我们必须修改以前为我们的特征提取器定义的模式。不是只传递已标注的词,我们将传递整个(未标注的)句子,以及目标词的索引。

- 很显然,利用上下文特征提高了我们的词性标注器的准确性。
4.5序列分类
- 一种序列分类器策略,称为连续分类或贪婪序列分类,是为第一个输入找到最有可能的类标签,然后使用这个问题的答案帮助找到下一个输入的最佳的标签。
- 首先,我们必须扩展我们的特征提取函数使其具有参数history,它提供一个我们到目前为止已经为句子预测的标记的列表
。history中的每个标记对应sentence中的一个词。但是请注意,history将只包含我们已经归类的词的标记,也就是目标词左侧的词。因此,虽然是有可能查看目标词右边的词的某些特征,但查看那些词的标记是不可能的(因为我们还未产生它们)。
 [1]
[1]
4.6 其他有监督分类例子
4.6.1句子分割
- 句子分割可以看作是一个标点符号的分类任务:每当我们遇到一个可能会结束一个句子的符号,如句号或问号,我们必须决定它是否终止了当前句子。
- 第一步是获得一些已被分割成句子的数据,将它转换成一种适合提取特征的形式
sents = nltk.corpus.treebank_raw.sents()
>>> tokens = []
>>> boundaries = set()
>>> offset = 0
>>> for sent in sents:
... tokens.extend(sent)
... offset += len(sent)
... boundaries.add(offset-1)
tokens是单独句子标识符的合并列表,boundaries是一个包含所有句子边界词符索引的集合。
- 下一步,我们需要指定用于决定标点是否表示句子边界的数据特征
def punct_features(tokens, i):
... return {'next-word-capitalized': tokens[i+1][0].isupper(),
... 'prev-word': tokens[i-1].lower(),
... 'punct': tokens[i],
... 'prev-word-is-one-char': len(tokens[i-1]) == 1}
- 基于这一特征提取器,我们可以通过选择所有的标点符号创建一个加标签的特征集的列表,然后标注它们是否是边界标识符
featuresets = [(punct_features(tokens, i), (i in boundaries))
... for i in range(1, len(tokens)-1)
... if tokens[i] in '.?!']
- 训练并评估
>>> size = int(len(featuresets) * 0.1)
>>> train_set, test_set = featuresets[size:], featuresets[:size]
>>> classifier = nltk.NaiveBayesClassifier.train(train_set)
>>> nltk.classify.accuracy(classifier, test_set)
0.936026936026936
4.6.2识别对话行为类型
- 处理对话时,将对话看作说话者执行的行为是很有用的。对于表述行为的陈述句这种解释是最直白的,例如"I forgive you"或"I bet you can't climb that hill"。但是问候、问题、回答、断言和说明都可以被认为是基于语言的行为类型。识别对话中言语下的对话行为是理解谈话的重要的第一步。
- 可以利用这些数据建立一个分类器,识别新的即时消息帖子的对话行为类型。第一步是提取基本的消息数据。
- 下一步,我们将定义一个简单的特征提取器,检查帖子包含什么词
- 最后,我们通过为每个帖子提取特征(使用post.get('class')获得一个帖子的对话行为类型)构造训练和测试数据,并创建一个新的分类器
4.6.3识别文字蕴含
识别文字蕴含(RTE)是判断文本T的一个给定片段是否蕴含着另一个叫做“假设”的文本
迄今为止,已经有4个RTE挑战赛,在那里共享的开发和测试数据会提供给参赛队伍。这里是挑战赛3开发数据集中的文本/假设对的两个例子。标签True表示蕴含成立,False表示蕴含不成立。
5.评估
5.1测试集
5.2准确度
5.3召回率和F值
5.4混淆矩阵
5.5交叉验证
6.从文本提取信息
6.1信息提取
- 从文本获取意义的方法被称为信息提取
6.1.1信息提取的架构

6.1.2词块划分
-
用于实体识别的基本技术是词块划分,它分割和标注多词符的序列。小框显示词级分词和词性标注,大框显示高级别的词块划分。每个这种较大的框叫做一个词块。就像分词忽略空白符,词块划分通常选择词符的一个子集。同样像分词一样,词块划分器生成的片段在源文本中不能重叠。
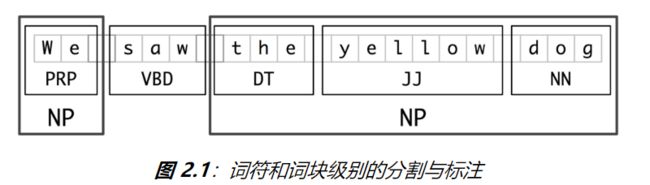
名词短语词块划分
- 首先思考名词短语词块划分或NP词块划分任务,在那里我们寻找单独名词短语对应的词块
-
词块信息最有用的来源之一是词性标记。这是在我们的信息提取系统中进行词性标注的动机之一。为了创建一个词块划分器,我们将首先定义一个词块语法,由指示句子应如何进行词块划分的规则组成。

标记模式
- 组成一个词块语法的规则使用标记模式来描述已标注的词的序列。一个标记模式是一个词性标记序列,用尖括号分隔,如
- ?
* 。 - ?
用正则表达式进行词块划分
-
要找到一个给定的句子的词块结构,RegexpParser词块划分器以一个没有词符被划分的平面结构开始。词块划分规则轮流应用,依次更新词块结构。一旦所有的规则都被调用,返回生成的词块结构。

探索文本语料库
7.分析句子结构
《python自然语言处理》各章总结:
1. 语言处理与Python

2. 获得文本语料和词汇资源

3. 处理原始文本

4. 编写结构化的程序

5. 分类和词汇标注

6. 学习分类文本

7. 从文本提取信息

8. 分析句子结构
9. 构建基于特征的文法
10. 分析句子的含义
11. 语言学数据管理
未完待续......