建议安装scitools套装的understand对源码进行阅读。可以对整个工程的代码进行解析后以整个工程都可以快速地jump to definition。以及可以对整体代码进行更近一步的解析。反正无比好用,墙裂推荐。
Overview

我们今天主要讲一下layers的源码
layers

我们发现每一种layer都分成.cpp和.cu两种。其实很好理解,.cpp的是cpu版本的,.cu是cuda版本的。
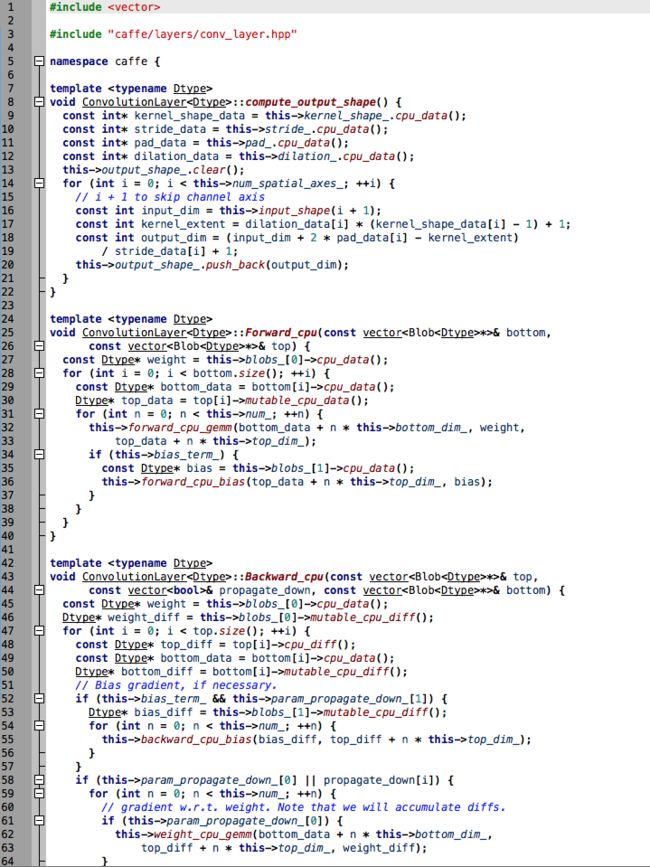

我们先来看看INSTANTIATE_CLASS(ConvolutionLayer);这个宏操作干了什么

简要介绍一下这个宏操作涉及的##(concatenate)和template specialization.
宏操作##
简单来说就是把signal的字符链接起来
举个例子
#define cat(a, b) a##b
辣么
printf("%d\n", cat(a,1));
就等价于
printf("%d\n", a1);
template instantiation
我们使用template的时候实际上是implicitly实例化了template的一个class,然而我们也有explicit version.
类似于
template class SampleClass;
注意区别于template specialization.(模板类/函数特化是定义在规定了特定typename的template的定义)
好吧其实这些都没什么卵用。我们其实更在乎Forward和Backward。
总所周知,CNN主要有一个end to end的过程,遵循bp网络的定义,有forward也有backward。我们来简单看看这个forward和backward的过程应该怎么写
CPU version
forward

计算forward的被分成了两个部分。实际上就是
o = w*i + b
第一部分的w*i对应的就是
this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_,
weight, top_data + n * this->top_dim_);
第二部分(bias)对应的就是
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + n * this->top_dim_, bias);
}
出于好奇我们再进一步看看这两个函数是怎么做的

首先介绍一下什么是im2col
http://www.zhihu.com/question/28385679
相当于把运算分解成两部,首先第一步把矩阵变成一个一个的col,然后再相乘。特别的当矩阵是1x1的时候或者需要skip im2col的时候(后面一个什么鬼我还不太清楚,总之一般情况下先理解第一个)不需要im2col(废话)。
为什么要这么做呢?
相当于卷积被分解成了
o = col2im(w*im2col(i)) + b)
为什么要这么做呢?
好求导啊!
可以参考
http://zhangliliang.com/2015/02/11/about-caffe-code-convolutional-layer/
(啥时候才能赶上人家的水平。。。。
至于细节部分,我想讲讲我在阅读中有困难的地方,那就是维数的问题。在conv_layer.cpp部分中,其实只是用到了batch_size那一个维度以及之前和多少个前面的层连接。没有涉及到后面三维ChannelxWeightxHeight。
而在后面的部分,使用了im2col把WxH两个维度压成一个维度V, 于是就有了CxV的一个矩阵。convolution网络层的参数大小是C_bottom(上一层channel数)xC_top(输出channel数),正好对应一个矩阵乘法。
接下来forward部分的代码属于很好理解但是文字不好表述的部分(各种offset以及矩阵乘法函数的各种参数等等)。所以就不赘述了。
backward

结构和forward类似。由于backward的原因应该考虑top的size。

有了上面所说的,其实这一步也是通过im2col把卷积变成全连接层的形式,类似于普通o=ai+b进行求导。
GPU version
外层的套路和CPU version几乎是一样的



Titan X 3000多个核心呢。。。。快得飞起来,一般Caffe的网络GPU都是CPU的30倍左右。