不仅会下围棋,还自学成才横扫国际象棋和日本将棋的DeepMind AlphaZero, 在2018年的最后一个月, AlphaGo Zero登上了世界顶级学术期刊《科学》杂志的封面。
从2016年AlphaGo论文发表在《自然》上,到今天AlphaZero登上《科学》,Alpha家族除了最新出炉的AlphaFold之外,AlphaGo、AlphaGo Zero和AlphaZero已经全部在顶级期刊Nature和Science上亮相。

Google设计了AlphaGo(围棋机器人)的事早已经家喻户晓了,都9102年了,它怎么又出现了?
迄今为止,AlphaGo一共有四个版本:AlphaGo Fan、AlphaGo Lee、AlphaGo Master和AlphaGo Zero。
2016年,AlphaGo Fan以5比0的战绩战胜了欧洲围棋冠军樊麾后,登上了国际学术期刊《自然》的封面,成功引起了人类的注意。

紧接着AlphaGo Lee又以4比1的比分战胜了围棋世界冠军、职业九段棋手李世石,成为了世界上第一个战胜围棋世界冠军的人工智能机器人。
愈战愈勇的AlphaGo又以“AlphaGo Master”的身份与中日韩数十位围棋高手进行快棋对决,创造了连续60局全胜的战绩,甚至连人类排名第一的棋手柯洁也被打成3比0。
不得不说,AlphaGo的势头的确挺猛的,仅一年的时间,就战胜了大量的世界顶尖的围棋高手,甚至还引发了“机器人打败人类开始占领地球”的言论。
不过“Fan、Lee和Master”看起来是人工智能,实际上却是“人工智障”。
因为它们在比赛前就会从对手的棋局里进行全方位的学习,比如说:在任意一步时,它们就会把下一步所有可能性都罗列出来,然后一步步往后推,然后选取胜率最高的方法。
说来也搞笑,谁能想到一群围棋精英会输给一个连围棋规则都不懂的机器人呢?所以说,AlphaGo只能打有准备的仗,让它临场发挥的话,可能它连我都下不赢,更别提它能“占领地球”了。
直到2017年10月19,Deepmind(谷歌下属公司)在国际学术期刊《自然》上发表的一篇研究论文中就提到了AlphaGo的全新版本——AlphaGo Zero。

AlphaGo Zero与前三代的最大不同是,它能从空白状态学起,在无任何人类输入的条件下,它能够迅速自学围棋。
也就是说,这次AlphaGo Zero是真的自己学会了围棋规则,系统学会渐渐从输、赢以及平局里面调整参数,让自己更懂得选择那些有利于赢下比赛的走法,而不再去分析对手的特征了。
都说新官上任三把火,AlphaGo Zero仅经过了3天的训练(自学),就以100比0的绝对优势战胜了AlphaGo Lee;经过40天训练后又把AlphaGo Master给秒杀了。
高呼着“抛弃人类经验”和“自我训练”问世的AlphaGo Zero的本领当然不只是欺负“老人家”啦,它强大的reinforcement learning(强化学习的算法)可以让它轻松的掌握国际象棋、日本将棋和中国围棋,而且每项都能当世界第一。
训练2个小时,AlphaZero就碾压了日本将棋世界冠军程序Elmo;
训练4个小时,AlphaZero就战胜了国际象棋世界冠军程序Stockfish。
其中,由于AlphaGo Zero的机制从“知己知彼”变成了“百战百胜”,它下棋能力也出现相应的成长式变化,而不是一味的获胜。话不多说,直接看一组数据:
AlphaGo Zero在挑战国际象棋世界冠军Stockfish时,1000场输了155场;
在挑战日本将棋世界冠军Elmo时,胜率为91.2%;
在挑战AlphaGo的前三代时,胜率仅有61%。
那为什么AlphaGo Zero不选择和人类一较高下,而是和机器人打起了内战?
因为早在AlphaGo把人类精英棋手虐一遍之后,就宣布不再参与任何人机之间的下棋比赛,典型的装完逼就跑。
其实机器人也是不忍心了,因为早在1997年5月,人类棋手就已经被机器人血虐了——超级计算机“深蓝”打败了国际象棋棋王,世界冠军卡斯帕罗夫,这件事轰动了整个世界。

虽然觉得AlphaGo Zero已经有了质的突变,但还是有不少人怀疑它的真实性和可行性。
直到2018年12月,AlphaGo Zero登上世界顶级学术期刊《科学》杂志封面后,《科学》杂志官方为其正名:“能够解决多个复杂问题的单一算法,是创建通用机器学习系统,解决实际问题的重要一步。”
那AlphaGo Zero到底是凭什么用短短一年时间从“知己知彼”变成“百战百胜”的呢?
首先,AlphaGo Zero做了一个全新的定位:重在学习,而不是急于求胜。
Deepmind采用了5000个TPU(可以简单的理解为电脑的CPU),再结合深度神经网络、通用强化学习算法和通用树搜索算法来打造了一个全能棋手。
AlphaGo Zero的学习能力也是一个动态成长的过程,每次学习一种新的棋类或者游戏都会根据难易程度来展开一段自我博弈,产生的超参数再通过贝叶斯优化进行调整。
与此同时,AlphaGo Zero的“自学”过程还有一项特别重要的任务——对自身进行神经网络训练。
训练好的神经网络,可以精准地指引一个搜索算法,就是蒙特卡洛树搜索 (MCTS) ,为每一步棋选出最有利的落子位置。每下一步之前,AlphaGo Zero的搜索对象不是所有可能性,而只是最合适当下“战况”的一小部分可能性,这就大大提升了精确性和效率性。
关于神经网络的优势,Deepmind在论文中也例举了例子。
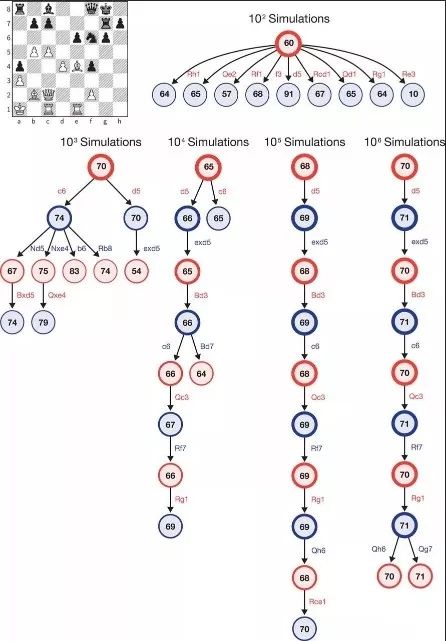
上图展示的是在AlphaGo Zero执白、Stockfish执黑的一局国际象棋里,经过100次、1000次……直到100万次模拟之后,AlphaZero蒙特卡洛树的内部状态。每个树状图解都展示了10个最常访问的状态。
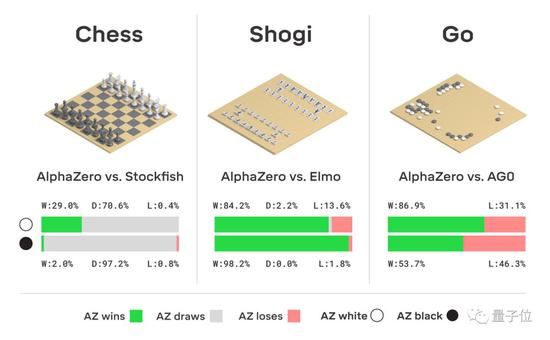
经过全面训练的系统,就和各个领域里的最强AI比一比:国际象棋的Stockfish,将棋的Elmo,以及围棋的前辈AlphaGo Zero。
每位参赛选手都是用它最初设计中针对的硬件来跑的:
Stockfish和Elmo都是用44个CPU核;AlphaZero和AlphaGo Zero用的都是一台搭载4枚初代TPU和44个CPU核的机器。(一枚初代TPU的推理速度,大约相当于一个英伟达Titan V GPU。)另外,每场比赛的时长控制在3小时以内,每一步棋不得超过15秒。比赛结果是,无论国际象棋、将棋还是围棋,AlphaGo都击败了对手:
国际象棋,大比分击败2016 TCEC冠军Stockfish,千场只输155场。
将棋,大比分击败2017 CSA世界冠军Elmo,胜率91.2%。
围棋,击败自学成才的前辈AlphaGo Zero,胜率61%。
因为AlphaZero自己学习了每种棋类,于是,它并不受人类现有套路的影响,产生了独特的、非传统的、但具有创造力和动态的棋路。
在国际象棋里,它还发展出自己的直觉和策略,增加了一系列令人兴奋的新想法,改变了几个世纪以来对国际象棋战略的思考。
不怕机器人会下棋,就怕机器人产生意识和情感。
其实对于AlphaGo Zero的人工智能性质,棋手们最大的感受就是:这个家伙不按套路出牌。因为AlphaGo Zero自己学习了每种棋类,所以它并不受人类现有套路的影响,产生了独特的、且富有创造力和动态的棋风。
国际象棋世界冠军卡斯帕罗夫也在《科学》上撰文表示:“AlphaGo Zero的棋风跟我一样,具备动态、开放的风格。” 就像我一样”。他指出通常国际象棋程序会追求平局,但AlphaZero看起来更喜欢风险、更具侵略性。卡斯帕罗夫表示,AlphaZero的棋风可能更接近本源。
卡斯帕罗夫说,AlphaZero以一种深刻而有用的方式超越了人类。

国际象棋大师马修·萨德勒(Matthew Sadler)和女性国际大师娜塔莎·里根(Natasha Regan)即将于2019年1月出版新书《棋类变革者(Game Changer)》,在这本书中,他们分析了数以千计的AlphaZero棋谱,认为AlphaZero的棋路不像任何传统的国际象棋引擎,马修·萨德勒评价它为“就像以前翻看一些厉害棋手的秘密笔记本。”
棋手们觉得,AlphaZero玩这些游戏的风格最迷人。
国际象棋特级大师马修·萨德勒说:“它的棋子带着目的和控制力包围对手的王的方式”,最大限度地提高了自身棋子的活动性和移动性,同时最大限度地减少了对手棋子的活动和移动性。
与直觉相反,AlphaZero似乎对“材料”的重视程度较低,这一想法是现代游戏的基础,每一个棋子都具有价值,如果玩家在棋盘上的某个棋子价值高于另一个,那么它就具有物质优势。AlphaZero愿意在游戏早期牺牲棋子,以获得长期收益。
“令人印象深刻的是,它设法将自己的风格强加于各种各样的位置和空缺,”马修说他也观察到,AlphaZero以非常刻意的方式发挥作用,一开始就以“非常人性化的坚定目标”开始。
“传统引擎非常强大,几乎不会出现明显错误,但在面对没有具体和可计算解决方案的位置时,会发生偏差,”他说。 “正是在这样的位置,AlphaZero才能体现出‘感觉’,‘洞察’或‘直觉’。”

这种独特的能力,在其他传统的国际象棋程序中看不到,并且已经给最近举办的世界国际象棋锦标赛提供了新的见解和评论。
“看看AlphaZero的分析与顶级国际象棋引擎甚至顶级大师级棋手的分析有何不同,这真是令人着迷,”女棋手娜塔莎·里根说。 “AlphaZero可以成为整个国际象棋圈强大的教学工具。”
AlphaZero的教育意义,早在2016年AlphaGo对战李世石时就已经看到。
在比赛期间,AlphaGo发挥出了许多极具创造性的胜利步法,包括在第二场比赛中的37步,这推翻了之前数百年的思考。这种下法以及其他许多下法,已经被包括李世石本人在内的所有级别的棋手研究过。
他对第37步这样评价:“我曾认为AlphaGo是基于概率计算的,它只是一台机器。但当我看到这一举动时,我改变了想法。当然AlphaGo是有创造性的。“

不仅仅是棋手
DeepMind在博客中说AlphaZero不仅仅是国际象棋、将棋或围棋。它是为了创建能够解决各种现实问题的智能系统,它需要灵活适应新的状况。
这正是AI研究中的一项重大挑战:系统能够以非常高的标准掌握特定技能,但在略微修改任务后往往会失败。
AlphaZero现在能够掌握三种不同的复杂游戏,并可能掌握任何完美信息游戏,解决了以上问题中重要的一步。
他们认为,AlphaZero的创造性见解,加上DeepMind在AlphaFold等其他项目中看到的令人鼓舞的结果,带来了创建通用学习系统的信心,有助于找到一些新的解决方案,去解决最重要和最复杂的科学问题。
DeepMind的Alpha家族从最初的围棋算法AlphaGo,几经进化,形成了一个家族。
刚刚提到的AlphaFold,最近可以说关注度爆表。
它能根据基因序列来预测蛋白质的3D结构,还在有“蛋白质结构预测奥运会”之称的CASP比赛中夺冠,力压其他97个参赛者。这是“证明人工智能研究驱动、加速科学进展重要里程碑”,DeepMInd CEO哈萨比斯形容为“灯塔”。
AlphaZero论文
这篇刊载在《科学》上的论文,题为:A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
作者包括:
David Silver、Thomas Hubert、Julian Schrittwieser、Ioannis Antonoglou、Matthew Lai、Arthur Guez、Marc Lanctot、Laurent Sifre、Dharshan Kumaran、Thore Graepel、Timothy Lillicrap、Karen Simonyan、Demis Hassabis。
《科学》刊载的论文在此,棋局可以在此下载,DeepMind还特别写了一个博客,传送门