自行整理, 学习用途, 侵知删歉
一.术语介绍
来源http://gluster.readthedocs.io/en/latest/Quick-Start-Guide/Terminologies/
Access Control Lists(ACL)
ACL负责给不同组, 不同用户权限.
Access Control Lists (ACLs) allows you to assign different permissions for different users or groups even though they do not correspond to the original owner or the owning group.
Brick
存储的最基本单元, 表示为储存池(Storage pool)中某台服务器上的一个目录
Brick is the basic unit of storage, represented by an export directory on a server in the trusted storage pool.
Cluster
一组电脑
A cluster is a group of linked computers, working together closely thus in many respects forming a single computer.
Distributed FIle System
一种使多部电脑通过网络并行获取数据的文件系统
A file system that allows multiple clients to concurrently access data over a computer network
FUSE(Filesystem in Userspace)
一种帮助非权限用户不必修改内核就可以创造文件系统的核心模块, 应用在Unix操作系统中;
该模块的实现是通过在用户空间运行文件系统代码, FUSE提供一种"桥"将这部分运行的代码与实际的核心接口连接起来.
Filesystem in Userspace (FUSE) is a loadable kernel module for Unix-like computer operating systems that lets non-privileged users create their own file systems without editing kernel code. This is achieved by running file system code in user space while the FUSE module provides only a "bridge" to the actual kernel interfaces.
glusterd
需要在储存池(storage pool)的所有服务器上运行的gluster管理守护进程
Gluster management daemon that needs to run on all servers in the trusted storage pool.
Geo-Replication
Geo-Replication提供了一种通过网络(LAN,WAN,Internet)持续地,异步地,增加的复制备份服务.
Geo-replication provides a continuous, asynchronous, and incremental replication service from site to another over Local Area Networks (LANs), Wide Area Network (WANs), and across the Internet.
Metadata
Metadata是关于一个或者多个数据的信息文件. GlusterFS中没有Metadata, 在文件数据中有各自的Metadata
Metadata is defined as data providing information about one or more other pieces of data. There is no special metadata storage concept in GlusterFS. The metadata is stored with the file data itself.
Namespace
Namespace是一种包含了标识,符号组的一种抽象包含概念.每一个Gluster volume有一个单独的namespace作为一个POSIX挂载指针(包含了每一个集群内的文件)
Namespace is an abstract container or environment created to hold a logical grouping of unique identifiers or symbols. Each Gluster volume exposes a single namespace as a POSIX mount point that contains every file in the cluster.
POSIX(portable operating system interface[for unix])
由IEEE定义的一种Unix接口规范
Portable Operating System Interface [for Unix] is the name of a family of related standards specified by the IEEE to define the application programming interface (API), along with shell and utilities interfaces for software compatible with variants of the Unix operating system. Gluster exports a fully POSIX compliant file system.
RAID
将复数个硬盘组合为一个虚拟单元的方式, 使得数据可靠性提高,硬盘之间也互相依存.
Redundant Array of Inexpensive Disks (RAID) is a technology that provides increased storage reliability through redundancy, combining multiple low-cost, less-reliable disk drives components into a logical unit where all drives in the array are interdependent.
RRDNS(round robin domain name service)
一种在服务器间分发数据的方式
Round Robin Domain Name Service (RRDNS) is a method to distribute load across application servers. It is implemented by creating multiple A records with the same name and different IP addresses in the zone file of a DNS server.
Trusted storage pool
存储服务器的网络;
A storage pool is a trusted network of storage servers. When you start the first server, the storage pool consists of that server alone.
Userspace
用户空间内的应用并不会直接和硬件交互, 核心对应用的权限进行了限制.但是用户空间内的应用比在核心中运行的程序更轻便. Gluster是一个用户空间的应用.
Applications running in user space don’t directly interact with hardware, instead using the kernel to moderate access. Userspace applications are generally more portable than applications in kernel space. Gluster is a user space application.
Volume
一个volume卷, 是bricks的逻辑集合. 几乎所有的gluster管理操作都是在volume上进行的
A volume is a logical collection of bricks. Most of the gluster management operations happen on the volume.
Vol file
gluster进程使用到的配置文件. Volfile一般位于/var/lib/glusterd/vols/volume-name/. Eg:vol-name-fuse.vol,export-brick-name.vol;
.vol files are configuration files used by glusterfs process. Volfiles will be usually located at /var/lib/glusterd/vols/volume-name/. Eg:vol-name-fuse.vol,export-brick-name.vol,etc..
Sub-volumesin the .vol files are present in the bottom-up approach and then after tracing forms a tree structure, where in the hierarchy last comes the client volumes.
Server
控制数据存储文件系统的机器
The machine which hosts the actual file system in which the data will be stored.
Client
挂载卷(volume)的机器
The machine which mounts the volume (this may also be a server).
Replicate
为了提高数据可用性的数据备份(冗余)
Replicate is generally done to make a redundancy of the storage for data availability.
二.GlusterFS原理
1. 原始数据格式存储(Data Stored in Native Formats)
GlusterFS以原始数据格式(如EXT3、EXT4、XFS、ZFS)储存数据,并实现多种数据自动修复机制。因此,系统极具弹性,即使离线情形下文件也可以通过其他标准工具进行访问。如果用户需要从GlusterFS中迁移数据,不需要作任何修改仍然可以完全使用这些数据。
2. 无元数据服务设计(No Metadata with the Elastic Hash Algorithm)
对Scale-Out存 储系统而言,最大的挑战之一就是记录数据逻辑与物理位置的映像关系,即数据元数据,可能还包括诸如属性和访问权限等信息。传统分布式存储系统使用集中式或分布式元数据服务来维护元数据,集中式元数据服务会导致单点故障和性能瓶颈问题,而分布式元数据服务存在性能负载和元数据同步一致性问题。特别是对于海量小文件的应用,元数据问题是个非常大的挑战。
GlusterFS独 特地采用无元数据服务的设计,取而代之使用算法来定位文件,元数据和数据没有分离而是一起存储。集群中的所有存储系统服务器都可以智能地对文件数据分片进行定位,仅仅根据文件名和路径并运用算法即可,而不需要查询索引或者其他服务器。这使得数据访问完全并行化,从而实现真正的线性性能扩展。无元数据服务器 极大提高了GlusterFS的性能、可靠性和稳定性。
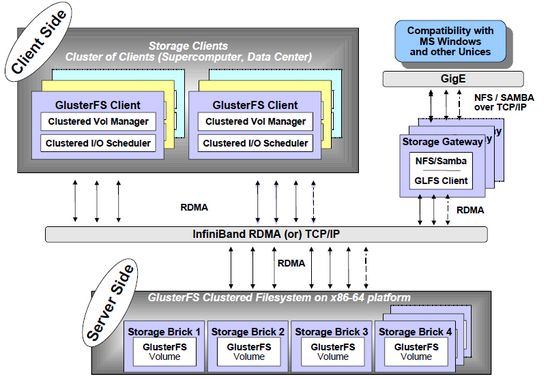
GlusterFS总体架构与组成部分如上图所示,它主要由
存储服务器(Brick Server)、
客户端
NFS/Samba存储网关 组成。
GlusterFS架构中没有元数据服务器组件,这是其最大的设计这点,对于提升整个系统的性能、可靠性和稳定性都有着决定性的意义。GlusterFS支持TCP/IP和InfiniBand RDMA高速网络互联,客户端可通过原生Glusterfs协议访问数据,其他没有运行GlusterFS客户端的终端可通过NFS/CIFS标准协议通过存储网关访问数据。
存储服务器主要提供基本的数据存储功能,最终的文件数据通过统一的调度策略分布在不同的存储服务器上。它们上面运行着Glusterfsd进行,负责处理来自其他组件的数据服务请求。如前所述,数据以原始格式直接存储在服务器的本地文件系统上,如EXT3、EXT4、XFS、ZFS等,运行服务时指定数据存储路径。多个存储服务器可以通过客户端或存储网关上的卷管理器组成集群,如Stripe(RAID0)、Replicate(RAID1)和DHT(分布式Hash)存储集群,也可利用嵌套组合构成更加复杂的集群,如RAID10。
由于没有了元数据服务器,客户端承担了更多的功能,包括数据卷管理、I/O调度、文件定位、数据缓存等功能。客户端上运行Glusterfs进程,它实际是Glusterfsd的符号链接,利用FUSE(File system in User Space)模块将GlusterFS挂载到本地文件系统之上,实现POSIX兼容的方式来访问系统数据。在最新的3.1.X版本中,客户端不再需要独立维护卷配置信息,改成自动从运行在网关上的glusterd弹性卷管理服务进行获取和更新,极大简化了卷管理。GlusterFS客户端负载相对传统分布式文件系统要高,包括CPU占用率和内存占用。
GlusterFS存储网关提供弹性卷管理和NFS/CIFS访问代理功能,其上运行Glusterd和Glusterfs进程,两者都是Glusterfsd符号链接。卷管理器负责逻辑卷的创建、删除、容量扩展与缩减、容量平滑等功能,并负责向客户端提供逻辑卷信息及主动更新通知功能等。GlusterFS 3.1.X实现了逻辑卷的弹性和自动化管理,不需要中断数据服务或上层应用业务。对于Windows客户端或没有安装GlusterFS的客户端,需要通过NFS/CIFS代理网关来访问,这时网关被配置成NFS或Samba服务器。相对原生客户端,网关在性能上要受到NFS/Samba的制约。
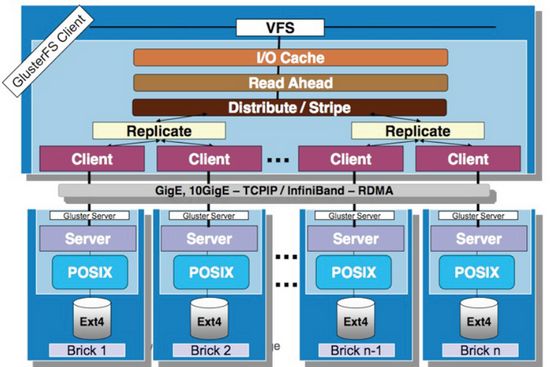
GlusterFS是模块化堆栈式的架构设计,如图3所示。模块称为Translator,是GlusterFS提供的一种强大机制,借助这种良好定义的接口可以高效简便地扩展文件系统的功能。服务端与客户端模块接口是兼容的,同一个translator可同时在两边加载。每个translator都是SO动态库,运行时根据配置动态加载。每个模块实现特定基本功能,GlusterFS中所有的功能都是通过translator实现,比如Cluster, Storage, Performance, Protocol, Features等,基本简单的模块可以通过堆栈式的组合来实现复杂的功能。这一设计思想借鉴了GNU/Hurd微内核的虚拟文件系统设计,可以把对外部系统的访问转换成目标系统的适当调用。大部分模块都运行在客户端,比如合成器、I/O调度器和性能优化等,服务端相对简单许多。客户端和存储服务器均有自己的存储栈,构成了一棵Translator功能树,应用了若干模块。模块化和堆栈式的架构设计,极大降低了系统设计复杂性,简化了系统的实现、升级以及系统维护。
3. 弹性哈希算法
对于分布式系统而言,元数据处理是决定系统扩展性、性能以及稳定性的关键。GlusterFS另辟蹊径,彻底摒弃了元数据服务,使用弹性哈希算法代替传统分布式文件系统中的集中或分布式元数据服务。这根本性解决了元数据这一难题,从而获得了接近线性的高扩展性,同时也提高了系统性能和可靠性。GlusterFS使用算法进行数据定位,集群中的任何服务器和客户端只需根据路径和文件名就可以对数据进行定位和读写访问。换句话说,GlusterFS不需要将元数据与数据进行分离,因为文件定位可独立并行化进行。GlusterFS中数据访问流程如下:
计算hash值,输入参数为文件路径和文件名;
根据hash值在集群中选择子卷(存储服务器),进行文件定位;
对所选择的子卷进行数据访问。
GlusterFS目前使用Davies-Meyer算法计算文件名hash值,获得一个32位整数。Davies-Meyer算法具有非常好的hash分布性,计算效率很高。假设逻辑卷中的存储服务器有N个,则32位整数空间被平均划分为N个连续子空间,每个空间分别映射到一个存储服务器。这样,计算得到的32位hash值就会被投射到一个存储服务器,即我们要选择的子卷。难道真是如此简单?现在让我们来考虑一下存储节点加入和删除、文件改名等情况,GlusterFS如何解决这些问题而具备弹性的呢?
逻辑卷中加入一个新存储节点,如果不作其他任何处理,hash值 映射空间将会发生变化,现有的文件目录可能会被重新定位到其他的存储服务器上,从而导致定位失败。解决问题的方法是对文件目录进行重新分布,把文件移动到 正确的存储服务器上去,但这大大加重了系统负载,尤其是对于已经存储大量的数据的海量存储系统来说显然是不可行的。
另一种方法是使用一致性哈希算法,修改新增节点及相邻节点的hash映射空间,仅需要移动相邻节点上的部分数据至新增节点,影响相对小了很多。然而,这又带来另外一个问题,即系统整体负载不均衡。
GlusterFS没有采用上述两种方法,而是设计了更为弹性的算法。
GlusterFS的 哈希分布是以目录为基本单位的,文件的父目录利用扩展属性记录了子卷映射信息,其下面子文件目录在父目录所属存储服务器中进行分布。
说的形象一点: 每一块brick有一个32位的hash值,然后每一块brick的hash值覆盖了所有存储空间, 没有漏和覆盖, 然后每一个文件有一个hash值, 这个值是在brick32位以内的, 就代表这个文件是在这个brick里.
由于文件目录事先保存 了分布信息,因此新增节点不会影响现有文件存储分布,它将从此后的新创建目录开始参与存储分布调度。这种设计,新增节点不需要移动任何文件,但是负载均衡 没有平滑处理,老节点负载较重。GlusterFS在设计中考虑了这一问题,在新建文件时会优先考虑容量负载最轻的节点,在目标存储节点上创建文件链接直向真正存储文件的节点。另外,GlusterFS弹性卷管理工具可以在后台以人工方式来执行负载平滑,将进行文件移动和重新分布,此后所有存储服务器都会均会被调度。
GlusterFS目前对存储节点删除支持有限,还无法做到完全无人干预的程度:
- 如果直接删除节点,那么所在存储服务器上的文件将无法浏览和访问,创建文件目录也会失败。当前人工解决方法有两个,一是将节点上的数据重新复制到GlusterFS中,二是使用新的节点来替换删除节点并保持原有数据。
- 如果一个文件被改名,显然hash算法将产生不同的值,非常可能会发生文件被定位到不同的存储服务器上,从而导致文件访问失败。采用数据移动的方法,对于大文件是很难在实时完成的。为了不影响性能和服务中断,GlusterFS采 用了文件链接来解决文件重命名问题,在目标存储服务器上创建一个链接指向实际的存储服务器,访问时由系统解析并进行重定向。另外,后台同时进行文件迁移, 成功后文件链接将被自动删除。对于文件移动也作类似处理,好处是前台操作可实时处理,物理数据迁移置于后台选择适当时机执行。
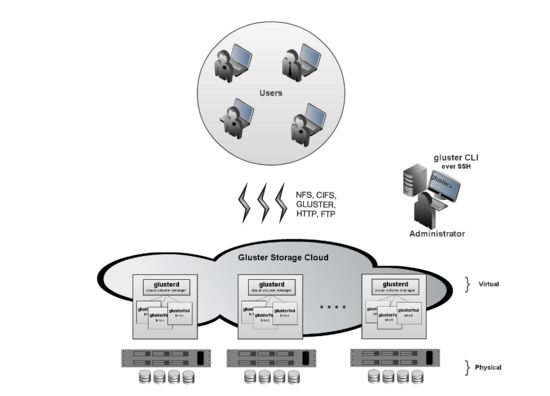
弹性哈希算法为文件分配逻辑卷,那么GlusterFS如何为逻辑卷分配物理卷呢?GlusterFS3.1.X实现了真正的弹性卷管理,如图4所 示。存储卷是对底层硬件的抽象,可以根据需要进行扩容和缩减,以及在不同物理系统之间进行迁移。存储服务器可以在线增加和移除,并能在集群之间自动进行数 据负载平衡,数据总是在线可用,没有应用中断。文件系统配置更新也可以在线执行,所作配置变动能够快速动态地在集群中传播,从而自动适应负载波动和性能调 优。
弹性哈希算法本身并没有提供数据容错功能,GlusterFS使用镜像或复制来保证数据可用性,推荐使用镜像或3路复制。复制模式下,存储服务器使用同步写复制到其他的存储服务器,单个服务器故障完全对客户端透明。此外,GlusterFS没有对复制数量进行限制,读被分散到所有的镜像存储节点,可以提高读性能。弹性哈希算法分配文件到唯一的逻辑卷,而复制可以保证数据至少保存在两个不同存储节点,两者结合使得GlusterFS具备更高的弹性。