概述
在新版本中,PyTorch引入了许多令人兴奋的新特性,主要的更新在于 Variable和Tensor的合并 。为了方便代码的迁移到新的版本下,对新版本特性做一些记录(翻译),主要是以下几个部分。
- Tensor 和 Variable合并,autograd的机制有所不同,变得更简单,使用requires_grad和上下文相关环境管理,弃用了 volatile 标志。
- 支持 scalar 即0维的Tensor
- Numpy风格的Tensor构建。
- 提出了device,更简单地在cpu和gpu中移动数据。
1. Tensor 和 Variable 合并
在PyTorch以前的版本中,Tensor类似于numpy中的ndarray,只是对多维数组的抽象。为了能够使用自动求导机制,必须使用Variable对其进行包装。而现在,这两个东西已经完全合并成一个了,以前Variable的使用情境都可以使用Tensor。所以以前训练的时候总要额外写的warpping语句用不到了。
#老版本的写法
for data, label in data_loader:
data, label = Variable(data), Variable(label)
loss = criterion(model(data), target)
# 新版本不再需要再对Tensor进行包装成 Variable的操作
# device 后面会讲到
device = torch.device('cuda' if torch.cuda.is_availabel() else 'cpu')
for data, label in data_loader:
data, lalel = data.to(device), label.to(device)
2. Tensor 的类型 type()
以前我们可以使用 type() 获取Tensor的data type(FloatTensor,LongTensor等)。现在需要使用x.type() 获取类型或 isinstance()判别类型。
>>> x = torch.DoubleTensor([1,2,3])
>>> print type(x) #曾经会给出 torch.DoubleTensor
>>>print (x.type())
'torch.DoubleTensor'
>>>print isinstance(x, torch.DoubleTensor)
True
3. autograd 现在如何追踪计算图的历史
Tensor 和 Variable 的合并,简化了计算图的构建,但在操作过程中会和以前有一些不同,具体如下:
-
requires_grad, 这个 Variable 中的核心标志, 现在成了 Tensor 的属性。
之前的 Variable 的使用规则可以同样使用于 Tensor , autograd 自动跟踪求导 那些至少有一个 input 的 requires_grad==True 的计算节点构成的图。
>>> x = torch.ones(1) ## 默认requires_grad = False >>> x.requires_grad False >>> y = torch.ones(1) ## 同样,y的requires_grad标志也是False >>> z = x + y >>> ## 所有的输入节点都不要求梯度,所以z的requires_grad也是False >>> z.requires_grad False >>> ## 所以如果试图对z做梯度反传,会抛出Error >>> z.backward() RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn >>> >>> ## 通过手动指定的方式创建 requires_grad=True 的Tensor >>> w = torch.ones(1, requires_grad=True) >>> w.requires_grad True >>> ## 把它和之前requires_grad=False的节点相加,得到输出 >>> total = w + z >>> ## 由于w需要梯度,所以total也需要 >>> total.requires_grad True >>> ## 可以做bp >>> total.backward() >>> w.grad tensor([ 1.]) >>> ## 不用有时间浪费在求取 x y z的梯度上,因为它们没有 require grad,它们的grad == None >>> z.grad == x.grad == y.grad == None True -
操作 requires_grad 标志
除了直接设置这个属性,你可以使用my_tensor.requires_grad_()就地置这个标志为 True(还记得吗,以_结尾的方法名表示in-place的操作)。或者就在构造的时候传入此参数。
>>>exisiting_tensor.requires_grad_( ) >>>existing_tensor.requires_grad True >>>my_tensor = torch.tensor(3, 4, requires_grad=True) >>>my_tensor.requries_grad True -
.data 怎么办?
原来版本中,对于某个Variable,我们可以通过x.data的方式获取其包装的Tensor。现在两者已经merge到了一起,如果你调用y = x.data仍然和以前相似,y现在会共享x的data,并与x的计算历史无关,且其requires_grad标志为False。这会导致不安全。
>>> y = x.data #以前的方式,取出Variable中的Tensor >>> y 和 x 是共享内存的,但是这里y已经不需要grad了,新版本中此时y返回的是 requires_grad = False 的Tensor >>> 此时对y的任何操作都不会被autograd所追踪,所以如果反向传播时需要计算x的梯度,导致出现错误 >>> #解决办法 >>> y = x.detach() #对y的操作仍然会被autograd捕捉
4. 支持标量 0维(scalar) 的Tensor
以前索引一个一维Tensor,返回的是一个number类型,但是索引一个Variable确实返回一个size为(1,)的vector。 再比如一些reduction操作, 比如tensor.sum()返回一个number, 但是variable.sum()返回的是一个size为(1,)的vector。
scalar 是维度为0 的Tensor,用 torch.tensor( )(小写)进行创建。
>>> torch.tensor(3.1416) # 用torch.tensor来创建scalar
tensor(3.1416) # 注意 scalar是打印出来是没有[]的
>>> torch.tensor(3.1416).size() # size是0
torch.Size([])
>>> torch.tensor([3]).size() # compare to a vector of size 1
torch.Size([1]) # 如果是tensor, 打印出来会用`[]`包上
>>>
>>> vector = torch.arange(2, 6) # this is a vector
>>> vector
tensor([ 2., 3., 4., 5.])
>>> vector[3] # 现在, indexing一个一维tensor返回的是一个tensor了!
tensor(5.)
>>> vector[3].item() # 需要额外加上.item() 来获得里面的值
5.0
>>> mysum = torch.tensor([2, 3]).sum() # 而这种reduction操作, 返回的是一个scalar了(0-dimension 的tensor)
>>> mysum
tensor(5)
>>> mysum.size()
torch.Size([])
从上面的例子可以看出,通过引入 scalar,可以将返回值类型进行统一。
- 取得一个tensor的值,用 .item()
- 创建 scalar,用 torch.tensor(number)
- torch.tensor(list), 可以接受 list 或者 array类型进行创建Tensor
5. 累加 loss
以前了累加loss(为了看loss的大小)一般是用 total_loss+=loss.data[0] , 比较诡异的是, 为啥是.data[0]? 这是因为, loss通常都是由损失函数计算出来的一个标量,也就是包装了(1,)大小Tensor的Variable。在新的版本中,loss则变成了0D的scalar。对一个scalar做indexing是没有意义的,应该使用 loss.item() 获取 python number。
total_loss 只是我们用来查看训练过程的一个量,没有必要去维护一个计算图Graph,给显存造成负担。
6. 弃用 volatile
volatile 标志被弃用了,现在没有任何效果。以前的版本中,一个设置volatile=True的Variable 表明其不会被autograd追踪。现在,被替换成了一个更灵活的上下文管理器,如torch.no_grad(),torch.set_grad_enable(grad_mode)等。
>>> x = torch.zeros(1, requires_grad=True)
>>> with torch.no_grad(): # 使用 torch,no_grad()构建不需要track的上下文环境
... y = x * 2
>>> y.requires_grad
False
>>>
>>> is_train = False
>>> with torch.set_grad_enabled(is_train): # 在inference的时候,设置不要track
... y = x * 2
>>> y.requires_grad
False
>>> torch.set_grad_enabled(True) # 当然也可以不用with构建上下文环境,而单独这样用
>>> y = x * 2
>>> y.requires_grad
True
>>> torch.set_grad_enabled(False)
>>> y = x * 2
>>> y.requires_grad
False
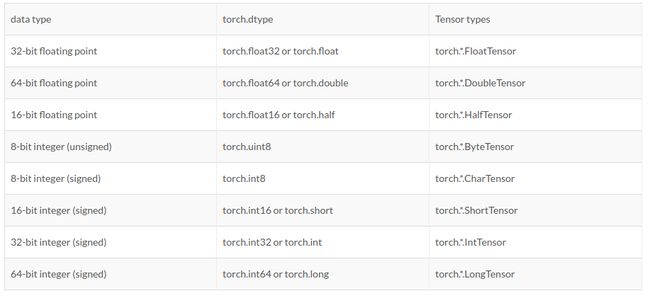
7. dtype, devices 和 Numpy 风格的构建函数
以前的版本中,我们需要以”tensor type”的形式给出对data type(如float或double),device type(如cpu或gpu)以及layout(dense或sparse)的限
torch.dtype
下面是可用的 torch.dtypes (data types) 和他们对应的 tensor types。可以用 x.dtype获取
torch.device
torch.device 包含了 device type( 如 cpu 或 gpu) 和可能的设备 id。 使用 torch.device('{device_tyep}') 或者 torch.device('{device_type}:{device_ordinal}')的方式来初始化。
如果没有制定 device ordinal, 那么默认的是当前的device. 例如 , torch.device('cuda') 相当于 torch.device('cuda:X'),其中 X是 torch.cuda.current_device() 的返回结果。
8. 创建 Tensor(Numpy 风格)
你可以使用dtype,device,layout和requires_grad更好地控制Tensor的创建。
>>> device = torch.device("cuda : 1")
# 现在创建 Tensor 时候可以制定类型dtype, 创建位置device,以及是否需要求导requires_grad
>>> x = torch.randn(3, 3, dtype = torch.float64, device=device, requires_grad=True)
torch.tensor(data, ...)
torch.tensor 是新加入的Tensor 构建函数。它接受一个“array-like”的参数, 并将其value 复制到一个新的Tensor中。可以将它看成是 numpy.array 的等价物。 不同于torch.*Tensor 方法,你可以创建0D的Tensor,也就是scalar。此外,如果dtype参数没有给出,它会自动推断。
推荐使用这个函数从已有的data里面,如 Python List 或者 Numpy ndarray 创建 Tensor
torch.*_like, torch.new_*形式的创建Tensor, 返回相同属性的tensor,除非有特殊指定。
为了指定shape参数,可以使用tuple,如 torch.zeros((2,3))(Numpy风格),也可以使用可变量参数torch.zeros(2,3)(以前的pytorch版本只支持这种风格)。