语音识别:
Getting Started!首先,我们要知道语音的产生过程
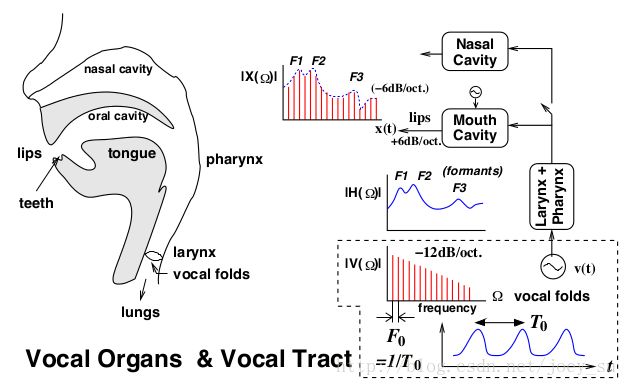
状态:由肺产生向外的气流,完全放松时声带张开,就是平时的呼吸。如果声带一张一合(振动)形成周期性的脉冲气流。这个脉冲气流的周期称之为——基音周期(题主所言因音色不同导致的频率不同,事实上音色的大多是泛频上的差异,建立在基频之上,这个基频就是基音周期了,泛频可以忽略)。当然啦,这只是在发浊音(b,d,v...)时才会有,当发出清音(p,t,f...)时声带不振动,但是会处于紧绷状态,当气流涌出时会在声带产生湍流。清音和浊音是音素的两大类。接下来脉冲气流/湍流到达声道,由声道对气流进行调制,形成不同的音素。多个音素组成一个音节(就汉语而言是[声母]+韵母)。如果没学过信号系统那就想像一下平舌音和翘舌音,z和zh发声时肺和喉的状态都一样,只是舌头动作不一样,发出的声音也就不一样了,这就算是简单的调制。从而声音的波形会发生一些变化。这个波形,就是以后分析所需要的数据。
标识声音的图像有以下三种
- 频谱图
- 时谱图
- 语谱图
以千里码 语音识别-1为例,将Mp3文件转换成wav,分析其频谱图
参照wav使用手册,让我们介绍一下wav文件
WAV是Microsoft开发的一种声音文件格式,虽然它支持多种压缩格式,不过它通常被用来保存未压缩的声音数据(PCM脉冲编码调制)。WAV有三个重要的参数:声道数、取样频率和量化位数。
- 声道数:可以是单声道或者是双声道
- 采样频率:一秒内对声音信号的采集次数,常用的有8kHz, 16kHz, 32kHz, 48kHz, 11.025kHz, 22.05kHz, 44.1kHz
- 量化位数:用多少bit表达一次采样所采集的数据,通常有8bit、16bit、24bit和32bit等几种
1.读入二进制音频流数据流程
- 对于一个音频实例wf而言,通过调用它的方法读取WAV文件的格式和数据:getnchannels, getsampwidth, getframerate, getnframes等方法可以单独返回WAV文件的特定的信息。
- readframes:读取声音数据,传递一个参数指定需要读取的长度(以取样点为单位),readframes返回的是二进制数据
PS:注意需要使用"rb"(二进制模式)打开文件
import wave
import pyaudio
import numpy
from matplotlib import pylab
#打开wav文档,文件路径根据需要修改
wf = wave.open("F:\\work\\war.wav","rb")
#创建PyAudio对象
p = pyaudio.PyAudio()
class Audio(object):
def __init__(self):
self.channels = wf.getnchannels()
# 返回音频通道数
self.rate = wf.getframerate()
# 返回采样频率。
self.format = p.get_format_from_width(wf.getsampwidth())
# 返回指定宽度的PortAudio格式常量。
self.stream = p.open(format=self.format,channels=self.channels,rate=self.rate,output=True)
# 使用所需的音频参数在所需设备上打开一个流
self.nframes = wf.getnframes()
# 返回音频帧数
self.collect_point_num = 44100
# 采样点数,修改采样点数和起始位置进行不同位置和长度的音频波形分析
self.start = 0
# 开始采样位置
def read_data(self):
self.str_data = wf.readframes(self.nframes)
# 读取声音数据,传递一个参数指定需要读取的长度(以取样点为单位),readframes返回的是二进制数据(即bytes数组)
# print(self.str_data)
wf.close()
#关闭媒体流
if __name__ == '__main__':
aduio = Audio()
aduio.read_data()
python output
2.生成的流媒体字节数组计算出每个取样的时间
- 将读取的二进制数据转换为一个可以计算的数组
- 通过fromstring函数将字符串转换为数组,通过其参数dtype指定转换后的数据格式,由于我们的声音格式是以两个字节表示一个取样值,因此采用short数据类型转换。现在我们得到的wave_data是一个一维的short类型的数组,但是因为我们的声音文件是双声道的,因此它由左右两个声道的取样交替构成:LRLRLRLR....LR(L表示左声道的取样值,R表示右声道取样值)'
- 由帧率的计算公式:
采样率 = 每秒中的采样频率/每秒中的采样点数 帧率(fps) =1 /采样率 - 将波形数据转换为数组
- 通过取样点数和取样频率计算出每个取样的时间
def convrt_data(self):
self.df = self.rate / (self.collect_point_num - 1)
# 根据总平均法使用全局帧数除以全局时间,以求出帧率
def Data_collection(self):
wave_data = numpy.fromstring(self.str_data,dtype=numpy.short)
# 根据声道数和量化单位,将读取的二进制数据转换为一个可以计算的数组
wave_data.shape = -1, 2
# -1代表左声道,2代表右声道
# 通过fromstring函数将字符串转换为数组,通过其参数dtype指定转换后的数据格式,由于我们的声音格式是以两个字节表示一个取样值,
# 因此采用short数据类型转换。现在我们得到的wave_data是一个一维的short类型的数组,但是因为我们的声音文件是双声道的,
# 因此它由左右两个声道的取样交替构成:LRLRLRLR....LR(L表示左声道的取样值,R表示右声道取样值)。修改wave_data的sharp之后:
# 将wave_data数组改为2列,行数自动匹配。在修改shape的属性时,需使得数组的总长度不变。v
wave_data = wave_data.T
# 将波形数据转换为数组
freq = [self.df*self.collect_point_num for n in range(0,self.collect_point_num)]
# 通过取样点数和取样频率计算出每个取样的时间
3.划分采样位置,建立频谱图坐标系,根据采样时间标记采样点在频谱图上的位置
- wave_data2保存声音字节数组转置后的结果,为列数为1存储的数组
- 固定第一位,划分第二维区间从0一直扫描到行尾
- 避免波形字节数组过长,利用numpy.fft.fft对压缩为1/2的波形字节数组进行快速傅里叶变换,常规显示采样频率一半的频谱
- 设定如果每个取样点的取样时间大于4000ms,分隔单位为10的波形数组显示
def Data_collection(self):
wave_data = numpy.fromstring(self.str_data,dtype=numpy.short)
# 根据声道数和量化单位,将读取的二进制数据转换为一个可以计算的数组
wave_data.shape = -1.2
# -1代表左声道,2代表右声道
# 通过fromstring函数将字符串转换为数组,通过其参数dtype指定转换后的数据格式,由于我们的声音格式是以两个字节表示一个取样值,
# 因此采用short数据类型转换。现在我们得到的wave_data是一个一维的short类型的数组,但是因为我们的声音文件是双声道的,
# 因此它由左右两个声道的取样交替构成:LRLRLRLR....LR(L表示左声道的取样值,R表示右声道取样值)。修改wave_data的sharp之后:
# 将wave_data数组改为2列,行数自动匹配。在修改shape的属性时,需使得数组的总长度不变。v
wave_data = wave_data.T
# 将波形数据转换为数组
freq = [self.df*self.collect_point_num for n in range(0,self.collect_point_num)]
# 通过取样点数和取样频率计算出每个取样的时间
wave_data2 = wave_data[0][self.start:self.start+self.collect_point_num]
c = numpy.fft.fft(wave_data2)*2/self.collect_point_num
# 常规显示采样频率一半的频谱
d = int(len(c)/2)
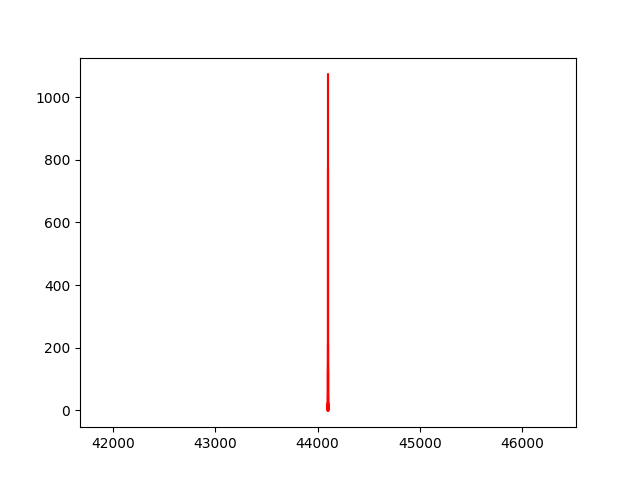
while freq[0] > 4000:
d -= 10
pylab.plot(freq[:d-1],abs(c[:d-1]),"r")
pylab.show()
python console:频谱的时间段划分似乎造成了误差,导致统计结果趋于集中
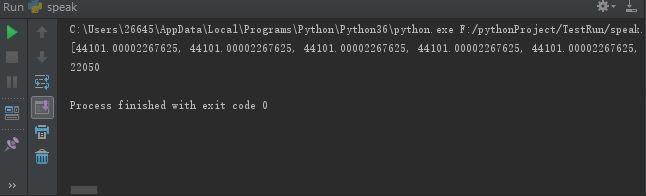
Test1:打印波形字节数组长度以及每个采样点采样花费的时间
def Data_collection(self):
wave_data = numpy.fromstring(self.str_data,dtype=numpy.short)
# 根据声道数和量化单位,将读取的二进制数据转换为一个可以计算的数组
wave_data.shape = -1, 2
# -1代表左声道,2代表右声道
# 通过fromstring函数将字符串转换为数组,通过其参数dtype指定转换后的数据格式,由于我们的声音格式是以两个字节表示一个取样值,
# 因此采用short数据类型转换。现在我们得到的wave_data是一个一维的short类型的数组,但是因为我们的声音文件是双声道的,
# 因此它由左右两个声道的取样交替构成:LRLRLRLR....LR(L表示左声道的取样值,R表示右声道取样值)。修改wave_data的sharp之后:
# 将wave_data数组改为2列,行数自动匹配。在修改shape的属性时,需使得数组的总长度不变。v
wave_data = wave_data.T
# 将波形数据转换为数组
freq = [self.df*self.collect_point_num for n in range(0,self.collect_point_num)]
print(freq)
# 通过取样点数和取样频率计算出每个取样的时间
wave_data2 = wave_data[0][self.start:self.start+self.collect_point_num]
c = numpy.fft.fft(wave_data2)*2/self.collect_point_num
d = int(len(c)/2)
print(d)
python console
Test2: 原来是设定的采样时间过小,修改统计条件为 freq[0] > 44101
def Data_collection(self):
wave_data = numpy.fromstring(self.str_data,dtype=numpy.short)
# 根据声道数和量化单位,将读取的二进制数据转换为一个可以计算的数组
wave_data.shape = -1, 2
# -1代表左声道,2代表右声道
# 通过fromstring函数将字符串转换为数组,通过其参数dtype指定转换后的数据格式,由于我们的声音格式是以两个字节表示一个取样值,
# 因此采用short数据类型转换。现在我们得到的wave_data是一个一维的short类型的数组,但是因为我们的声音文件是双声道的,
# 因此它由左右两个声道的取样交替构成:LRLRLRLR....LR(L表示左声道的取样值,R表示右声道取样值)。修改wave_data的sharp之后:
# 将wave_data数组改为2列,行数自动匹配。在修改shape的属性时,需使得数组的总长度不变。v
wave_data = wave_data.T
# 将波形数据转换为数组
freq = [self.df*self.collect_point_num for n in range(0,self.collect_point_num)]
print(freq)
# 通过取样点数和取样频率计算出每个取样的时间
wave_data2 = wave_data[0][self.start:self.start+self.collect_point_num]
c = numpy.fft.fft(wave_data2)*2/self.collect_point_num
d = int(len(c)/2)
print(d)
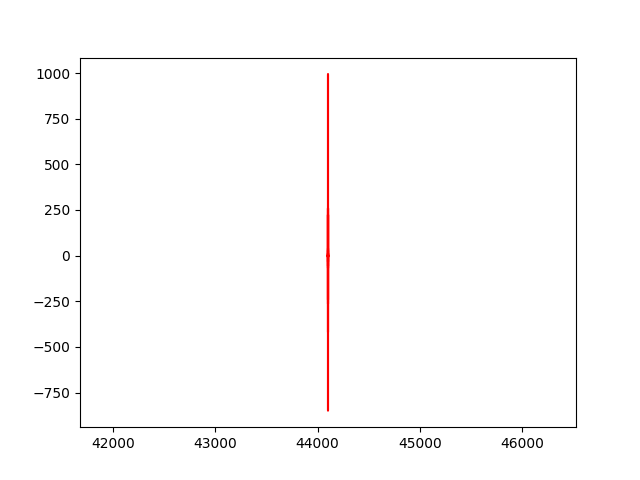
while freq[0] > 44101:
d -= 0.1
pylab.plot(freq[:d-1],abs(c[:d-1]),"r")
pylab.show()
python console采样的分布过于密集,不适合用频谱图进行统计
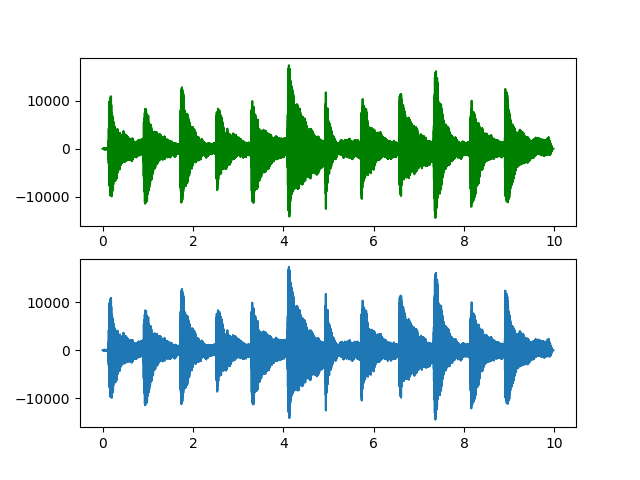
Test3:使用波形图,分别用subplot211与subplot212标识左右声道的波形
import wave
import pyaudio
import numpy
from matplotlib import pylab
#打开wav文档,文件路径根据需要修改
wf = wave.open("F:\\work\\war.wav","rb")
#创建PyAudio对象
p = pyaudio.PyAudio()
class Audio(object):
def __init__(self):
self.channels = wf.getnchannels()
# 返回音频通道数
self.rate = wf.getframerate()
# 返回采样频率。
self.format = p.get_format_from_width(wf.getsampwidth())
# 返回指定宽度的PortAudio格式常量。
self.stream = p.open(format=self.format,channels=self.channels,rate=self.rate,output=True)
# 使用所需的音频参数在所需设备上打开一个流
self.nframes = wf.getnframes()
# 返回音频帧数
self.collect_point_num = 44100
# 采样点数,修改采样点数和起始位置进行不同位置和长度的音频波形分析
self.start = 0
# 开始采样位置
def read_data(self):
self.str_data = wf.readframes(self.nframes)
# 读取声音数据,传递一个参数指定需要读取的长度(以取样点为单位),readframes返回的是二进制数据(即bytes数组)
# print(self.str_data)
wf.close()
def convert_data(self):
self.df = self.rate / (self.collect_point_num - 1)
# print(self.df)
# 使用全局采样频率除以全局采样点数,以求出帧率
def Data_collection(self):
wave_data = numpy.fromstring(self.str_data,dtype=numpy.short)
# 根据声道数和量化单位,将读取的二进制数据转换为一个可以计算的数组
wave_data.shape = -1, 2
# -1代表左声道,2代表右声道
# 通过fromstring函数将字符串转换为数组,通过其参数dtype指定转换后的数据格式,由于我们的声音格式是以两个字节表示一个取样值,
# 因此采用short数据类型转换。现在我们得到的wave_data是一个一维的short类型的数组,但是因为我们的声音文件是双声道的,
# 因此它由左右两个声道的取样交替构成:LRLRLRLR....LR(L表示左声道的取样值,R表示右声道取样值)。修改wave_data的sharp之后:
# 将wave_data数组改为2列,行数自动匹配。在修改shape的属性时,需使得数组的总长度不变。v
wave_data = wave_data.T
# 将波形数据转换为数组
freq = [self.df*self.collect_point_num for n in range(0,self.collect_point_num)]
# print(freq)
# 通过取样点数和取样频率计算出每个取样的时间
wave_data2 = wave_data[0][self.start:self.start+self.collect_point_num]
c = numpy.fft.fft(wave_data2)*2/self.collect_point_num
d = int(len(c)/2)
# print(d)
while freq[0] > 44101:
d -= 20
pylab.plot(freq[:d-1],c[:d-1],"r")
pylab.show()
def wavread(self):
wavfile = wf
params = wavfile.getparams()
framesra, frameswav = params[2], params[3]
datawav = wavfile.readframes(frameswav)
wavfile.close()
datause = numpy.fromstring(datawav, dtype=numpy.short)
datause.shape = -1, 2
datause = datause.T
time = numpy.arange(0, frameswav) * (1.0 / framesra)
return datause, time
def work(self):
self.read_data()
self.convert_data()
self.Data_collection()
if __name__ == '__main__':
aduio = Audio()
# aduio.work()
wavdata, wavtime = aduio.wavread()
pylab.title("Night.wav's Frames")
pylab.subplot(211)
pylab.plot(wavtime, wavdata[0], color='green')
pylab.subplot(212)
pylab.plot(wavtime, wavdata[1])
pylab.show()
python console