9.1 正则介绍 grep(上)


1)正则解释
正则就是一串有规律的字符串;
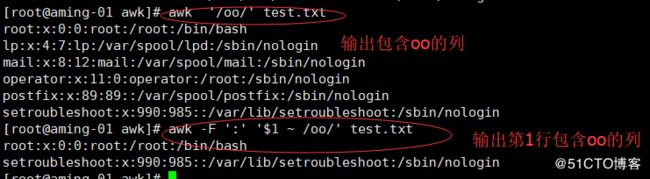
grep 过滤关键词
< mkdir /grep/ >
< cp /etc/passwd /root/grep/ >
< grep 'nologin' passwd > 过滤nologin 自动标红了
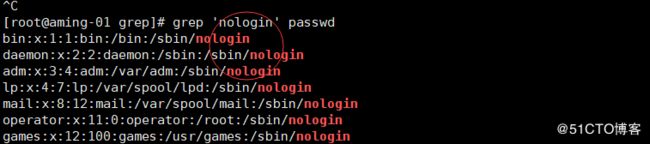
< grep -c 'nologin' passwd > 显示行数
< grep -ni 'nologin' passwd > 不区分大小写
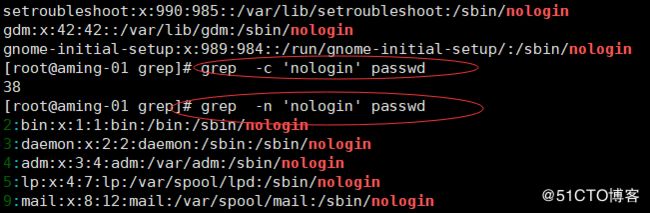
< grep -v 'nologin' passwd > 除了nologin 的都过滤出来
9.2 正则 grep(中)
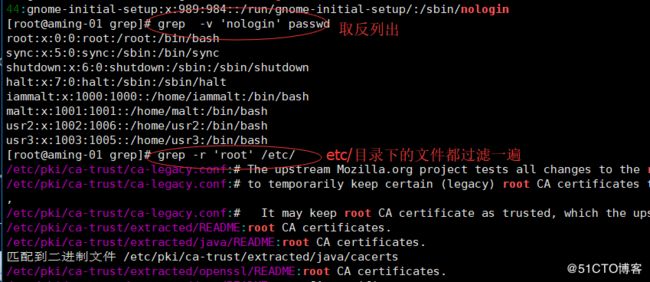
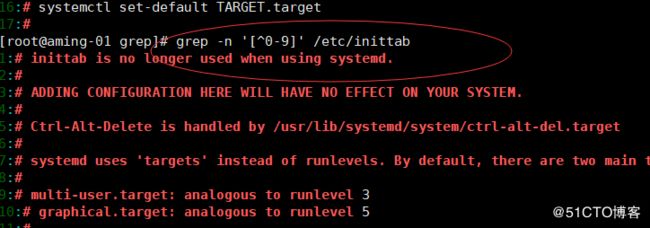
不要改系统下/etc/下的配置文件,否者可能系统出错,可以拷贝出来后修改备份文件。
[^] 在括号内取反
例如 [^0-9] 那就是非数字(包括字母+特殊符号)
例如[^a-zA-Z] 那就是非字母(包括数字+特殊符号)
例如[^0-9a-zA-Z]那就是非数字字幕(特殊符号)
9.3 正则 grep(下)
==============================================================
9.4 sed(上)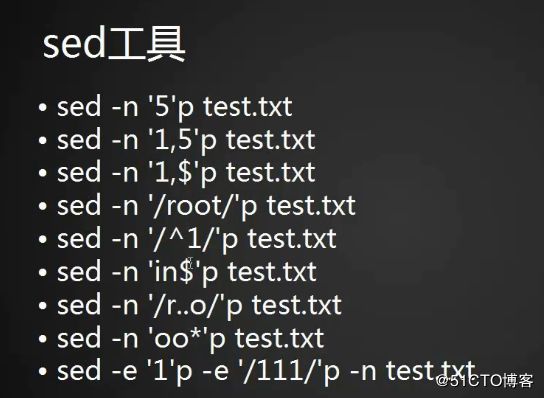
sed 强项在于替换,替换指定字符。
(1)匹配
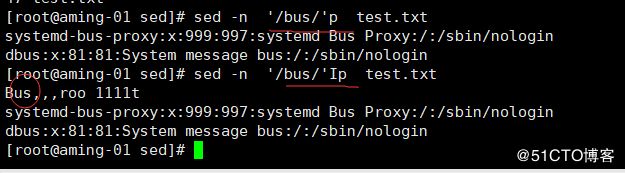
< sed '/root/'p test.txt > p 打印
会把匹配的信息打出来后,再把所有内容打印出来;若未匹配只打印所有内容。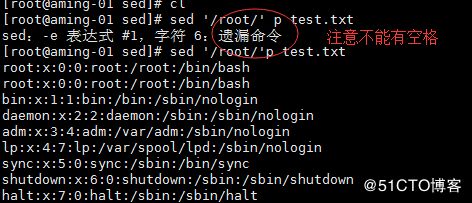
< sed -n '/root/'p test.txt > -n 只打印匹配的信息
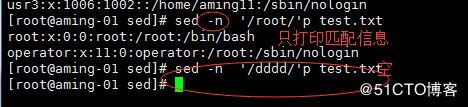
也支持 < sed -n '/r.t/'p test.txt >
< sed -n '/r*t/'p test.txt >
< sed -n '/o+t/'p test.txt > 需要脱义== < sed -nr '/o+t/'p test.txt > 不脱义
(2)打印

(3) 多个操作时
9.5 sed(下)
(1) p打印 d删除
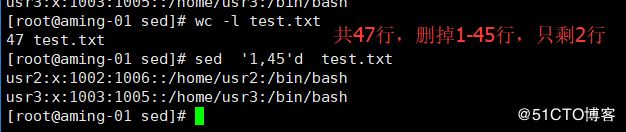
< wc -l test.txt> 查看总行数
< sed '1,45'd test.txt>删除1-45行,实际上是排除掉 并不会真修改文件
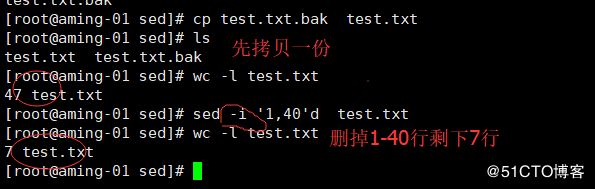
< sed -i '1,45'd test.txt>删除1-45行,文件内容也被删除 -i
< sed -i '/user2/'d test.txt>> 删掉包含user2的行
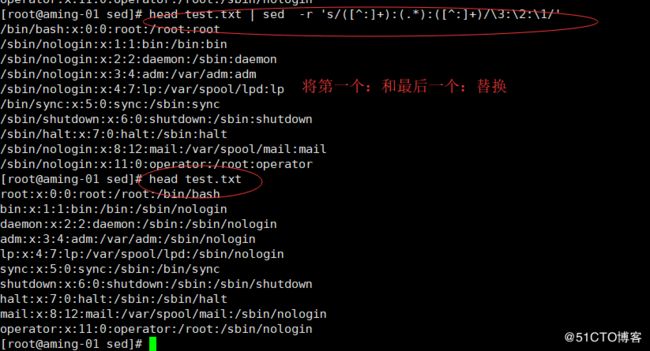
(2)替换

将第一个:和最后一个:调换
所有行前+aaa字符
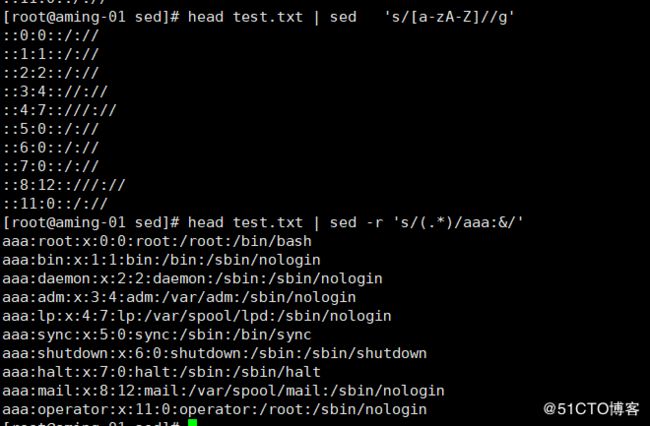
如果sed的表达式里面有了特殊符号,就要用上,否则你就得加\
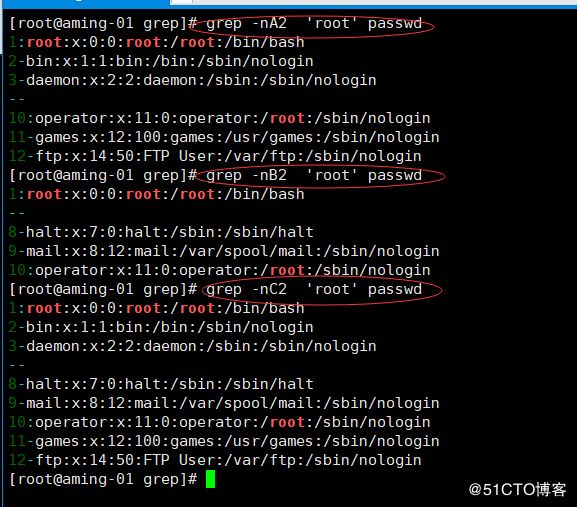
grep 的-r和这个sed不是一个意思。
==============================================================
9.6 awk(上)
支持分段打印 ,若未指定分隔符,默认以空格和空白字符打印。
(1)打印段
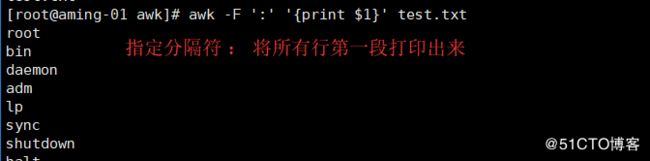
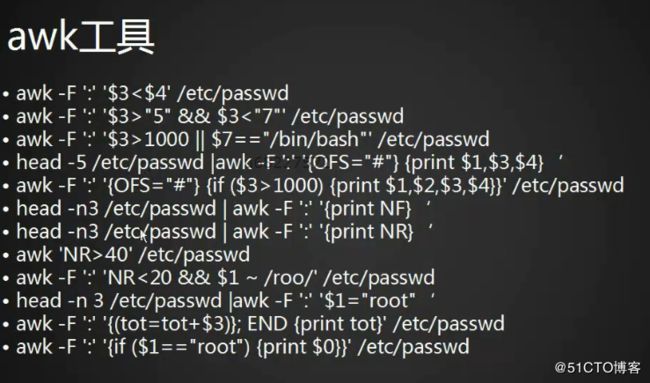
< awk '{print $1}' 1.txt> 不指定分隔符按默认
< awk '{print $2,$1}' 1.txt> 打印 列2和列1
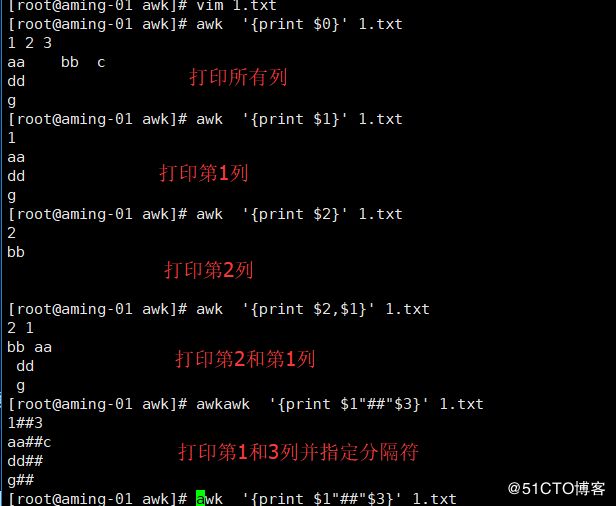
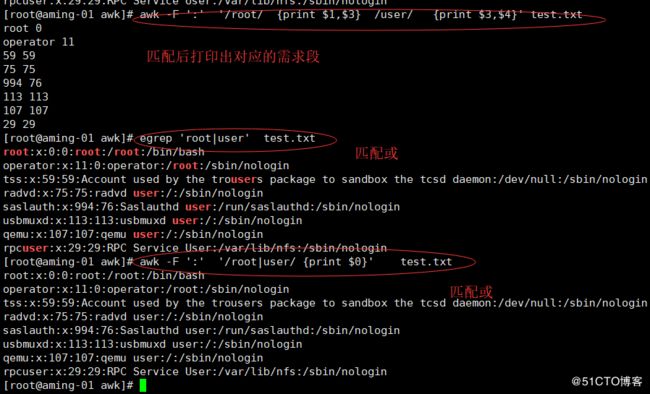
也支持 且不需要使用脱义字符 \
若匹配root打印1和3段,匹配user打印3和4段
加双引号是按ascill计算的
加上双引号后按普通的字符处理,不是数字了, 那么比较大小就是按 ASCII码来。
不加就是按常规数字,给你举一个例子:
常规数字 10>5
但按字符, 10<5 ,因为它排序的时候是一位一位的比较大小,10和5比较,实际上是1和5比较。
==============================================================
9.7 awk(下)
< awk -F ':' '{OFS="#"} {if($3>1000) print( $1,$3,$7)}' test.txt> 指定分隔符OFS

NR 行 NF 段
< awk -F ':' ' {print( NR":" $0)}' test.txt> 增加行号NR
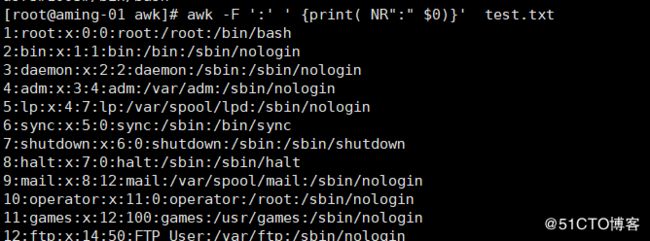
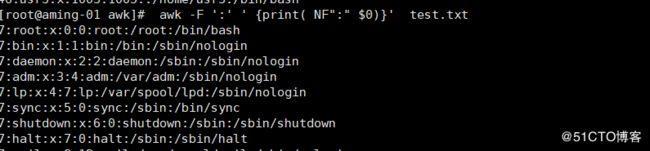
< awk -F ':' ' {print( NF":" $0)}' test.txt> 增加段号NF
< awk -F ':' 'NR<=10 && $1~/root|sync/' test.txt> 打印前10行包函root或sync
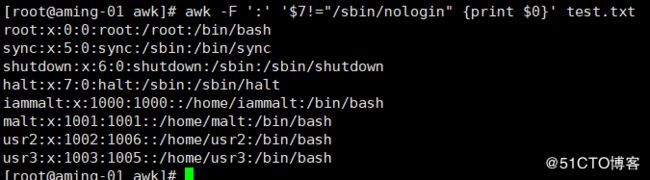
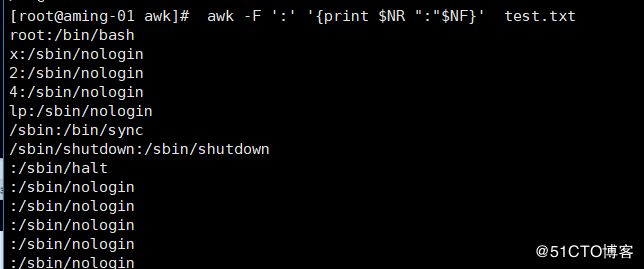
< awk -F ':' '{print $NR ":"$NF}' test.txt> 加$代表通配打印1-7,2-7……N-7,后面不存在就为空
awk 是按行处理文件的,每一行都有awk内置变量:NF,NR
NF:是按给定的分隔符,分出来总的段数, 所有$NF,指最后一段。
NR:是当前行的行号。$NR,表示 第N行的第N段。
老师的示例中,每行有7段,所以,前面7行,第一列,分别显示当前行的段。如第一行显示第一段,第二行显示 第二段,第三行显示 第三段。。。。
< awk -F ':' '{(tot=tot+$3)}; END {print tot}' test.txt> 将所有第3段求和
此处的for省略掉了
