SAM及其相关工具
SAM格式介绍
SAM全称是Sequence Alignment/Map, 是目前最常用的存放比对或联配数据的格式。无论是重测序,还是转录组,还是表观组,几乎所有流程都会产生SAM/BAM文件作为中间步骤,然后是后续专门的分析过程。
以一个简单的例子介绍.第一幅图表示read和参考基因组比对可能出现的情况。r001/2表示paired end数据。r003是嵌合read,r004则是原序列打断后比对结果。

经过专门的比对软件,如BWA,BOWTIE2等,得到的SAM文件如下所示,需要研究的就是如下这几行。

术语和概念
在学习SAM格式之前,请确认自己是否对如下概念有清楚的认识|
- read: 测序仪返回的原始序列.一个read可以包括多个segment。read之间的先后顺序表示被测序仪读到的时间前后关系.
- segment: 一段连续的序列或子序列
- linear alignment: 线性联配表示一个read比对到单个参考序列,可以存在插入,缺失,跳过(skip),剪切(clip), 但是不存在方向改变的情况(比如说一部分和正向链联配,另一个位置则是和负向链联配)。最简单的判断的方式就是,一个linear alignment只用一行记录。
- chimeric alignment: 嵌合联配需要多行记录。比如说r003第一个记录是后6个匹配,第二个记录则是反向序列的后5个匹配。第一个被称之为"representative",其他都是"supplementary"
- read alignment: 无论是linear alignment, 还是chimeric alignment, 只要能完整表示一个read,都成为是read alignment
- multiple mapping: 由于存在重复区,一个read 可能比对到参考基因组的不同区域。其中一个被认为是primary,其他都是secondary.
- 两个系统|1-based coordinate system(SAM,VCF,GFF,wiggle)和0-based coordinate system(BAM, BCFv2, BED, PSL).自行用R和Python感受一下两者的不同。
chimeric alignment 可能是结构变异,基因融合,参考序列误组装,RNA-Seq,实验protocol等因素造成。对于chimeric alignment的里面每一个linear alignment而言,由于相互之前不存在重叠,故而联配质量较高,适合用于SNP/INDEL calling.相反, multiple mapping则是因为重复造成(read越长出现的概率越低), 相互之间存在重叠,仅有其中一条有最优的匹配,其他联配质量过低会被SNP/INDEL caller忽略。
第一部分| SAM Header(非强制)
这个部分能够被/^@[A-Z][A-Z](t[A-Za-z][A-Za-z0-9]:[ -~]+)+$/或/^@COt.*/这两个表达式进行匹配。比如说你随便有一个BAM文件(包含header),就能被这个表达式进行匹配。
samtools view -h S43S1-M_H3K5FDMXX_L1_sort.bam
| awk '$0 ~ /^@[A-Z][A-Z](t[A-Za-z][A-Za-z0-9]:[ -~]+)+$/ { print $0}'

其中第一行@HD,表示参考基因组的排序情况. 然后@SQ则是参考基因组的每一条序列的具体信息,命名和长度。@PG记录运行的命令,以便你检查代码。对于GATK还需要提供@RG给出每个read所在group的信息,只要保证是独一即可。
第二部分| 联配必要信息
第二部分具体记录每一个read的联配结果,一共有11+n列。我将第二张图的信息复制保存到test.sam中,仅仅看第一行
samtools view test.sam | head -n1 | tr 't' 'n' | nl
1 r001 # QNAME: read信息
2 99 # FLAG: 信息量大
3 ref # RNAME: 参考序列
4 7 # POS:比对到的位置
5 30 # MAPQ: 比对质量
6 8M2I4M1D3M # CIGAR: 信息量大
7 = # RNEXT: 配对read所在序列,=表示同一条序列
8 37 # PNEXT: 配对read所在位置
9 39 # TLENT: 观察到的模板长度
10 TTAGATAAAGGATACTG # SEQ: segment序列
11 * # QUAL: segment的质量
# *表示信息不存在
简单解释TLENT: 通过IGV可视化展示克制,TLENT相当于read发现了参考序列那些区域。如果是PE数据还可以推断出文库平均大小。


详细介绍FLAG: FLAG的主要目的就是用较少的记录长度表示当前记录的序列的匹配情况。相当于开关,仅有有无两个状态,有某个数值就表示序列符合某个情况。
| flag | 代表 | 具体含义 |
|---|---|---|
| 1(0x1) | PAIRED | 代表这个序列采用的是PE双端测序 |
| 2(0x2) | PROPER_PAIR | 代表这个序列和参考序列完全匹配,没有插入缺失 |
| 4(0x4) | UNMAP | 代表这个序列没有mapping到参考序列上 |
| 8(0x8) | MUNMAP | 代表这个序列的另一端序列没有比对到参考序列上,比如这条序列是R1,它对应的R2端序列没有比对到参考序列上 |
| 16(0x10) | REVERSE | 代表这个序列比对到参考序列的负链上 |
| 32(0x20) | MREVERSE | 代表这个序列对应的另一端序列比对到参考序列的负链上 |
| 64(0x40) | READ1 | 代表这个序列是R1端序列, read1; |
| 128(0x80) | READ2 | 代表这个序列是R2端序列,read2; |
| 256(0x100) | SECONDARY | 代表这个序列不是主要的比对,一条序列可能比对到参考序列的多个位置,只有一个是首要的比对位置,其他都是次要的 |
| 512(0x200) | QCFAIL | 代表这个序列在QC时失败了,被过滤不掉了(# 这个标签不常用) |
| 1024(0x400) | DUP | 代表这个序列是PCR重复序列(#这个标签不常用) |
| 2048(0x800) | SUPPLEMENTARY | 代表这个序列是补充的比对(#这个标签具体什么意思,没搞清楚,但是不常用) |
举例说明,比如说实例中的99=64+32+2+1, 也就是这个记录所代表的read是来自于双端测序R1,且匹配的非常好,对应的另一条链匹配到了负链(自己是正链)。而147=128+16+2+1则是表示这个记录来自于双端测序的R2,完全匹配到负链. 如果是163和83,你会发现163=147-16+32, 83=99-32+16,也就是刚好和前面的不同,也就是说R1匹配负链,R2匹配正链。如果是81和161,由于161=163-2,81=83-2. 表明这些read不是完全匹配,存在插入缺失
那么问题来了,如下是我某一次比对的flag的统计情况,你能看出什么来
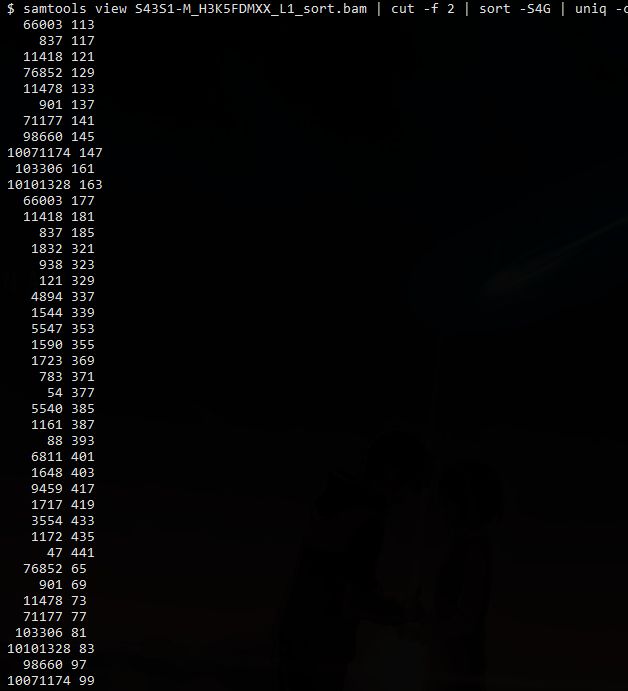
常见的FLAGs:
- 其中一条reads没有map上: 73, 133, 89 121, 165, 181, 101, 117, 153, 185, 59, 137
- 两条reads都没有map上: 77,141
- 比对上了,方向也对,也在插入大小(insert size)内: 99, 147, 83, 163
- 比对上了,也在插入大小(insert size)内, 但是反向不对:67, 131, 115, 179
- 单一配对,就是插入大小(insert size)不对: 81, 161, 97, 145, 65, 129, 113, 177
FLAG仅仅存储比对的大致情况,每条比对上的read的实际情况则是要用CIGAR进行记录. 依旧举几个例子,比如说,这是双端测序的一条read比对情况,其中一个是117表示没有匹配上,所以记录就是*,另一个是185表示这条序列完美匹配,所以记录是150M.
ST-E00600:109:H3K5FALXX:2:1103:17996:34788 117 Chr1 38 0 * = 38 0 TTTATACACTATGATTTTCAAAGTGAGAATCCGGTTTGTGGTTTATTGTTTTAGGTATTTAGTTATTAATGTATTTTGGATTTATTGATTTAGTGTTTTAGTGATTAATTATTCATTGTTTTAGTGTTTATGGTTTAGTGTTTAGGGTTT J-7-J------JJJ7JJJ-J-J---JJ-----JJJJJ--J-JJJJ-----JJ--JJJJJJ-J--JJJ7JJ-7-J-J-777JJJJ777JJ7JJ77J7JJJJ7777JJ77777JJJ777J77J77J7JJJJ77JJJJJJJ7JJJJJJFFFAA MC:Z:150M AS:i:0 XS:i:0
ST-E00600:109:H3K5FALXX:2:1103:17996:34788 185 Chr1 38 60 150M = 38 0 CATTAATCCCTAAATCCCTAAATCTTTAAATCCTACATCCATGAATCCCTAAATAACTAATTCCCTAAACCCGAAACCTGTTTCTCTGGTTGAAAATCATTGTGTATATAATGATAATTTTATCGTTTTTATGTAATTGCTTATTGTTTT J-JJ7JJJ-JJJ7JJ--JJJ--JJ-JJJJJJ-JJJJJJ--J-JJJJJJJJJ--JJ-JJJJJJJ-JJJJ--J----J-J--JJJJJJ777JJJ77J7JJJJJJJ7JJJJJ7JJJJJ77JJJJJJ7JJ7JJJ7JJJJJJJJJJJJJJFFF来一个复杂的例子69H10M3I31M37H,表示150bp的读长,先删掉69个碱基,后面是10个匹配,后面相比较参考基因组有3个插入,随后是31个匹配,最后再剔除37个基因,通过IGV查看在参考基因组的情况如下图所示。

我还发现这段区域存在特别多的clip,加载GFF查看注释信息后发现这是内含子区域。

实际上,CIGAR一共有9个字符,分别是M(alignment match),I(insertion),D(deletion),N(skip),S(soft clip),H(hard clip),P(padding),=(sequence match), X(sequence mismatch).值得提醒就是M表示序列能够联配,但是存在碱基不一致,=表示碱基相同。S和H一般用于read前后出现大部分的错配,但是中间能够联配的情况,其中S表示序列会出现在SEQ中,H则不会出现在SEQ列中。
第三部分,可选信息
除了之前的11列必须要有的信息外,后面的其他列都是不同的比对软件自定义的额外信息,称之为标签(TAG)。标签的格式一般为TAG:TYPE:VALUE,比如说NM:i:4 MD:Z:1C53C22G69G1 AS:i:136 XS:i:0。这部分内容见http://samtools.github.io/hts-specs/SAMtags.pdf. 介绍几个比较常见的标签
- NM: 编辑距离(edit distance)
- MD: 错配位置/碱基(mismatching positions/bases)
- AS: 联配得分(Alignment score)
- BC: 条码序列(barcode sequence)
- XS: 次优联配得分(suboptimal alignment score)
能用于处理SAM格式的工具们
后续演示所用数据通过如下方法获取
# efetch下载参考基因组
mkdir -p ~/biostar/refs/ebola
cd ~/biostar
efetch -db=nuccore -format=fasta -id=AF086833 > ~/refs/ebola/1976.fa
REF=~/biostar/refs/ebola/1976.fa
# 构建索引
bwa index $REF
bowtie2-build $REF $REF
# 获取10000行的fastq PE数据
mkdir -p ~/biostar/fastq
cd ~/biostar/fastq
fastq-dump -X 10000 --split-files SRR1972739
R1=~/biostar/fastq/SRR1972739_1.fastq
R2=~/biostar/fastq/SRR1972739_2.fastq
处理SAM的命令行工具有samtools,bamtools,picard,sambamba,samblaster等,其中samtools和bamtools和picard比较全能,功能中存在重叠,更多是互补,而sambamba和samblaster则是运行速度更快,功能不太全。
使用SAMtools创建SAM,BAM和CRAM
SAM格式是目前用来存放大量核酸比对结果信息的通用格式,也是人类能够“直接”阅读的格式类型,而BAM和CRAM是为了方便传输,降低存储压力将SAM进行压缩得到的格式形式。 为了高效处理SAM文件,李恒写了配套的SAMtools, 文章在2009年发表在bioinformatics上,由于samtools的版本经常更新,如果有些工具用不了,你或许要更新版本了。
如果不加任何其他参数,比对软件就能得到“标准”的SAM格式的文件。
bwa mem $REF $R1 $R2 > bwa.sam
bowtie2 -x $REF -1 $R1 -2 $R2 > bowtie.sam
原始SAM格式体积又大,没有排序,不利于后续的分析操作,所以需要经过几步的格式转换成为BAM。1.3版本之后的samtools可以一步进行格式转换和排序.
注,BAM格式必须要建立索引才能快速读取指定位置的信息。
# 1.3版本前
samtools view -bS bwa.sam > bwa.bam
samtools sort bwa.bam > bwa_sorted.bam
samtools index bwa_sorted.bam
# 1.3版本后
samtools sort bwa.sam > bwa_sorted.bam
samtools index bwa_sorted.bam
CRAM是比BAM压缩更加高压的格式,原因是它是基于一个参考序列,这样子就能去掉很多冗余的内容。
samtools sort --reference $REF -O cram bwa.sam > bwa.cram
samtools index bwa.cram
这一小节学习了两个samtools子命令:sort和index,前者能一边排序一边进行格式转换,后者则是对BAM进行索引。
使用SAMtool查看/过滤/转换SAM/BAM/CRAM文件
上一节得到的SAM/BAM/CRAM文件都可以用samtools的view进行更加复杂的操作,只不过要注意读取CRAM格式需要提供参考序列,不然打不开。
samtools view bwa_sorted.bam
samtools view -T $REF bwa.cram
samtools的view在增加额外参数后能实现更多的操作,比如说SAM和BAM/CRAM之间的格式转换(-b, -c, -T),过滤或提取出目标联配(-t,-L ,-r,-R,-q,-l,-m,-f,-F,-G), 举几个例子说明
# 保留mapping quality 大于 10的结果
samtools view -q 10 bwa_sorted.bam -b -o bwa_sorted_mq10.bam
# 统计结果中恰当配对的结果(0x3 3 PARIED,PROPER_PAIR)
samtools view -c -f 3 bwa_sorted.bam
# 或反向选择
samtools view -c -F 3 bwa_sorted.bam
使用PrettySam更好的可视化SAM文件
尽管我上面说SAM是适合人类阅读的数据,但是直接读SAM还是挺费脑子的。GitHub上有一个PrettySam能够更好的展示SAM/BAM文件,虽然感觉没多大实际效果,但是有利于我们方便了解SAM格式,项目地址为http://lindenb.github.io/jvarkit/PrettySam.html.
他的安装比较麻烦,需要JDK版本为1.8且是Oracle, 以及GNU Make >=3.81, curl/wget, git 和 xslproc.安装如下
git clone "https://github.com/lindenb/jvarkit.git"
cd jvarkit
make prettysam
cp dist/prettysam.jar ~/usr/jars/
使用起来非常简单,效果也比较酷炫,比较适合演示用。
java -jar usr/jars/prettysam.jar ~/biostar/ebola.sam --colors

为SAM/BAM添加Read Groups
使用GATK分析BAM文件时需要BAM文件的header里有RG部分,@RG至少由三个记录(ID,LB,SM)组成,需要根据实际情况增加。RG可以在前期比对时添加RG部分,也可以在后续处理时增加
TAG='@RG\tID:xzg\tSM:Ebola\tLB:patient_100'
# Add the tags during alignment
bwa mem -R $TAG $REF $R1 $R2 | samtools sort > bwa.bam
samtools index bwa.bam
# Add tags with samtools addreplacerg
samtools addreplacerg -r $TAG bwa_sorted.bam -o bwa_sorted_with_rg.bam
参考资料
- Sequence Alignment/Map Format Specification
- SAM tags