1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
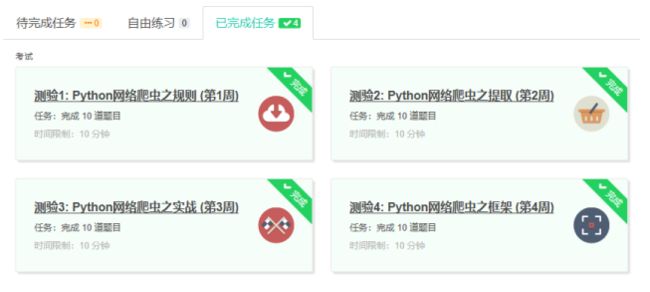
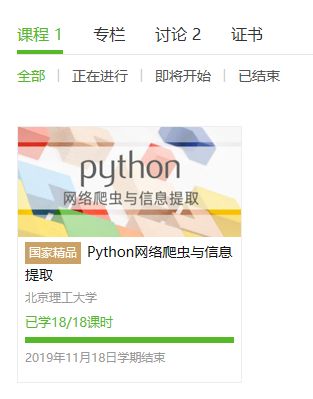
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
通过这几周的学习,大概了解了python网络爬虫和信息提取的相关知识。嵩天老师主要讲了这几点:
1. Requests库:自动爬取HTML页面以及网络请求提交
2.Robots.txt:网络爬虫排除标准
3.Beautiful Soup库:解析HTML页面
4.Re库:正则表达式详解以及提取页面关键信息
5.Projects:实战项目A/B
6.Scrapy库:网络爬虫原理介绍以及专业爬虫框架介绍
第一周老师主要让我们了解Requests库的入门,比如Requests库的安装,Requests库的7种主要方法,其中主要讲了Requests库的get()方法,还有要理解Requests库的异常等等。还让我们了解了什么是网络爬虫,让我们对爬虫有进一步的了解。介绍了Robots协议,为了让我们更明白,还举了京东的例子,更加清晰易懂。在第三单元中举了Requests库中爬虫的五个例子,我也跟着老师也操作起来了,以爬虫的视角看待网络内容。
第二周老师主要讲了Beautiful Soup库的安装、理解与引用。还讲了Beautiful Soup库的基本元素、基于bs4库的HTML内容遍历方法及格式化和编码、信息组织与提取方法。在第六单元是时候也举了中国大学排名爬虫的例子,让我这个小白也能看懂一些大概。
第三周则是网络爬虫的实战,介绍了Re库的基本概念,还讲了正则表达式,它是用来简洁表达一组字符串的表达式,最主要应用在字符串匹配中,其语法由字符和操作符构成。其中七八两个单元有采用requests-re路线淘宝商品比价定向爬虫,熟练掌握正则表达式在信息提取方面的应用。用requests-bs4-re实现了股票信息爬取和存储,实现了展示爬取进程的动态滚动条。让我更加了解。
第四周老师主要讲了网络爬虫的框架。其中讲了Scrapy的安装及框架结构,爬虫框架是实现爬虫功能的一个软件结构和功能组件的集合,能够帮助用户实现专业的网络爬虫。所以,要学好网络爬虫,对其爬虫框架的学习必不可少。Scrapy框架就是“5+2结构”,即Engine、Downloader、Scheduler、Downloader Middleware、Spider、Item pipelines、Spider Middleware。还讲了Scrapy爬虫的数据类型,其中有Request类、Response类和Item类。通过老师的讲解与学习,我对Scrapy爬虫有了初步认识和理解,为以后学习新的爬虫知识奠定了坚实基础。其中也讲到了股票数据Scrapy爬虫的编写。
通过这几周的学习,嵩天老师讲的很通彻。把大概的都讲了,我也明白了什么是爬虫,以后别人问我我也不是一问三不知了,我会告诉他们什么爬虫。老师讲的课程让我受益匪浅。