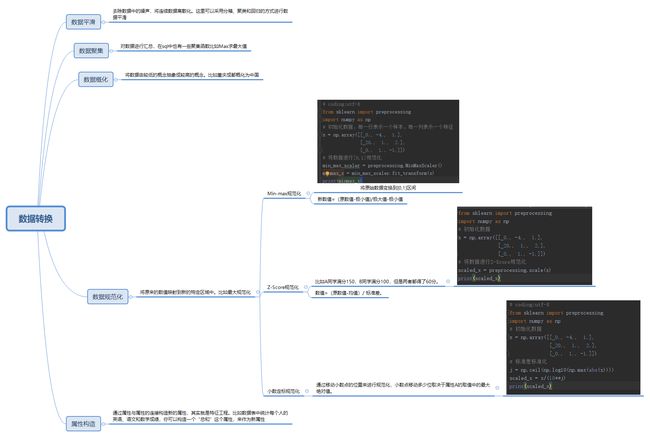
1数据转换
数据转换时数据准备的重要环节,它通过数据平滑,数据聚集,数据概化,规范化等凡是将数据转换成适用于数据挖掘的形式
1.1 数据平滑
去除数据中的噪声,将连续数据离散化。这里可以采用分箱、聚类和回归的方式进行数据平滑
1,2 数据聚集
对数据进行汇总,在sql中也有一些聚集函数比如Max求最大值
1.3 数据概化
将数据由较低的概念抽象成较高的概念。比如重庆成都概化为中国
1.4 数据规范化
将原来的数值映射到新的特定区域中。比如最大规范化
1.5 属性构造
通过属性与属性的连接构造新的属性,其实就是特征工程。比如数据表中统计每个人的英语、语文和数学成绩,你可以构造一个“总和”这个属性,来作为新属性
2 规范化方法
(1) Min-max规范化
将原始数据变换到[0,1]区间
新数值=(原数值-极小值)/极大值-极小值
(2)Z-Score规范化
比如A同学满分150,B同学满分100,但是两者都得了60分。
数值=(原数值-均值)/ 标准差。
(3)小数制定规范化
通过移动小数点的位置来进行规范化,小数点移动多少位取决于属性A的取值中的最大绝对值。
3 Scikit-Learn使用
(1)官网
https://sklearn.apachecn.org/
(2)Min-max规范化使用
1 # coding:utf-8 2 from sklearn import preprocessing 3 import numpy as np 4 # 初始化数据,每一行表示一个样本,每一列表示一个特征 5 x = np.array([[ 0., -4., 1.], 6 [ 20., 1., 2.], 7 [ 0., 1., -1.]]) 8 # 将数据进行[0,1]规范化 9 min_max_scaler = preprocessing.MinMaxScaler() 10 minmax_x = min_max_scaler.fit_transform(x) 11 print(minmax_x)
(3)Z_Score使用
1 from sklearn import preprocessing 2 import numpy as np 3 # 初始化数据 4 x = np.array([[ 0., -4., 1.], 5 [ 20., 1., 2.], 6 [ 0., 1., -1.]]) 7 # 将数据进行Z-Score规范化 8 scaled_x = preprocessing.scale(x) 9 print(scaled_x)
(4)小数点规范化
1 # coding:utf-8 2 from sklearn import preprocessing 3 import numpy as np 4 # 初始化数据 5 x = np.array([[ 0., -4., 1.], 6 [ 20., 1., 2.], 7 [ 0., 1., -1.]]) 8 # 标准差标准化 9 j = np.ceil(np.log10(np.max(abs(x)))) 10 scaled_x = x/(10**j) 11 print(scaled_x)
4 思维导图
5 总结
为了寻找数据的规律,需要将其规范化。那么目前知道有三种方法,分别为Min-max规范化,Z-Score规范化,小数制定规定化等。