作者:炸鸡可乐
原文出处:www.pzblog.cn
一、问题描述
经常有些面试官会问,是否了解过 HashMap 在多线程环境下使用时可能会发生死循环,导致服务器 cpu 100% 的线上故障?
关于这个问题,很多年前,在淘宝内网里就有很多的程序员发过这种帖子说一个CPU 被100%了,原因竟是多线程环境下使用 HashMap 造成的死循环,并且这个事发生了很多次。
虽然 Java 官方明确表示,在多线程环境下不推荐使用 HashMap,但是对于这种问题,小编其实也比较意外,如果不是深入的去了解 HashMap,都不知道有这样的问题。
为什么会产生死循环呢?下面我们来还原一下问题的经过。
二、问题重现
在之前的集合系列文章中,我们了解到 HashMap 是一个哈希数组 + 链表的数据结构,在实际的程序开发中,我们经常会使用到 HashMap,如果对 HashMap 不是很了解,大家可以看小编之前写的《深入浅出分析 HashMap 》一文。
HashMap 是一个非线程安全的集合操作类,如果我们的程序操作是单线程的,那么一切都没问题。当我们的程序是多线程操作 HashMap 类时,那么问题就来了,我们一起来复现一下。
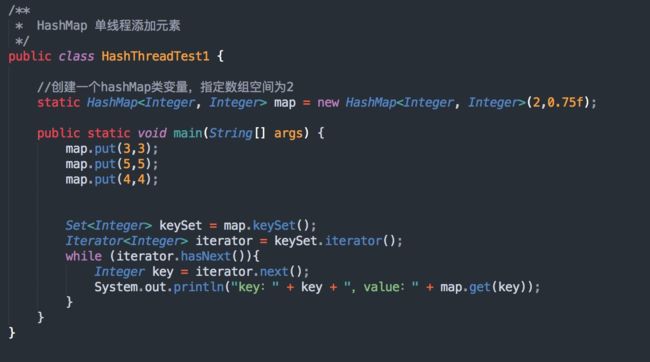
测试代码,如下:
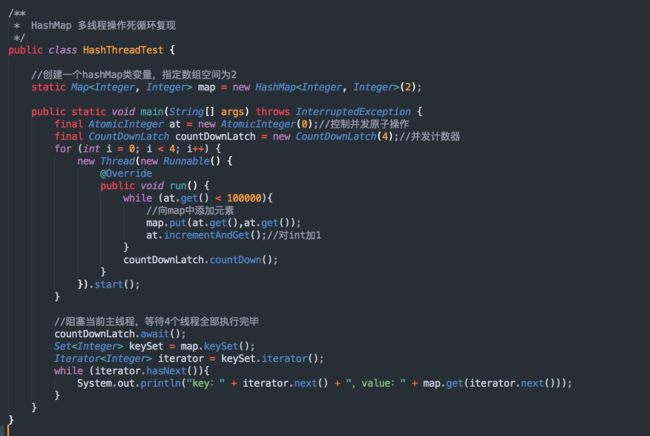
使用了4个线程来向 HashMap 中添加元素,可能一次运行不一定有效果,可以反复运行几次!
控制台输出结果:

可以清晰的看到,在遍历 map 的内容时,已经死循环了!
再来看看,活动监视器,结果如下:
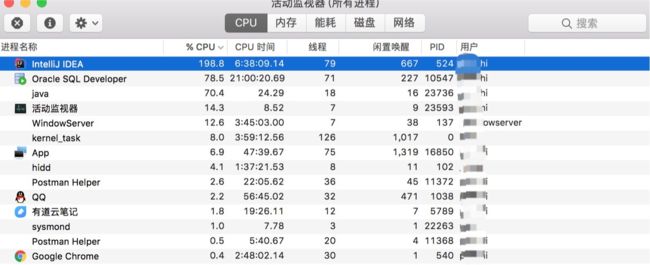
cpu 的使用率,直接接近 200%!
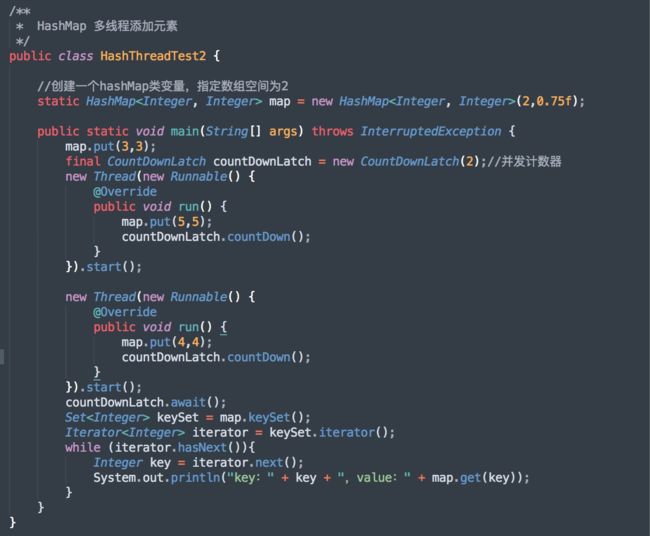
接下来我们去查看下 java 中刚刚运行的 HashThreadTest 类堆栈情况:
可以看到,HashMap 的扩容操作导致了死循环!
通过测试,我们发现 HashMap 在多线程环境下进行操作,的确会产生死循环,并且会导致 CPU 100%!
这是为什么呢?我们一起来阅读一下源码!
三、源码阅读
注意注意,小编在进行测试的时候,使用的是 JDK1.7 的版本!
如果你使用 JDK1.8 的版本,不好意思,不一定能复现这个问题!因为 JDK1.8 已经修复了这个问题,但是依然不建议在多线程环境下使用 HashMap!
我们继续来看看为什么使用 JDK1.7 会出现这个问题!
既然是 put 阶段造成的数据问题,我们不妨一起来看看 HashMap 的 put 过程!
3.1、HashMap 添加过程
HashMap 的 put 源码实现如下:
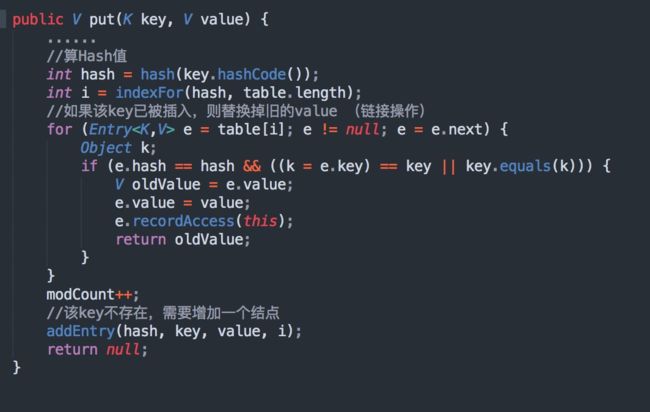
接着我们来看看addEntry()方法,将元素插入到数组中,并且检查容量是否超标,源码实现如下:

上面例子中,我们初始化的时候给定的容量是 2,所以在添加元素时必定会扩容!如果超出阀值,就进行扩容处理,创建一个更大容量的 hash 表,然后把从老的 Hash 表中迁移到新的 Hash 表中,源码如下:

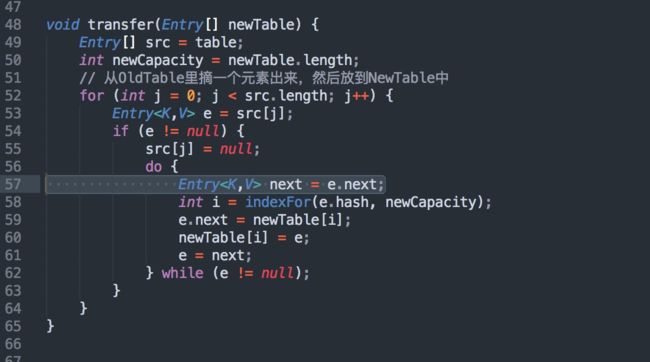
将旧 hash 表中的元素复制到新的 hash 表中,源码如下:
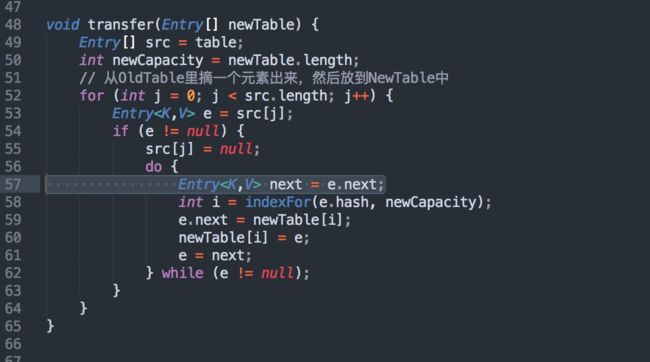
整个 put 过程,大致可以分如下几个步骤:
- 第一步是通过 key 计算出来的 hash 和 equals 来判断元素是否存在,如果存在,直接覆盖;反之,插入;
- 第二步是将元素插入到 hash 表中,如果不同的元素都在一个 hash 数组下标下,就以链表的形式,采用头插法存储在 hash 节点下;
- 最后就是判断当前数组容量是否大于扩容阀值,如果大于,就进行扩容处理,然后将旧元素复制到新的数组中;
好了,这个过程基本上没啥问题。
我们再来演示一下扩容中重新计算元素 hash 的过程!
3.2、单线程下扩容元素 hash 过程
假设在单线程环境下,我们初始化的时候,给定的数组容量是2,分别添加3个元素,内容如下:
- key=3,value=A;
- key=4,value=B;
- key=5,value=C;
源码如下:
添加完成之后,数组就会进行扩容处理,扩容后 hash 的容量为原来的2倍,扩容操作流程如下:
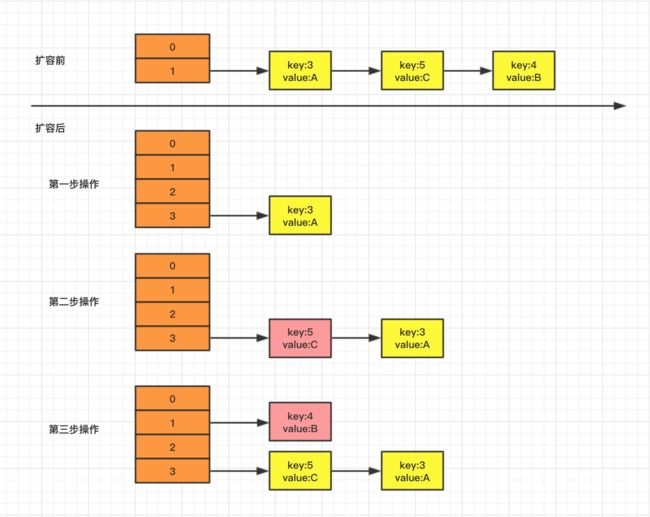
在单线程环境下,一切看起来都很正常,扩容过程也相当顺利。接下来我们看下并发情况下的扩容。
3.3、多线程扩容元素 hash 过程
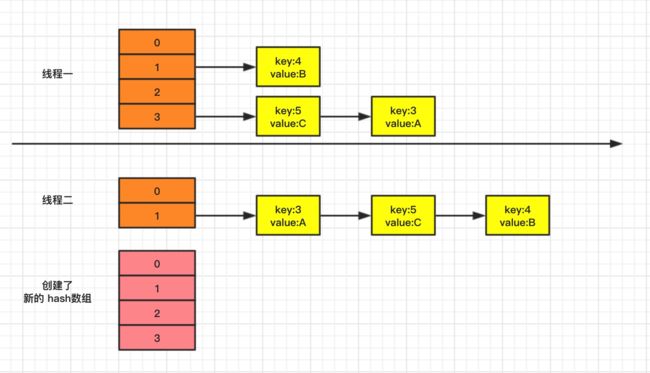
假设我们有两个线程,来分别添加3个元素。
线程二执行完添加任务之后,在准备将旧元素迁移到新元素的时候,也就是准备 rehash 时,突然被 CPU 挂起,此时阻塞在如下图中的第57行,不再往下执行!而线程一继续执行直到扩容完成。
2个线程此时的执行结果,内容如下:
接着线程二被唤醒,继续回到第57行执行。
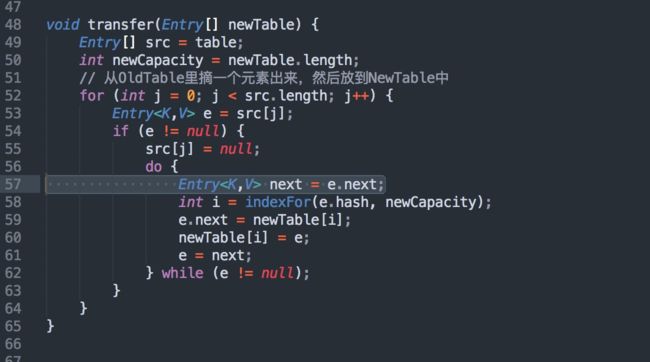
此时注意了,我们来详细的分析一下这个过程!
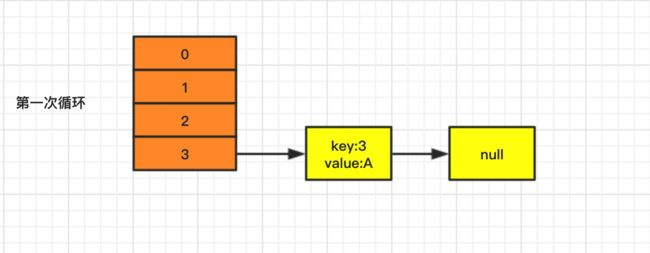
第一次循环过程如下:
- 第1步:
此时 e 等于{key:3,value:A},next=e.next={key:5,value:C}; - 第2步:
通过 key 重新 hash 计算得到下标 i = 3; - 第3步:
newTable为局部变量,内容都为null,所以 e.next = newTable[i]=null; - 第4步:
newTable[i]=e={key:3,value:A}; - 第5步:
e=next={key:5,value:C};
循环结果如下,e={key:5,value:C},满足while()循环条件,接着继续!
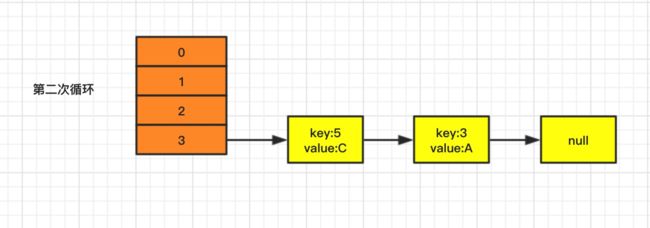
第二次循环过程如下:
- 第1步:
此时 e 等于{key:5,value:C},取最新的链表结构,next=e.next={key:3,value:A}; - 第2步:
通过 key 重新 hash 计算得到下标 i = 3; - 第3步:
在第一次循环中,newTable[i]已经插入值,所以 e.next = newTable[i]={key:3,value:A}; - 第4步:
newTable[i]=e={key:5,value:C}; - 第5步:
e=next={key:3,value:A};
循环结果如下,e={key:3,value:A},满足while()循环条件,接着继续!
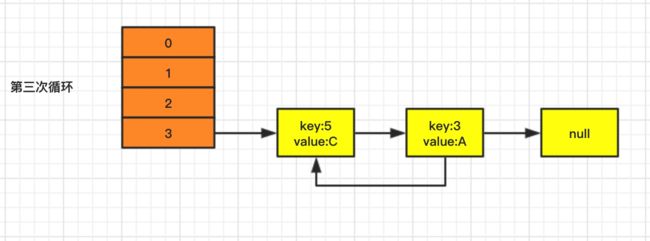
第三次循环过程如下:
- 第1步:
此时 e 等于{key:3,value:A},取最新的链表结构,next=e.next=null; - 第2步:
通过 key 重新 hash 计算得到下标 i = 3; - 第3步:
在第二次循环中,newTable[i]已经插入值,所以 e.next = newTable[i]={key:5,value:C}; - 第4步:
newTable[i]=e={key:3,value:A}; - 第5步:
e=next=null;
循环结果如下,e=null,while()程序不在循环!
综合线程1、线程2执行结果,最终 hashMap 的存储结果,如下图:
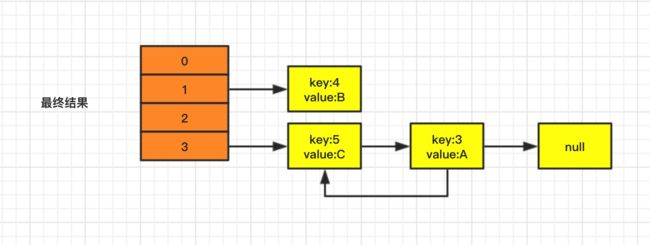
可以很清晰的看到,链表发生死循环了!
于是,当我们在遍历 hashMap 链表内容的时候,就会出现上文中问题复现的场景,死循环式的输出相同的内容,CPU 直接飙到200%了!
对于这种问题,当初有人上报到 SUN 公司,但是 SUN 不认为这是一个问题,因为 HashMap 本来就不支持并发操作!
所以,不建议在多线程环境下使用 HashMap,那如果要在多线程环境下使用 map 操作类,该怎么办呢?
四、解决办法
办法肯定是有的,如果大家想在多线程场景下使用 HashMap,有两种解决办法:
- 第一种,推荐使用并发包中的 ConcurrentHashMap 类,一种使用分段锁的 hashMap 类,在之后的文章中,咱们也会介绍到它。
- 另一种,是使用
Collections.synchronizedMap(Mao工具方法,将 HashMap 变成一个线程安全的 map,其实就是对 map 中的方法进行加锁处理,保证多线程下操作安全!
五、参考
1、JDK1.7&JDK1.8 源码
2、coolshell -陈皓 - JAVA HASHMAP的死循环