为了生成OCR识别中需要用到的字库,查阅了网上很多文章,感觉都写的很凌乱,有的用到很多工具,有的用命令行,看的昏昏然;
在自己尝试后发现,发现训练字库没那么麻烦,只需一个工具就够了,请到如下页面下载:
https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
本篇使用的jTessBoxEditor-1.7.2.zip这个版本(什么,你下了src那个版本?那特么是源码!)
目录概览(4个步骤,很简单吧):
1、准备用于识别训练的 tif 图片资源;
2、生成 tif 对应的 box;
3、微调识别结果;
4、生成字库。
第一步:准备 tif 文件
PS:tiff只是一种图片格式(如果你理解不了,就认为它是png或jpg好了)
获得方法:在jgp或png图片上右键-->>编辑:

用系统画图打开图片,然后另存为,点击其他格式:
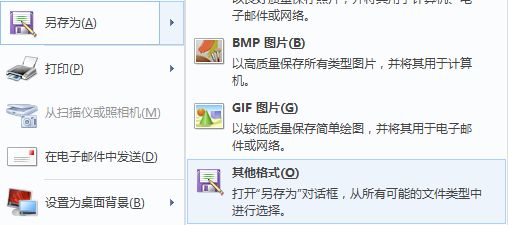
然后选择生成tiff格式及另存为的路径:

如果你有多张图片则需要进行合并tiff,点击tools--->>>Merge Tiff:

选择你需要合并的多张tif图片,点击打开:

弹出如下保存路径/名称的对话框,选择合适的保存路径,在文件名处填写好合成后的文件名,点击保存:

在类似下图的路径中,创建自定义文件夹,把生成的tiff文件放在里面:

放的位置不对会报错,见第三步的错误,而且自定义文件夹比较方便管理
第二步:生成Box
点击jTessBoxEditor---Trainer选项卡:
选择好正确的 tesseract.exe 路径:

设置 Language(自定义字库名字,后面要用,我这里用的是CK) ,然后选择 MakeBoxFileOnly;
点击 Run 按钮,下面 Training completed 这样就是 box 文件生成好了:

出现下图错误(log说的很清楚你的数据文件存放路径不对,参考第二步的存放路径后再次 Run)

第三步:微调识别效果---这个步骤真的不难,但真的是个力气活
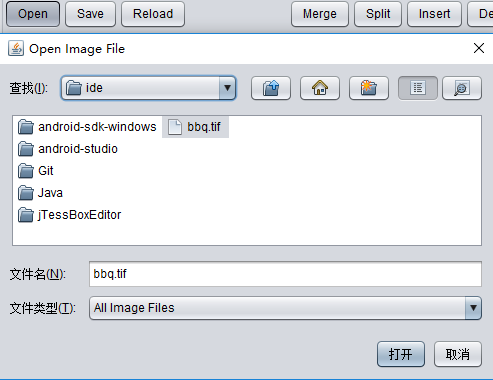
切换到 BoxEditor 选项卡:点击 open-->>加载刚才那个已经生成了 box 文件的 tif 文件,点击打开:
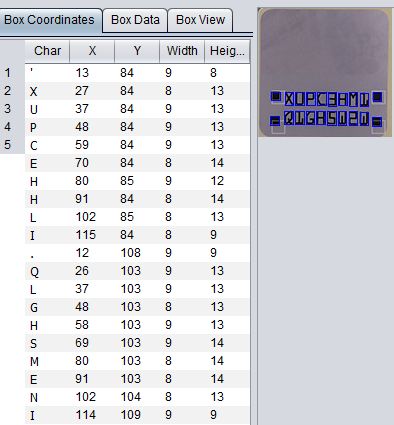
一般情况下,识别出是下图这样的:
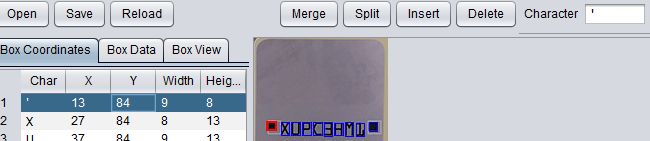
这时候可以在最左边点击选择识别出的图形块,在右边Character里输入正确的字符,回车即可:
如果图形有多个字符识别成了一个,可以点击split进行拆分;
不想要的字符,比如我这里的黑点,点击Delete ;
merge不用说就是识别出的多个图形块你可以合并成一个。
然而,我这图片有时候会像下图这样,完全识别不出怎么办:
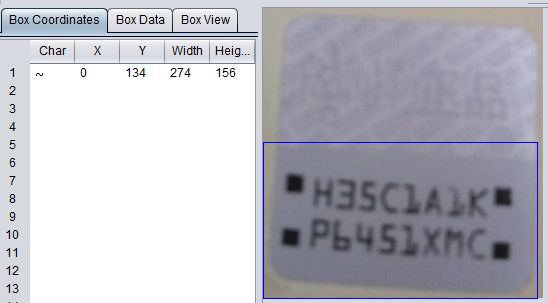
这个整块的大框框千万别Delete掉,不然就没法操作了;
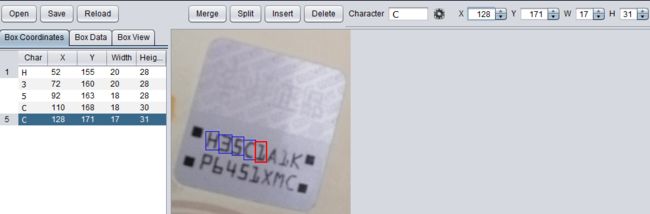
在右边设置大框框的 X Y W H 这四个值,让他作为你的第一个识别小块,
刚才还有Insert没介绍,点击它之后,就插入一个识别块,
【插入要选择一个起始块,这就是刚才大框框不能删除的原因,删了就gameover没法插入了】
插入的这个识别块也是通过设置 X Y W H 这四个值来操作的,
懒的话就直接点击它们后面的上下符号(而且这样比较精确)。
如下图(这是个辛苦活儿啊):
注意深坑:每张 tif 图片里最少有一个识别块,不然下一步生成字库的时候会报错!!!
BoxEditor选项卡页面的操作都别忘记保存(就是那个Save按钮),不然.....你懂的....呜呜呜
第四步:生成字库文件
切换到 Trainer 选项卡,选择 Train with Existing Box:
Run一下:
如果出现下列log,就成功了:【说的很明白:生成字体文件到tessdata文件夹了】
** Moving generated traineddata file to tessdata folder **
** Training Completed **
我们去文件夹看看,此时恍然大悟,原来生成的字库的文件名就是自定义的那个Language名字:
OK,这就是我们训练到的字库文件了。
如果 Run 后报错了:
没关系,此时已经生成了几个文件,在自定义文件夹下,
用文本编辑器打开.font_properties 文件 , 按照下面格式按照需求编辑
font_properties ----
【我的是: CK 0 0 0 0 0 回车符 ,意思是斜体、粗体等待设置全 false】
保存后,再次Run,然后就愉快的拷贝到项目中使用吧。
可选功能
生成tif文件和box文件也可以用这个选项卡的功能来做:

合并字库
后续需要合并字库的操作请参照tdhao的博客:(用命令,cd打开、d:切换盘符、dir列表当前文件夹、Tab键提示补全)
http://www.cnblogs.com/tdhao/p/5451813.html
安卓开发交流:
