我们都知道很多数据都可以通过爬虫进行爬取,如果我们爬取的是一个简单的页面,那么很轻松就可以实现了,如果要爬取动态页面,那么怎么办呢?
比如说我们要爬取东方财富网站上面的这些股票信息:
http://quote.eastmoney.com/center/list.html#10_0_0_u?sortType=C&sortRule=-1
但是我们查看源码的时候却看不到任何关于股票信息的数据,可以看出这些股票数据是异步加载的,果断F12打开chrome开发者工具,在Network选项中查看,如果没有的话可以F5刷新一下页面就出来了。
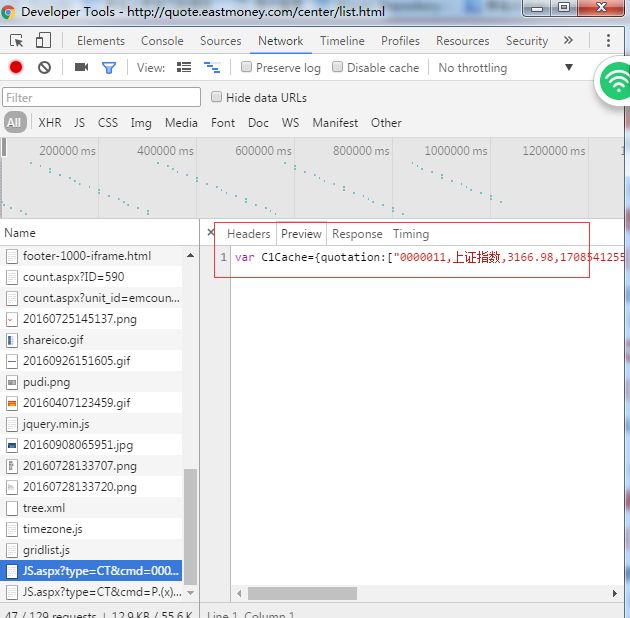
然后点击那个异步的api,会新打开一个页面,出现以下的数据:
var C1Cache={quotation:["0000011,上证指数,3166.98,170854125568,13.89,0.44%,876|201|246|142,1380|270|360|204","3990012,深证成指,10130.12,215605108736,74.55,0.74%,876|201|246|142,1380|270|360|204"]}
本以为是一个json的数据,但是服务端传来的是一个js变量,值类似一个json数据,这应该是为了开发的方便,但是我们要的是json的数据,所以需要过滤一下,split("=")然后取右边的字符串就行了,但是需要注意下,这个右边的不是json数据,注意json的key需要有双引号(在java中和python中),或许在js下有没有都可以吧,所以我们在java中还需要replace一下,这样才是一个json字符串,然后转换成json对象,可以用jackson的 objectmapper,反正方法很多。然后把这些数据持久化到数据库就可以了,这样我们就实现了一些动态页面的爬取。
但是这里需要注意的就是,有些网站不允许你跨域去访问,即使你通过伪装服务端还是有对策来防止你直接调用api,那么这个时候就需要用另一种方法,webmagic selenium,这个的原理就是,先运行一个浏览器内核去加载这个页面,等到整个页面加载完后再获取html代码,然后进行处理。
比如说我们要爬取上交所的浦发银行这支股票背后的公司信息,http://www.sse.com.cn/assortment/stock/list/info/company/index.shtml?COMPANY_CODE=600000
我们查看异步加载的api的时候,发现不允许你直接的访问这个api,所以只能用第二种方法了。
下面是项目的依赖:
compile 'us.codecraft:webmagic-core:0.5.3'
compile('us.codecraft:webmagic-extension:0.5.3')
compile 'org.seleniumhq.selenium:selenium-java:2.8.0'
compile group: 'us.codecraft', name: 'webmagic-selenium', version: '0.5.2'
源码如下:
public class CompanyProcessor implements PageProcessor {
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(3000)
.setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36");
public void process(Page page) {
WebDriver driver = new ChromeDriver();
driver.get("http://www.sse.com.cn/assortment/stock/list/info/company/index.shtml?COMPANY_CODE=600000");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
WebElement webElement = driver.findElement(By.id("tableData_stockListCompany"));
// WebElement webElement = driver.findElement(By.xpath("//div[@class='table-responsive sse_table_T05']"));
String str = webElement.getAttribute("outerHTML");
System.out.println(str);
Html html = new Html(str);
System.out.println(html.xpath("//tbody/tr").all());
String companyCode = html.xpath("//tbody/tr[1]/td/text()").get();
DateFormat format = new SimpleDateFormat("yyyy-MM-dd");
String dateString = html.xpath("//tbody/tr[3]/td/text()").get().split("/")[0];
String stockCode = html.xpath("//tbody/tr[2]/td/text()").get().split("/")[0];
String name = html.xpath("//tbody/tr[5]/td/text()").get().split("/")[0];
String department = html.xpath("//tbody/tr[14]/td/text()").get().split("/")[0];
System.out.println(companyCode);
System.out.println(stockCode);
System.out.println(name);
System.out.println(department);
driver.close();
}
public Site getSite() {
return site;
}
public static void main(String[] args) {
Spider.create(new CompanyProcessor())
.addUrl("http://www.sse.com.cn/assortment/stock/list/info/company/index.shtml?COMPANY_CODE=600000")
.thread(5)
.run();
}
}
这里面有一些webmagic的知识,如果不熟悉的可以看一下中文文档,因为这个爬虫框架是中国人写的,所以中文文档很详细http://webmagic.io/docs/zh/
这里注意一下这行代码:
WebDriver driver = new ChromeDriver();
如果要让代码运行成功需要下载一个chromedriver,如果你是windows可以去这个网址去下https://chromedriver.storage.googleapis.com/2.25/chromedriver_win32.zip,虽然是32位的但是64位也可以用,如果不行的话或者你是其他OS,可以去官网下https://chromedriver.storage.googleapis.com/index.html?path=2.27/
这里为什么不直接推荐去官网下载最新的呢?因为我之前用过,最新的在我的两个电脑上的windows系统都出现了问题。现在完成后解压放在C:\Windows\System32目录下,或者设置一下环境变量都行。
然后就可以运行了,之后的就是去提取一些数据或者url了,就像处理静态页面一样了。