许多人工智能应用离不开高质量的知识库,例如QA系统,对话机器人,推荐系统等等。 然而, 高质量知识库的构建与维护并非易事,往往需要耗费大量的人力成本,整个过程繁琐枯燥(各位machine learning practioners可以联想下自己标数据的经历)。当然,人们也采取了一些自动化方法来减轻人力投入,比如直接从互联网自动爬取知识。可是, 通过自动化知识爬取的方式得到的知识库的“靠谱性”就相对比较低啦!那么,有没有什么办法既可以减少人力成本(使得人工构建过程不那么枯燥无趣)同时又能保证所构建的知识库的“质量”呢?今年,我们发表在KDD 2018的论文《Learning-to-Ask: Knowldge Acquisition via 20 Questions》就试图回答这个问题。 我们认为,减少高质量知识库构建过程的人力投入的关键在于
- 降低整个过程的枯燥乏味程度,激励人们参与到知识库构建过程
- 尽量保证人们的每次参与都不会被“辜负”,高效地整合人类智慧
互动对话游戏“二十个问题”
如何让枯燥的过程变得有趣,甚至吸引人呢?受“Games with A Purpose”[1]和Speer[2]等人的工作启发,我们求助于游戏。事实上,互动型游戏可能是激励人们参与度的最好办法之一了,比如经典破冰游戏“你画我猜”。考虑到我们拥有游戏“二十个问题”的相关项目经验,且该游戏的规则简单,一个回合不会耗费用户太多时间,受众广,“二十个问题”理所当然地被我们选为知识库构建的载体。下面这张图简单地说明了“二十个问题”的大致流程,感兴趣的同学也可以WIKI一下。
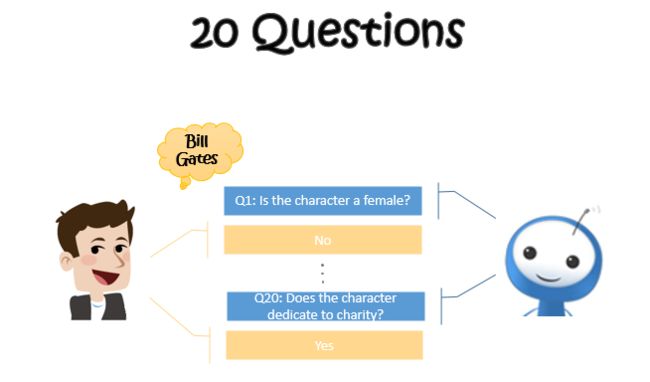
基于“二十个问题”对话游戏的高质量知识库构建框架
知识库
在介绍框架之前,我们先来看看我们想要搭建的知识库是什么模样。我们认为,一般来说,知识库都可以通过问题设计(比如,对于三元组
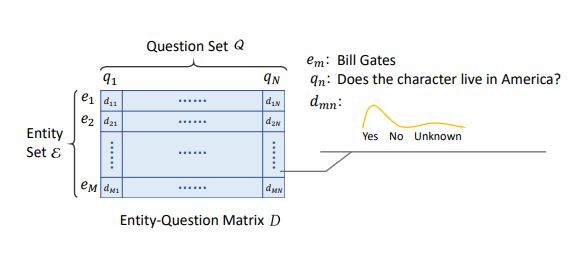
最初的知识库中可能仅有一小部分“知识”,其它部分都是未知的——实体-问题矩阵中大部分元素都是{Yes, No, Unknown}上的均匀分布。事实上,构建知识库等价于将这些均匀分布替换成人们真实观点的分布,将人类知识迁移到人工智能。从信息论的角度看,这是一个熵不断减小的过程,让这个过程更高效且更有趣是我们的目标。
LA 框架
基于“二十个问题”这个游戏, 我们提出了既可以让用户开心玩游戏又可以构建高质量知识库的LA框架。我们期待在一轮轮的游戏之后,知识库中的“均匀分布”能够满满接近人们真实观点的分布。因为有大量用户的知识支撑, 相较于自动爬取(或补全)方式,这样得来的知识库具备更高的质量。LA是Learning-to-Ask的缩写。如此起名是因为(它很酷)在框架中,我们的机器人主要负责提问题,提问的策略直接关系用户会不会喜欢这个游戏以及构建知识库的质量,我们希望LA框架可以帮助机器人学会如何提问以实现一石二鸟:
- 猜出用户心里所想,让用户觉得有趣。
- 补上缺失的重要知识,构建高质量知识库。
值得注意的是,这两个目标是耦合的。太笨的机器人老是猜不中,用户体验会大打折扣,参与率也会大大降低。而用户参与率直接影响收集到的知识的质量和数量。从另一方面来看,获取了高质量的新知识后,机器人会更容易猜中用户心中所想,从而提升用户体验。

如图所示,除了游戏状态管理模块,LA框架主要有两个算法模块:Information Seeking和Knowledge Acquisition,分别对应上述两个目标。两个模块都生成问题得分用于选择当前提出哪个问题。Information Seeking模块生成的问题得分用于判断哪些问题会帮助机器人猜到用户心中所想;Knowledge Acquisition模块生成的问题得分用于判断哪些问题值得机器人向用户提问以获得新知识。在我们的工作中,Information Seeking和Knowledge Acquisition分别基于深度强化学习和矩阵分解。

虽然传统的熵方法可以用于实现Information Seeking模块,但是当起始知识库只包含少量知识时(实体-问题矩阵高度稀疏),熵方法生成的提问策略表现差强人意。而改进版本的熵方法可能涉及到许多知识库相关的人工规则,不方便在不同类型,不同大小的知识库之间迁移。"二十个问题"游戏规则简单,模拟器容易构建,深度强化学习生成提问策略的方法可行且易于在不同的知识库之间迁移。Knowledge Acquisition模块则主要考虑新知识的不确定性和价值。不确定性可以通过在{yes no unknown}上的分布体现,而价值则使用矩阵分解模型建模。这里就不涉及细节了,感兴趣的朋友们可以去看我们的论文。
Information Seeking模块的设计
强化学习是交互式学习interactive learning的一个经典范式:机器人观察环境observation,采取动作action,获得相应的奖赏reward;机器人的目标是在不断的试错过程中找到最优的行动策略。如果需要补一下强化学习的背景知识,推荐Sutton的经典教材[3]。
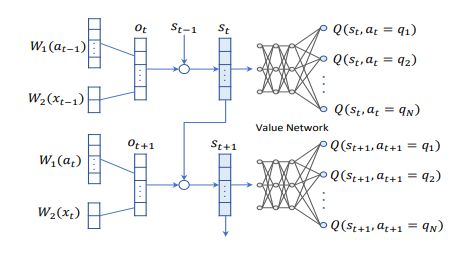
在一系列强化学习算法的尝试之后,我们选择了Q-learning算法,Q网络的架构如图所示。和分别是问题的Embedding矩阵和答复(yes,no,unknown)的Embedding矩阵。在第轮时,机器人提出问题,用户给出回答,则第轮机器人的observation为相应embedding向量的拼接。observation向量继而被送入一个循环单元,与上一轮的状态结合,得到当前这轮的状态。状态进入全连接层,输出当前状态下所有问题的得分。在推理时,机器人会挑得分最高的问题向用户提问。在一个回合结束时(比如机器人问完20个问题了),根据是否猜中为机器人分配reward,猜中则为1否则为-1,非结束轮的reward为0。在训练时,机器人与模拟器不断进行游戏,这些游戏经历被用来更新Q网络,以最大化每个游戏回合的期望累积奖赏。
Knowledge Acquisition模块算法
假设我们有一个知识缓存,里面存放着每个回合从用户那里获取的“事实”,当缓存满时则更新到我们的知识库里变成知识。由于我们的设定里,机器人在猜好实体后才进行KA,机器人获取的新事实只能关于当前回合的实体。
因为获取知识的机会非常宝贵(每个回合机器人都需要用一些“问题”资源来保证自己猜中了用户心中所想,剩余的“问题”资源才能被用来获取知识),机器人应当有“意识”地询问更有“价值”的问题,即更有可能得到用户有效回答的问题。例如,在某轮游戏中,机器人已猜出用户心中所想是“周杰伦”,那么问题"该角色是否主要唱民谣歌曲"比起“该角色是否喜欢人类”更有价值,因为对于音乐人来说,大家更关心他的音乐作品,用户更容易回答,也就更容易把知识传递给机器人了!类似的例子还有,对于一个足球运动员,我们更关心他是不是前锋等。经过这样一番考虑后,在KA过程中,我们把问题的价值定义为---”对于一个实体,提问之后,机器人可以得到用户答复的概率“。“价值”的估计其实是个矩阵补全问题---相似的实体,相似的问题具有相似的被答复概率。
除了问题的“价值”,我们还需要考虑知识的“不确定性”。知识库中的知识其实是一个个估计出来的Yes,No,Unknown上的分布,估计的质量依赖于收集的事实的数量。KA时,机器人每从用户那里得到一个答复,相当于获得一个事实。对于知识库中不确定性较高的(实体-问题)对,我们希望机器人在KA时能够再向用户确认下,即收集更多的事实。
综合考虑以上两方面,我们采用了如图所示KA算法,其中Equation 7是使用矩阵分解建模“价值”的公式,可围观我们的论文。

一些好玩的实验结果
验证IS模块的性能
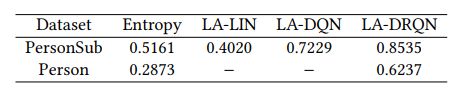
实验数据的统计信息如下表所示
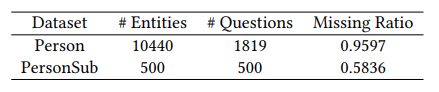
首先我们比较不同Agent实现方案的IS性能。比起熵模型来说,LA-DRQN在两个数据集上的表现都比较好。LA-LIN和LA-DQN由于网络结构导致其无法扩展到较大的数据集上,这说明了合理的网络结构设计对交互式Agent的重要性。
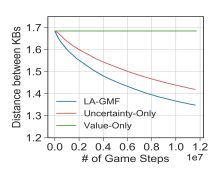
接着我们比较不同Agent实现方案的KA性能。如上文所述,我们认为在KA过程中要同时考虑“不确定性”和“价值”。为了验证这个观点,我们比较LA-GMF与uncertainty-only(只考虑“不确定性”的KA)、value-only(只考虑“价值”)的知识收集过程。由于新知识的“价值”是由初始知识库给出的近似,在一轮KA过程中,value-only在一轮KA中会反复的挑选“价值”最高的知识作为获取目标,不断收集样本来估计它们对应的“Yes”,“No”, "Unknown"分布,但是却忽略了其它知识,因而后续收集过程卡顿。至于uncertainty-only,它兼顾所有知识的不确定性,但是没有区分哪些知识更有价值,整体的知识收集进度比LA-GMF要低效些。
我们来看下LA-GMF与uncertainty-only生成的KA问题,来看看引入“价值”的效果。如下表所示,对于Jay Chou这个Entity,LA-GMF倾向于向用户提出“他是不是主要唱民谣歌曲”,“这个角色是不是很帅”,“这个角色是不是出生在日本”等问题以获取有意义的新知识,而uncertainty-only则可能会提出一些很让人尴尬的问题“这个角色是不是很像人类”,“这个角色是不是源于小说”, “这个角色是不是异常死亡”。同样地,对于动画人物工藤新一,也存在类似尴尬提问 —— 令用户无语且获取的新知识并非很有价值。对于一个歌手,我们会更关心他的音乐风格而不是这个角色是不是异常死亡。

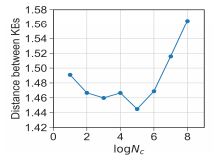
KA模块的设计存在着“价值”和“不确定性”的权衡问题。在我们的算法中,
Nc即负责权衡“价值”和“不确定性”。
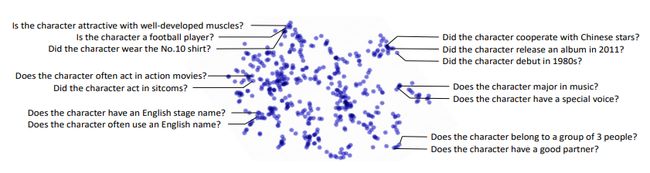
最后,我们想看看LA-DRQN能否学习到问题之间的关联性。我们把问题的embedding用tsne降维后得到下图。我们可以发现逻辑上相关联问题的embedding彼此靠近。例如,“这个角色是不是足球运动员”,“这个角色是不是肌肉发达”和“这个角色是不是穿10号球服”可以构成一组问题,递进地确定Entity。
小结与展望
我们的工作阐述了如何让AI在交互过程中既能够完成任务又能够不断积累知识以备他用,这应当是今后构建不断自我提升AI的基础。LA框架的要义在于如何“珍惜”每次与用户的交互,我们用游戏来提高了用户的参与度(这是区别于大多数众包的一个特性)整个系统由基于RL的IS模块和基于MF的KA模块构成。LA框架的潜在应用场景包括
- 对话式推荐系统;在推荐过程中快速探知用户的偏好(利用好每次交互)
- 医疗数据系统的快速构建;医疗数据通常需要高度精确,构建代价高,LA框架可以提高数据标注的效率
此外,仍然存在很多需要进一步思考的问题
- 问题设计与生成,在实验当中我们采用模板生成问题,下一步应当考虑如何生成自然语言问题
- 是否问题,在实验中,我们考虑二元问题,多个选项问题可以类似处理,但是否会存在效率问题
- 冷启动, KA其实是在不确定性情形下寻找高价值知识的过程。如何更快地从初始的小部分知识快速"Grow"?Bandit算法可以不可以更好地替代?
- 提问策略可否在不同Databases间迁移?
Reference
-
Luis Von Ahn and Laura Dabbish. 2008. Designing games with a purpose. Commun.
ACM 51, 8 (2008), 58–67. ↩ -
Robert Speer, Jayant Krishnamurthy, Catherine Havasi, Dustin Smith, Henry
Lieberman, and Kenneth Arnold. 2009. An interface for targeted collection of
common sense knowledge using a mixture model. In IUI. 137–146. ↩ -
Sutton, Richard S., and Andrew G. Barto. Reinforcement learning: An introduction. MIT press, 1998. ↩