※元素定位的重要性:在于查找元素 And 执行元素
定位元素的三种方法
- 1、定位单个元素:在定位单个元素时,selenium-webdriver 提示了如下一些方法对元素进行定位。在这些定位方式中,优先使用id、name、classname,对于网上的链接元素,推荐使用linkText定位方式,对于不好定位的元素,考虑使用火狐的插件去辅助定位(xpath)。
- 2、定位多个元素
- 3、层级定位:层级定位的思想是先定位父元素,然后再从父元素中精确定位出其我们需要选取的子元素。层级定位一般的应用场景是无法直接定位到需要选取的元素,但是其父元素比较容易定位,通过定位父元素再遍历其子元素选择需要的目标元素,或者需要定位某个元素下所有的子元素。比较典型的应用是表格的定位。
findElement和findElements方法
-
findElement()返回一个WebElement元素
-
findElements()返回一个List,多个WebElement元素
八种定位方式
•By.id(id):通过ID 属性查找
•By.name(name):通过name属性查找
•By.className(className) :通过classname属性查找
•By.linkText(链接文本):通过链接文本
•By.partialLinkText(部分链接文本):通过部分链接文本
•By.cssSelector(Css路径):通过CSS路径
•By.tagName(name):通过tagname查找
•By.xpath(XPath路径):通过XPath查找
例如:id\name\classname
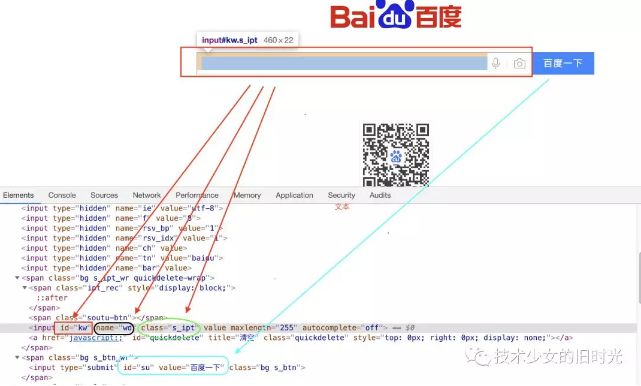
代码如下:
import org.junit.Test; import org.openqa.selenium.By; import org.openqa.selenium.WebDriver; import org.openqa.selenium.chrome.ChromeDriver; public class ZmbxTestJC { @Test public void Testid() throws InterruptedException { WebDriver driver =new ChromeDriver(); String url = "https://www.baidu.com"; driver.get(url); driver.findElement(By.name("wd")).sendKeys("Selenium");//定位到name,输入内容 driver.findElement(By.id("su")).click();//定位到id,点击百度一下查询内容 driver.quit(); } }
例如:By.linkText(Link文本)
HTML 源码: 搜索设置 WebElementelement =driver.findElement(By.linkText( "搜索设置" ));
例如:By.partialLinkText(部分链接文本)
HTML 源码: 搜索设置 WebElementelement =driver.findElement(By. partialLinkText( "搜索" ));//搜索设置
例如:By.cssSelector(Css路径)
HTML 源码: class="mnav">新闻 WebElementelement=driver.findElement(By. cssSelector( "#u1 > a:nth-child(1)" ));
例如:By.tagName(name)
HTML 源码: 搜索设置 WebElementelement=driver.findElement(By. tagName( "a" ));
例如:By.xpath(XPath路径)
HTML 源码: class="mnav">新闻 WebElementelement=driver.findElement(By. xpath( "//*[@id="u1"]/a[1]" ));
注意:
1.使用findElement()方法查找元素,元素必须是唯一2.findElements()同样支持这八种定位方式,只是获取的是多个元素,返回List
XPATH介绍:
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档节点(或称为根节点)。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
请看下面这个 XML 文档:
Harry Potter J K. Rowling 2005 29.99
上面的XML文档中的节点例子:lang="en" (属性节点)
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
实例,在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ), 则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们 在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所 有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
XPath 轴
轴可定义相对于当前节点的节点集。
| 轴名称 | 结果 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。 |
| self | 选取当前节点。 |
详细了解xpath,请参照 https://www.w3school.com.cn/xpath/xpath_summary.asp