1. selenium基础
selenium部分可以去看我写的selenium基础部分,由于链接太多了这里就不发出来了。
代理ip:
有时候频繁爬取一些网页。服务器发现你是爬虫后会封掉你的ip地址。这时候我们可以更改代理ip。更改代理ip不同的浏览器有不同的实现方式。这里使用我最常用的Chrome浏览器为例。
from selenium import webdriver chromeOptions = webdriver.ChromeOptions() # 设置代理 chromeOptions.add_argument("--proxy-server=http://202.20.16.82:10152") # 一定要注意,=两边不能有空格,不能是这样--proxy-server = http://202.20.16.82:10152 driver = webdriver.Chrome(chrome_options = chromeOptions) # 查看本机ip,查看代理是否起作用 driver.get("http://httpbin.org/ip") print(driver.page_source) # 退出,清除浏览器缓存 driver.quit()
注意事项:
第一,选择稳定的固定的代理IP。不要选择动态代理IP。我们常用的爬虫IP代理通常都是具有高度保密性质的高匿名动态IP,是通过拨号动态产生的,时效性非常的短,一般都是在3分钟左右。
第二,选择速度较快的代理IP。因为selenium爬虫采用的是浏览器渲染技术,这种浏览器渲染技术速度就本身就很慢。如果选择的代理IP速度较慢,爬取的时间就会进一步增加。
第三,要有足够大的电脑内存。因为chrome占内存较大,在并发度很高的情况下,容易造成浏览器崩溃,也就是程序崩溃。
第四,在程序结束时,调用driver.quit( )清除浏览器缓存。
2. selenium爬虫实例
选案例真的给我整吐了,开始想弄最常用的淘宝,结果一点搜索就要登录,然后就是天猫,点击下一页就需要登录,搞得我就爬了第一页。最后还是京东好,什么都可以。
2.1 初步分析
像京东、淘宝、天猫这些网站都是动态加载,刚打开只会加载几十条数据,当滑动条到达一定位置的时候,才会继续加载。这时候我们可以通过selenium模拟浏览器下拉网页的过程,获取网站全部商品的信息。
browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")


2.2 模拟翻页
在前面,我们如果要爬取查询的每一页的内容,我们只能分析url,找规律,才能跳转到下一页,并获取数据。
现在我们就可以使用xpath定位+selenium点击,来模拟浏览器的翻页行为了。
下拉网页至底部可以发现有一个下一页的按钮,我们只需获取并点击该元素即可实现翻页。
browser.find_element_by_xpath('//a[@class="pn-next" and @onclick]').click()

2.3 获取数据
接下来,我们需要解析每一个网页来获取我们需要的数据,具体包括(可以使用selenium选择元素):
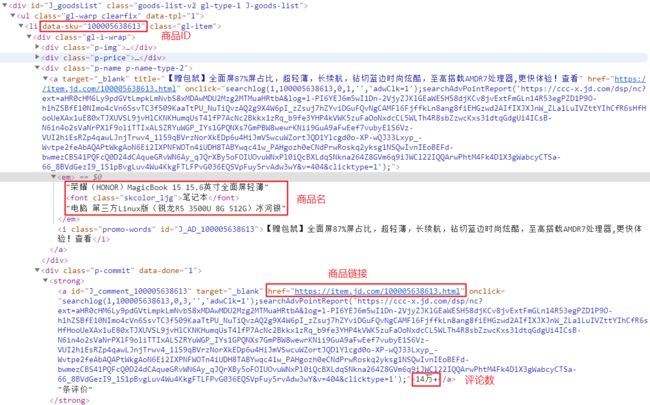
商品 ID:browser.find_elements_by_xpath('//li[@data-sku]'),用于构造链接地址
商品价格:browser.find_elements_by_xpath('//div[@class="gl-i-wrap"]/div[2]/strong/i')
商品名称:browser.find_elements_by_xpath('//div[@class="gl-i-wrap"]/div[3]/a/em')
评论人数:browser.find_elements_by_xpath('//div[@class="gl-i-wrap"]/div[4]/strong')
2.4 代码实现
from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By import selenium.common.exceptions import json import csv import time class JdSpider(): def open_file(self): self.fm = input('请输入文件保存格式(txt、json、csv):') while self.fm!='txt' and self.fm!='json' and self.fm!='csv': self.fm = input('输入错误,请重新输入文件保存格式(txt、json、csv):') if self.fm=='txt' : self.fd = open('Jd.txt','w',encoding='utf-8') elif self.fm=='json' : self.fd = open('Jd.json','w',encoding='utf-8') elif self.fm=='csv' : self.fd = open('Jd.csv','w',encoding='utf-8',newline='') def open_browser(self): self.browser = webdriver.Chrome() self.browser.implicitly_wait(10) self.wait = WebDriverWait(self.browser,10) def init_variable(self): self.data = zip() self.isLast = False def parse_page(self): try: skus = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//li[@class="gl-item"]'))) skus = [item.get_attribute('data-sku') for item in skus] links = ['https://item.jd.com/{sku}.html'.format(sku=item) for item in skus] prices = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[2]/strong/i'))) prices = [item.text for item in prices] names = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[3]/a/em'))) names = [item.text for item in names] comments = self.wait.until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="gl-i-wrap"]/div[4]/strong'))) comments = [item.text for item in comments] self.data = zip(links,prices,names,comments) except selenium.common.exceptions.TimeoutException: print('parse_page: TimeoutException') self.parse_page() except selenium.common.exceptions.StaleElementReferenceException: print('parse_page: StaleElementReferenceException') self.browser.refresh() def turn_page(self): try: self.wait.until(EC.element_to_be_clickable((By.XPATH,'//a[@class="pn-next"]'))).click() time.sleep(1) self.browser.execute_script("window.scrollTo(0,document.body.scrollHeight)") time.sleep(2) except selenium.common.exceptions.NoSuchElementException: self.isLast = True except selenium.common.exceptions.TimeoutException: print('turn_page: TimeoutException') self.turn_page() except selenium.common.exceptions.StaleElementReferenceException: print('turn_page: StaleElementReferenceException') self.browser.refresh() def write_to_file(self): if self.fm == 'txt': for item in self.data: self.fd.write('----------------------------------------\n') self.fd.write('link:' + str(item[0]) + '\n') self.fd.write('price:' + str(item[1]) + '\n') self.fd.write('name:' + str(item[2]) + '\n') self.fd.write('comment:' + str(item[3]) + '\n') if self.fm == 'json': temp = ('link','price','name','comment') for item in self.data: json.dump(dict(zip(temp,item)),self.fd,ensure_ascii=False) if self.fm == 'csv': writer = csv.writer(self.fd) for item in self.data: writer.writerow(item) def close_file(self): self.fd.close() def close_browser(self): self.browser.quit() def crawl(self): self.open_file() self.open_browser() self.init_variable() print('开始爬取') self.browser.get('https://search.jd.com/Search?keyword=%E7%AC%94%E8%AE%B0%E6%9C%AC&enc=utf-8') time.sleep(1) self.browser.execute_script("window.scrollTo(0,document.body.scrollHeight)") time.sleep(2) count = 0 while not self.isLast: count += 1 print('正在爬取第 ' + str(count) + ' 页......') self.parse_page() self.write_to_file() self.turn_page() self.close_file() self.close_browser() print('结束爬取') if __name__ == '__main__': spider = JdSpider() spider.crawl()
代码中需要注意的地方:
1.self.fd = open('Jd.csv','w',encoding='utf-8',newline='')
在打开csv文件时,最好加上参数newline='',否则我们写入的文件会出现空行,不利于后续的数据处理。
2.self.browser.execute_script("window.scrollTo(0,document.body.scrollHeight)")
在模拟浏览器向下拖动网页时,由于数据更新不及时,所以经常出现StaleElementReferenceException异常,我们可以在操作中加入time.sleep()给浏览器充足的加载时间,或者就是捕获该异常进行相应的处理了。
3.skus = [item.get_attribute('data-sku') for item in skus]
在selenium中使用xpath语法选取元素时,无法直接获取节点的属性值,而需要使用get_attribute()方法。
4.无头启动浏览器可以加快爬取速度,只需在启动浏览器时设置无头参数即可。
opt = webdriver.chrome.options.Options()
opt.set_headless()
browser = webdriver.Chrome(chrome_options=opt)