系统环境
在个人笔记本上使用virtualbox虚拟机
os:centos -7.x86-64.everything.1611 ,内核 3.10.0-514.el7.x86_64
注:同样可以使用rhel7.3来安装。
内存:2.5 g,推荐内存4g,否则内存太少,运行得有点慢。
安装组件包括:
hadoop-2.8.0
apache-hive-2.1.1
presto-server-0.177
mysql-community-server-5.7.18-1.el7.x86_64
oracle jdk1.8.0_131
注: hadoop的命令,在2.8.0中推荐是以hadoop开头,而不是hdfs,后者是一个向下兼容的措施。
例如hdfs dfs -mkdir /test 在2.8.0中的写法就是
hadoop fs -mkdir /test
由于安装的时候,使用的是老的安装文档,所以依然使用hdfs。不过个人严重建议使用hadoop命令。
--------------------------
第一步:创建用户和配置网络,并配置ssh连接,关闭不必要功能
1.0 关闭不必要功能
注:这仅仅是一个测试环境,正式环境可能不能关闭防火墙和selinux
systemctl stop firewalld
systemctl disable firewalld ---禁止防火强开启启动
setenforce 0 -- 关闭selinux
修改/etc/selinux/config ,设定 SELINUX=disabled --测底关闭selinux
1.1 创建用户
创建用户hadoop,并以/home/hadoop作为所有组件的Home,java例外
1.2 修改网络配置
修改 /etc/hosts,内容如下:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.199 bigdata.lzf
1.3 配置ssh 连接
确保是在/home/hadoop目下,执行以下命令
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
确认ssh bigdata.lzf 不需要输入任何密码
注:有的人使用dsa,这个看具体系统。
第二步:安装jdk
使用root的身份解压jdk到 /usr/local/jdk1.8.0_131
第三步:安装mysql
3,.1 下载安装
这个是使用root账户来安装的,并且使用rpm包安装。
由于这个版本默认已经安装了maridb,所以只能卸载默认安装的一些组件。
然后启动mysql
systemctl start mysqld
3.2 修改密码
由于是比较新的mysql版本,使用起来比较麻烦。按照以下步骤:
首先修改/etc/my.cnf ,添加: skip-grant-tables
mysql -u root
Use mysql;
update mysql.user set authentication_string=password(‘xxxxxx') where user='root';
commit;
flush privileges;
set password=password('xxxxxx');
3.3 创建库并授权
然后退出mysql,重新登录
mysql – u root -p
---以下几个步骤是为安装Hive准备
create database metastore;
grant all on metastore.* to 'root'@'%' identified by 'xxxxxx';
grant all on metastore.* to 'root'@'localhost' identified by 'xxxxxx';
grant all on metastore.* to 'root'@'bigdata.lzf' identified by 'xxxxxx';
第四步:安装hadoop
切换到hadoop用户。
解压hadoop包到/home/hadoop/hadoop-2.8.0
4.1 修改环境变量.bash_profile
export JAVA_HOME=/usr/local/jdk1.8.0_131
export HADOOP_HOME=/home/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.8.0/etc/hadoop
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export PATH=$PATH:$HOME/.local/bin:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin
保存后,执行source .bash_profile
4.2 创建目录
mkdir -p /home/hadoop/hadoop/tmp
mkdir -p /home/hadoop/hadoop/hdfs
mkdir -p /home/hadoop/hadoop/hdfs/data
mkdir -p /home/hadoop/ hadoop/hdfs/name
进入目录 /home/hadoop/hadoop-2.8.0/etc/hadoop
如果没有以下列出的文件,需要把.template的复制为没有.template的文件
例如
cp mapred-site.xml.template mapred-site.xml
4.3 配置 hadoop-env.sh,yarn-env.sh,mapred-env.sh
分别在文件前面添加以下内容:
export JAVA_HOME=/usr/local/jdk1.8.0_131
4.4 配置 core-site.xml
--为了权限,例如通过beeline之类的通过访问,必须 参考 http://hadoop.apache.org/docs/r2.8.0/hadoop-project-dist/hadoop-common/Superusers.html
添加以下内容:
#这个是告诉hadoop集群,用户hadoop和组hadoop可以任意访问
4.5 配置hdfs-site.xml
4.6 配置mapred-site.xml
4.7 配置yarn-site.xml
4.8 修改slaves
添加以下内容
bigdata.lzf
4.9 修改日志文件log4j.properties
添加内容如下:
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=DEBUG
4.10 启动并验证
$HADOOP_HOME/bin/hdfs namenode –format --这个执行一次即可。
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
执行jps,至少应该看到以下内容:
13664 ResourceManager
13511 SecondaryNameNode
12523 DataNode
12396 NameNode
13789 NodeManager
然后使用telnet查看有关的端口,这里是8042,8099,9001
其中8042,8099可以通过浏览器查看:
http://bigdata.lzf:8099
最后,可以使用一些常见命令例如:
hdfs dfs -mkdir -p /tmp/imput
hdfs dfs -mkdir -p /tmp/output
注:/tmp/input 并非操作系统的路径,而是一个相对路径,相对于 dfs.datanode.data.dir 的路径,但并不可以直接查看。
hdfs dfs -ls /tmp --查看路径/tmp
hdfs dfs -lsr /tmp --查看路径/tmp下的 ,等同于 hdfs dfs -ls -R /tmp
第五步:安装hive2
presto需要用到metastore,所以必须安装hive,这个从最新的官方结构图可以看出。
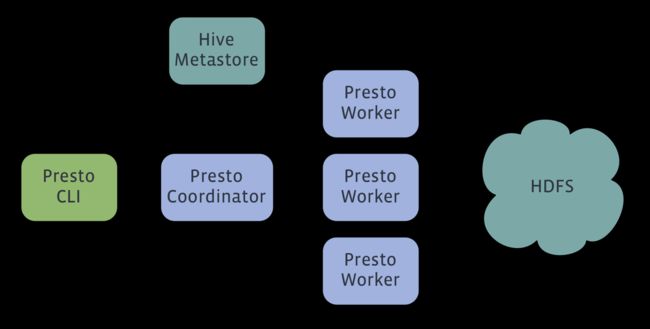
5.1 下载解压
解压到/home/hadoop/apache-hive-2.1.1-bin
5.2 准备hdfs路径
hdfs dfs -mkdir -p /warehouse
hdfs dfs -mkdir -p /tmp/hive
hdfs dfs -chmod 773 /warehouse
hdfs dfs -chmod 773 /tmp/hive
注:目录叫什么无所谓,看个人喜好。
5.3 配置环境变量
export HIVE_HOME=/home/hadoop/apache-hive-2.1.1-bin
export HIVE_CONF_DIR=/home/hadoop/apache-hive-2.1.1-bin/conf
export HCAT_LOG_DIR=/home/hadoop/apache-hive-2.1.1-bin/hcatalog/sbin/logs
export PATH=$PATH:$HOME/.local/bin:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin
然后 source .bash_profile
5.4 修改各个配置文件
cd $HIVE_HOME/conf
-------------------------------------------------------------------------------
修改 hive-env.sh
---------------------------------------------------------------------------------
# 下面这个CLASSPATH貌似没有起到作用,不过不妨碍使用。
export CLASSPATH=/home/hadoop/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar
export JAVA_HOME=/usr/local/jdk1.8.0_131
export HADOOP_HOME=/home/hadoop/hadoop-2.8.0
export HIVE_HOME=/home/hadoop/apache-hive-2.1.1-bin
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/home/hadoop/apache-hive-2.1.1-bin/conf
-------------------------------------------------------------------------------
修改hive-site.xml
--------------------------------------------------------------------------------
先复制hive-default.xml -> hive-site.xml文件
Client authentication types.
NONE: no authentication check
LDAP: LDAP/AD based authentication
KERBEROS: Kerberos/GSSAPI authentication
CUSTOM: Custom authentication provider
(Use with property hive.server2.custom.authentication.class)
当为binary的时候,只是启动10000端口,反之启用10001端口。
最后,把 ${system:java.io.tmpdir} 替换为/home/hadoop/data_hive/java_io_temp (需要创建实际的目录)
在替换 ${system 为${
-----------------------------------------------------------------
修改hive-log4j2.properties
------------------------------------------------------------------
property.hive.log.dir = /home/hadoop/data_hive/java_io_temp/${sys:user.name}
注:已经涉及到许多${开头的变量,在实际环境请谨慎配置。
5.5 初始化
$HIVE_HOME/bin/schematool -dbType mysql -initSchema
如果成功,请登录mysql,查看metastore 库下是否有表,如果有就是成功了。
(表太多,只显示一部分)
mysql> show tables;
+---------------------------+
| Tables_in_metastore |
+---------------------------+
| AUX_TABLE |
| BUCKETING_COLS |
| CDS |
| COLUMNS_V2 |
| COMPACTION_QUEUE |
| COMPLETED_COMPACTIONS |
| COMPLETED_TXN_COMPONENTS |
| DATABASE_PARAMS |
| DBS |
| DB_PRIVS |
| DELEGATION_TOKENS |
| FUNCS |
| FUNC_RU |
| GLOBAL_PRIVS |
| HIVE_LOCKS |
| IDXS |
| INDEX_PARAMS |
| KEY_CONSTRAINTS |
| MASTER_KEYS |
| NEXT_COMPACTION_QUEUE_ID |
| NEXT_LOCK_ID |
| NEXT_TXN_ID |
5.6 验证
先启动
hive --service metastore
hive --service hiveserver2 --如果是验证presto,这个可以不要,但这个是10002端口开启的必须条件
telnet bigdata.lzf 10002
http://bigdata.lzf:1002
hive (执行后,自然就可以执行各种hive命令)
也可以使用beeline
注:无论是hive命令还是beeline都会提示不建议使用,而是使用spark,tez之类的。
第六步:安装presto
以下内容可以完全参阅
https://prestodb.io/docs/current/installation/deployment.html
6.1下载和配置环境
解压到 /home/hadoop/presto-server-0.177
修改.bash_profile
最终的内容如下:
export JAVA_HOME=/usr/local/jdk1.8.0_131
export HADOOP_HOME=/home/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.8.0/etc/hadoop
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HIVE_HOME=/home/hadoop/apache-hive-2.1.1-bin
export HIVE_CONF_DIR=/home/hadoop/apache-hive-2.1.1-bin/conf
export HCAT_LOG_DIR=/home/hadoop/apache-hive-2.1.1-bin/hcatalog/sbin/logs
export PRESTO_HOME=/home/hadoop/presto-server-0.177
export PATH=$PATH:$HOME/.local/bin:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$PRESTO_HOME/bin
然后 source .bash_profile
6.2 修改各种配置
创建目录
mkdir -p $PRESTO_HOME/etc/catalog
mkdir -p /home/hadoop/data_presto/data
修改各个配置文件(这些文件都需要自己通过vi/vim创建,和hadoop不同,presto没有模板)
node.properties
node.environment=prestoquery
node.id=presto-0001
node.data-dir=/home/hadoop/data_presto/data
jvm.config
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
-DHADOOP_USER_NAME=hadoop
config.propertis
#如果presto只是安装一台机器上(既是coordinator又是worker),那么按照以下方式配置:
coordinator=true
node-scheduler.include-coordinator=true
#注意端口不要和hadoop,hive的冲突,配置之前可以使用netstat观察下
#在部署之前,至少应该有一份文档列出机器,ip,端口等等信息,包括路径,系统版本
http-server.http.port=8080
query.max-memory=5GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://bigdata.lzf:8080
log.properties
#正常之后,可以把DEBUG设置为其它数值: DEBUG,INFO,WARN,ERROR
com.facebook.presto=DEBUG
hive.properties (catalog目录下)
connector.name=hive-hadoop2
hive.metastore.uri=thrift://bigdata.lzf:9083
6.3 启动和关闭
$PRESTO_HOME/bin/launcher start -- 后台运行
$PRESTO_HOME/bin/launcher run --日志运行
$PRESTO_HOME/bin/launcher stop --停止
6.4 验证
[hadoop@bigdata ~]$ jps
6656 SecondaryNameNode
6992 NodeManager
7508 RunJar
7604 RunJar
9288 PrestoServer
6858 ResourceManager
6332 NameNode
6460 DataNode
9870 Jps
同时可以访问8080
6.5 使用presto-cli
下载presto-cli 的jar包,放在$PRESTO_HOME/bin下,并重命名为presto-cli
然后执行以下命令
presto-cli --server bigdata.lzf:8080 --catalog hive --schema default
presto:default> show tables;
Table
----------
customer
(1 row)
Query 20170602_093743_00002_pdfui, FINISHED, 1 node
Splits: 18 total, 18 done (100.00%)
0:11 [1 rows, 25B] [0 rows/s, 2B/s]
presto:default> select * from customer;
name
----------
luzhifei
(1 row)
Query 20170602_093803_00003_pdfui, FINISHED, 1 node
Splits: 17 total, 17 done (100.00%)
0:09 [1 rows, 9B] [0 rows/s, 0B/s]
成功!
第七:总结
1.耐心
2.网络上很多blog是可行的,但也有很多是错误的。最好是阅读官方参考
3.以上是单机下的配置,不能全部搬到生产环境
4.安装高版本的bigdata组件,建议还是用高版本的os,否则光glibc就有点麻烦
5.如果可能,也可以自己编译源码后再安装,但那个不适合于初学者。
第八:参考
主要参考:
hadoop
http://hadoop.apache.org/docs/r2.8.0/hadoop-project-dist/hadoop-common/SingleCluster.html
http://hadoop.apache.org/docs/r2.8.0/hadoop-project-dist/hadoop-common/Superusers.html
http://blog.csdn.net/se7en_q/article/details/47258007
hive2
http://www.2cto.com/database/201408/325554.html
http://www.tuicool.com/articles/Bbqaea
http://blog.csdn.net/login_sonata/article/details/53178613
presto
https://prestodb.io/docs/current/installation/deployment.html