常用的数据预处理方式
- Standardization, or mean removal and variance scaling
- Normalization: scaling individual to have unit norm
- Binarization: thresholding numerical features to get boolean values
- Encoding categorical feature
- Imputation of missing values
- Generating polynominal features
- Custom transformers
-
标准化(Standardization)
对sklearn中的很多机器学习算法,他们都有一个共同的要求:数据集的标准化(Standardization)。如果数
据集中某个特征的取值不服从保准的正态分布(Gaussian with zero mean and unit variance),则他们的
性能就会变得很差。
在实践中,我们经常忽略分布的形状(shape of the distribution)而仅仅通过除每个特征分量的均值
(Mean Removal)将数据变换到中心,然后通过除以特征分量的标准差对数据进行尺度缩放(variance scaling)。
举例来说,在学习器的目标函数中用到的很多元素(SVM中的RBF核函数,或线性代数中的L1和L2正则化)都假定了
所有特征分布在0周围而且每个分量的方差都差不多大。如果一旦某个特征分量的方差幅度远大于其他特征分量的
方差幅度,那么这个大方差特征分量将会主导目标函数的有优化过程,使得学习器无法正确的从其他特征上学习。
from sklearn import preprocessing
import numpy as np
X = np.array([[1, -1, 2], [2, 0, 0], [0, 1, -1]])
X_scaled = preprocessing.scale(X)
X_scaled
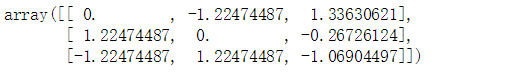
尺度调整之后的数据有0均值和单位方差(==1):
print(X_scaled.mean(axis=0))
print(X_scaled.std(axis=0))

Preprocessing模块进一步提供了一个类StandardScaler,该类实现了变换器(Transformer)的API用于
计算训练数据集的均值和标准差。然后将此均值与标准差用到对测试数据集的变换操作中去。所以这个标准化
的过程应该被应用到sklearn.pipeline.Pipeline的早期阶段。
scaler = preprocessing.StandardScaler().fit(X)
print(scaler)
print('--------')
print(scaler.mean_)
print('--------')
print(scaler.transform(X))

在上面的代码中,scaler实例已经训练完成,就可以再用来对新的数据执行在训练集上同样的变换操作。

我们还可以使用参数来进一步的自定义,with_mean=False, with_std=False来不去使用中心化和规模化。
把特征变换到指定范围内(Scaling feature to a range)
另外一种标准化是把特征的取值变换到指定的最小值和最大值之间,通常是[0,1]区间或每个特征分量的最大绝对值
被缩放为单位值,这样的变换可以使用MinMaxScaler或者MaxAbsScaler。
X_train = np.array([[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]])
min_max_scaler = preprocessing.MinMaxScaler()
X_train_minmax = min_max_scaler.fit_transform(X_train)
X_train_minmax

上面X_train上训练好的MinMaxScaler就可以通过transform函数被用到新的数据上,同样的缩放和平移操作被用到测试数据集
X_test = np.array([[-3., -1.,4. ]])
X_test_minmax = min_max_scaler.transform(X_test)
X_test_minmax
还可以通过MinMaxScaler对象的属性来获得在训练集上学习到的变换函数。

如果给MinMaxScaler对象一个显式的区间范围feature_range=(min,max),则其变换过程如下。

MaxAbsScaler的工作方式与MinMaxScaler很相似,但是其变换方式是让训练数据处于区间[-1,1]。这可以通过把每个特征分量除以其对应的最大值来做到。这种变换要求数据集已经被中心化到0或者是稀疏数据。
X_train = np.array([[1., -1., 2.],
[2., 0., 0. ],
[0., 1., -1.]])
max_abs_scaler = preprocessing.MaxAbsScaler()
X_train_maxabs = max_abs_scaler.fit_transform(X_train)
print(X_train_maxabs)
print('-------')
X_test = np.array([[-3., -1., 4.]])
X_test_maxabs = max_abs_scaler.transform(X_test)
print(X_test_maxabs)
print('-------')
print(max_abs_scaler.scale_)

缩放稀疏数据(Scaling sparse data)
中心化稀疏数据(Centering sparse data)将会破坏数据的稀疏型结构,因此很少这么做。然而,我们可以对稀疏的输入进行缩放(Scale sparse inputs),尤其是特征分量的尺度不一样的时候。
MaxAbsScaler和maxabs_scale都进行了一些特别的设计专门用于变换稀疏数据,是推荐的做法。
scale和StandardScaler也可以接受scipy.sparse矩阵作为输入,只要参数with_mean=False被显式的传入构造器就可以了,否则,会产生ValueErroe。
RobustScaler不能接受稀疏矩阵,但是你可以在稀疏输入上使用transform方法。
注意:变换器接受Compressed Sparse Rows和Compressed Sparse Columns格式(scipy.sparse.csr_marxi和scipy.sparse.csc_matrix)。其他任何的稀疏输入会被转换成Compressed Sparse Rows,为了避免不必要的内存拷贝,推荐使用CSR和CSC。最后,如果你的稀疏数据比较小,那么可以使用toarray方法吧稀疏数据转换成Numpy array。
Scaling data with outliers
如果数据中有很多的outliers(明显的噪点),均值和方差的估计就会有问题,所以使用均值和方法的数据集也会偶遇问题。
在这种情况下,可以使用robust_scale和RobustScaler,他们使用了更加鲁棒的方式来估计数据中心和范围。
-
规范化(Normalization)
Normalization: scaling individual to have unit norm
规范化是指,将单个的样本特征向量变换成具有单位长度(unit norm)的特征向量的过程。当你要使用二次形式(quadratic from)如点积或核变换运算来度量任意一堆样本的相似性的时候,数据的规范化会非常的有用
假定是基于向量空间模型,经常被用于文本分类和内容的聚类。
函数normalize提供了快速简单的方法使用L1或L2范数(距离)执行规范化操作:
X = [[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]]
X_normalized = preprocessing.normalize(X, norm='l2')
X_normalized

注意:该函数按行操作,把每一行变成单位长度。使用每一个元素去除以欧式距离。
preprocessing模块也提供了一个类Normalizer实现了规范化操作,该类是一个变换器Transformer,具有Transformer API(尽管fit方法在这种时候是没有用的: 该类是一个静态类因为归一化操作是将每一个样本单独进行变换,不存在在所有样本上的统计学习过程。)
规范化操作类Normalizer作为数据预处理步骤,应该用在Pineline管道流的早期阶段。

以上的transform过程不依赖于上面的X,也就是说fit是多余的,只是为了整个sklearn的统一。
Sparse input
normalize函数和Normalizer类都接受dense array-like and sparse matrics from scipy.sparse作为输入。
对于稀疏输入,在进入高效的Cython routines处理之前,都会将其转化成CSR(Compressed Sparse Rows)格式(scipy.sparse.csr_matrix),为了避免不必要的数据拷贝,推荐使用CSR格式的稀疏矩阵。
-
二值化(Binarize)
Binarization: thresholding numerical features to get boolean values
Feature binarization: 将数值型特征取值阈值化转换为布尔型特征取值,这一过程主要是为概率型的学习器(probabilistic estimators)提供数据预处理机制。
概率型学习器(probabilistic estimators)假定输入数据是服从于多变量伯努利分布(multi-variate Bernoulli distribution)的, 概率性学习器的典型的例子是sklearn.neural_network.BrenoulliRBM
在文本处理中,也普遍使用二值特征简化概率推断过程,即使归一化的词频特征或TF-IDF特征的表现比而二值特征稍微好一点。
就像Normalizer,Binarizer也应该用在sklearn.pipeline.Pipeline的早期阶段。fit方法也是什么也不干,有或者没有是一样的。
X = [[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]]
binarizer = preprocessing.Binarizer().fit(X)
print(binarizer)
print('-----')
print(binarizer.transform(X))

binarizer = preprocessing.Binarizer(threshold=1.1)
binarizer.transform(X)

就像StandardScaler和Normalizer类一样,preprocessing模块也为我们提供了一个方便的额binarize进行数值特征的二值化。
Sparse input
normalize函数和Normalizer类都接受dense array-like and sparse matrics from scipy.sparse作为输入。
对于稀疏输入,在进入高效的Cython routines处理之前,都会将其转化成CSR(Compressed Sparse Rows)格式(scipy.sparse.csr_matrix),为了避免不必要的数据拷贝,推荐使用CSR格式的稀疏矩阵。
-
标称型特征编码(Encoding categorical feature)
有些情况下,某些特征的取值不是连续的数值,而是离散的标称变量(categorical)。
比如一个人的特征描述可能是下面的或几种:
features ['male', 'female'], ['from Europe', 'from US', 'from Asia'], ['use Firefox', 'use Chorme', 'use Safari', 'Use IE']。
这样的特征可以被有效的编码为整型特征值(interger number)。
['male', 'US', 'use IE'] -->> [0,1,3]
['femel', 'Asia', 'use Chrome'] -->> [1,2,1]
但是这些整数型的特征向量是无法直接被sklearn的学习器使用的,因为学习器希望输入的是连续变化的量或者可以比较大小的量,但是上述特征里面的数字大小的比较是没有意义的。
一种变换标称型特征(categorical features)的方法是使用one-of-K或者叫one-hot encoding,在类OneHotEncoder里面就已经实现了。这个编码器将每一个标称型特征编码成一个m维二值特征,其中每一个样本特征向量就只有一个位置是1,其余位置全是0。
enc = preprocessing.OneHotEncoder()
enc.fit([[0,0,3],[1,1,0],[0,2,1],[1,0,2]])
enc.transform([[0,1,3]]).toarray()
第一列的取值有两个,使用两个数字编码;第二列取值有单个,使用三个数字编码;第三列取值有4个,使用四个数字编码。一共使用九个数字进行编码。
默认情况下,每个特征分量需要多少个值是从数据集中自动推断出来的。我们还可以通过参数n_values进行显式的指定。上面的数据集中,有两个性别,三个可能的地方以及四个浏览器。然后fit之后在对每一个样本进行变换。结果显示,前两个值编码了性别,接下来的三个值编码了地方,最后的四个值编码了浏览器。
注意:如果训练数据中某个标称型特征分量的取值没有完全覆盖其所有可能的情况,则必须给OneHotEncoder指定每一个标称型特征分量的取值个数,设置参数:n_values。
enc = preprocessing.OneHotEncoder(n_values=[2,3,4])
enc.fit([[1,2,3],[0,2,0]])

enc.transform([[1,0,0]]).toarray()
-
缺失值处理(Imputation of missing values)
由于各种各样的原因,很多真实世界中的数据集包含有缺失值,通常使用blanks,NaNs or other placeholders来代替。这样的数据集是无法直接被sklearn的学习器模型处理的。
一个解决的办法是将包含缺失值得整行或者整列直接丢弃。然而这样可能会丢失很多有价值的数据。
一个更好的办法是补全缺失值,也就是从已知的部分数据推断出未知的数据。
Imputer类提供了补全缺失值得基本策略: 使用一行或者一列的均值,中值,出现次数最多的值来补全,该类也允许不同缺失值得编码。
from sklearn.preprocessing import Imputer
imp = Imputer(missing_values='NaN', strategy='mean', axis=0)
imp.fit([[1,2], [np.nan,3], [7,6]])
X = [[np.nan,2], [6, np.nan], [7,6]]
imp.transform(X)
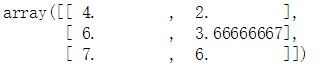
使用训练得数据来进行补全。
Imputer类支持稀疏矩阵:
import scipy.sparse as sp
X = sp.csc_matrix([[1,2], [0,3], [7,6]])
imp = Imputer(missing_values=0, strategy='mean', axis=0)
imp.fit(X)
X_test = sp.csc_matrix([[0,2], [6,0], [7,6]])
imp.transform(X_test)

-
多项式特征(Generating polynominal features)
为输入数据添加非线性特征可以增加模型的复杂度,实现这一点的常用的简单方法是使用多项式特征(polynominal features),他可以引入特征的高阶项和互乘积项。
sklearn的PolynominalFeatures类可以用来在出入数据的基础上构造多项式特征。
from sklearn.preprocessing import PolynomialFeatures
X = np.arange(6).reshape(3,2)
poly = PolynomialFeatures(2) # 二阶
poly.fit_transform(X)

有些情况下,我们只想要原始输入特征分量之间的互乘积项,这时可以设置参数:interaction_only=True,这时将不会出现次方项。
-
自定义转换器(Custom transformers)
有时候,你需要把一个已经有的Python函数变为一个变换器transformer来进行数据的清理和预处理。
借助于FunctionTransformer类,你可以从任意的Python函数实现一个transformer。比如,构造一个transformer实现对数变换。
from sklearn.preprocessing import FunctionTransformer
transformer = FunctionTransformer(np.log1p)
X = np.array([[0,1], [2,3]])
transformer.transform(X
