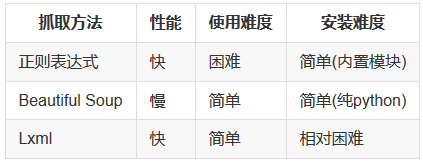
目前在学习《基于R语言的自动数据收集》和《用pyton写网络爬虫》,两者都介绍网页数据获取的相关途径,前者分析了xml、json、xpath、正则表达式,后者对python内正则表达式、Beautiful Soup和Lxml三者性能比较,如下表:
今天仅仅对正则表达式知识学习整理。Web上的内容主要是无结构的文本。网络抓取的一项核心任务就是从文本数据堆中采集和我们研究问题相关的信息。
正则表达式
正则表达式是用于搜索和操作文本数据的概括性文本特征。严格意义上,与其说它们是一个工具,不如说它们是如何通过各种函数对字符串进行查询的惯例。本文介绍R中实现扩展正则表达式的基本组成部分。下面字符串会贯穿本文的例子:
R> example.obj <- "1. A small sentence. - 2. Another tiny sentence."
严格的字符匹配
最基础的层次就是字符和字符的匹配,即使正则表达式也是如此。因此,从一个字符串提取一个子串就会得到子串本身,如果有:
R> str_extract(example.obj , "small")
[1] "small"
否则,函数会返回一个缺失值:
R> str_extract(example.obj , "banana")
[1] NA
这里及其它部分使用的函数主要是来自stringr组件的str_extract(),我们假定这个组件的所有后续例子里都已加载了的。该函数的定义是str_extract(string , pattern),这样首先输入要被操作的字符串,然后就是要查找的表达式。该函数会在一个给定的字符串里返回与给定正则表达式匹配的第一个实例。我们也可以调用str_extract_all()函数要求R取出每一个匹配的结果。大家有兴趣了解R和string字符串操作函数的比较,可以百度资料自行了解。
R> unlist(str_extract_all(example.obj , "sentence"))
[1] "sentence" "sentence"
由于str_extract_all()通常可以对多个字符串进行调用,所以结果是作为一个列表返回的,每个列表元素提供了针对其中的一个字符串的结果。上述调用中,输入字符串是一个长度为1的字符向量,因此,函数会返回一个长度为1的列表,对它调用unlist()以便解析。下面把上述结果和同时对多个字符串进行调用时国企函数的表现进行比较。我们创建一个包含了"text" "manipulation" "basics"几个字符串的向量。然后使用str_extract_all()函数来提取符合特征"a"的所有实例:
R> out <-str_extract_all(c("text","manipulation","basics") , "a")
R> out
[[1]]
character(0)
[[2]]
[1] "a" "a"
[[3]]
[1] "a"
该函数返回一个与输入向量长度(也就是3)相同的列表,列表每个元素包含一个字符串的结果。因为第一个字符串里没有a,所以第一个元素是一个空字符向量。第二个字符串包含2个a,第三个字符串有1个。
默认情况下,字符匹配是区分字母大小写的。因此,正则表达式里的大写字母和小写字母是不一样的。
R> str_extract(example.obj , "small")
[1] "small"
在上面的字符串里包含small,而没有SMALL。
R> str_extract(example.obj , "SMALL")
[1] NA
结果,该函数提取不到匹配的值。我们可以用ignore.case()包裹该字符串,从而改变这种结果。
R> str_extract(example.obj , ignore.case("SMALL"))
[1] "small"
使用正则表达式并不局限于匹配的单词。一个字符串无非是一个字符的序列。因此,我们也可以匹配字根:
R> unlist(str_extract_all(example.obj , "en"))
[1] "en" "en" "en" "en"
或字母字符和空格的混合。
R> unlist(str_extract_all(example.obj , "mall sent"))
[1] "mall sent"
正则表达式的广义化
到目前为止,我们只是进行固定表达式的匹配。但正则表达式的威力来源于能够编写灵活及广义化的查询条件。其中最为广义化的是句号( . )。它可以匹配任意字符。
R> str_extract(example.obj , "sm.ll")
[1] "small"
在正则表达式中,另一个强大的广义化是字符类(character class),它被包裹在中括号里[ ]。一个字符类的含义是任何中括号里的字符都会被匹配。
R> str_extract(example.obj , "sm[abc]ll")
[1] "small"
还有另一种方法也可以利用字符范围来指定字符类的元素,它使用 - 。
R> str_extract(example.obj , "sm[a-p]ll")
[1] "small"
在这种情况下,任何a到p的字符都是合法的匹配。除了字母和数字字符,也可以在正则表达式里包括标点和空格。相类似,它们也可以放在字符类里。例如,字符[uvw.]能匹配u、v、w,也能匹配句号和空格。