写在前面
压测的是否发现服务端TIME_WAIT状态的连接很多。
netstat -nat | grep :8080 | grep TIME_WAIT | wc -l
17731
TIME_WAIT状态多,简单的说就是服务端主动关闭了TCP连接。
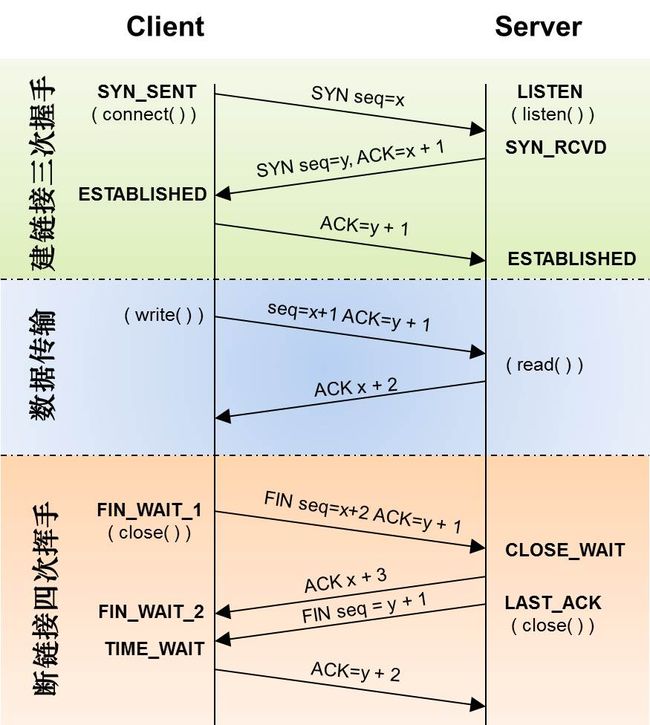
TCP频繁的建立连接,会有一些问题:
- 三次握手建立连接、四次握手断开连接都会对性能有损耗;
- 断开的连接断开不会立刻释放,会等待2MSL的时间,据我观察是1分钟;
- 大量
TIME_WAIT会占用内存,一个连接实测是3.155KB。而且占用太多,有可能会占满端口,一台服务器最多只能有6万多个端口;
TCP 相关
长连接的概念包括TCP长连接和HTTP长连接。首先得保证TCP是长连接。我们就从它说起。
func (c *TCPConn) SetKeepAlive(keepalive bool) error
SetKeepAlive sets whether the operating system should send keepalive messages on the connection. 这个方法比较简单,设置是否开启长连接。
func (c *TCPConn) SetReadDeadline(t time.Time) error
SetReadDeadline sets the deadline for future Read calls and any currently-blocked Read call. A zero value for t means Read will not time out.这个函数就很讲究了。我之前的理解是设置读取超时时间,这个方法也有这个意思,但是还有别的内容。它设置的是读取超时的绝对时间。
func (c *TCPConn) SetWriteDeadline(t time.Time) error
SetWriteDeadline sets the deadline for future Write calls and any currently-blocked Write call. Even if write times out, it may return n > 0, indicating that some of the data was successfully written. A zero value for t means Write will not time out. 这个方法是设置写超时,同样是绝对时间。
HTTP 包如何使用 TCP 长连接?
http 服务器启动之后,会循环接受新请求,为每一个请求(连接)创建一个协程。
// net/http/server.go L1892
for {
rw, e := l.Accept()
go c.serve()
}
下面是每个协程的执行的代码,我只摘录了一部分关键的逻辑。可以发现,serve方法里面还有一个for循环。
// net/http/server.go L1320
func (c *conn) serve() {
defer func() {
if !c.hijacked() {
c.close()
}
}()
for {
w, err := c.readRequest()
if err != nil {
}
serverHandler{c.server}.ServeHTTP(w, w.req)
}
}
这个循环是用来做什么的?其实也容易理解,如果是长连接,一个协程可以执行多次响应。如果只执行了一次,那就是短连接。长连接会在超时或者出错后退出循环,也就是关闭长连接。defer函数可以让协程结束之后关闭 TCP 连接。
readRequest函数用来解析 HTTP 协议。
// net/http/server.go
func (c *conn) readRequest() (w *response, err error) {
if d := c.server.ReadTimeout; d != 0 {
c.rwc.SetReadDeadline(time.Now().Add(d))
}
if d := c.server.WriteTimeout; d != 0 {
defer func() {
c.rwc.SetWriteDeadline(time.Now().Add(d))
}()
}
if req, err = ReadRequest(c.buf.Reader); err != nil {
if c.lr.N == 0 {
return nil, errTooLarge
}
return nil, err
}
}
func ReadRequest(b *bufio.Reader) (req *Request, err error) {
// First line: GET /index.html HTTP/1.0
var s string
if s, err = tp.ReadLine(); err != nil {
return nil, err
}
req.Method, req.RequestURI, req.Proto, ok = parseRequestLine(s)
mimeHeader, err := tp.ReadMIMEHeader()
}
具体参与解析 HTTP 协议的部分是ReadRequest方法,而调用它之前,设置了读写超时时间。根据前面的描述,超时时间设置的是绝对时间。所以这里都是通过time.Now().Add(d)来设置的。不同的是写超时是defer执行,也就是函数返回后才执行。
我们的程序为啥长连接失效?
通过源码我们能大概知道程序流程了,按道理是支持长连接的。为啥我们的程序不行呢?
我们的程序使用的是 beego 框架,它支持的超时是同时设置读写超时。而我们的设置是1秒。
beego.HttpServerTimeOut = 1
我对读写超时的理解,读超时是收到数据到读取完毕的时间;写超时是从一开始写到写完的时间。我对这两个超时的理解都不对。
实际上,从上面的源码可以发现,写超时是读取完毕之后设置的超时时间。也就是读取完毕之后的时间,加上逻辑执行时间,加上内容返回时间的总和。按照我们的设置,超过1秒就算超时。
下面详细说说读超时。ReadRequest是堵塞执行的,如果没有用户请求,它会一直等待着。而读超时是ReadRequest之前设置的,它除了读取数据之外,还有一部分耗时,那就是等待时间。假如一直没有用户请求,此时读超时已经被设置成1秒后了,超过1秒之后,这个连接还是会被断开。
如何解决问题?
原因已经说明白了。大量TIME_WAIT是超时引起的,有可能是等待时间过长引起的读超时;也有可能是程序在压测情况下出现一部分执行超时,这样会导致写超时。
我们目前使用的是 beego 框架,它并不支持单独设置读写超时,所以我目前的解决方式是将读写超时调整得大一些。
从1.6版本开始,Golang 能够支持空闲超时IdleTimeout,可以认为读超时就是读取数据的时间,空闲超时来控制等待时间。但是它有一个问题,如果空闲超时没有设置,而读超时设置了,那么读超时还是会作为空闲超时时间来使用。我估计这么做的原因是为了向前兼容。再一个问题就是 beego 并不支持这个时间的设置,所以我目前也没有别的太好的方法来控制超时时间。
后续
其实服务端最合理的超时控制需要这几个方面:
读超时。就是单纯的读超时,不要包括等待时间,否则无法区分超时是读数据引起的还是等待引起的。
写超时。最好也是单纯的写数据超时。如果网络良好,因为逻辑执行慢就把连接断开,这样也不是很合适。读写超时都应该和目前逻辑设置的一样,设置得短一些。
空闲超时。这个可以根据实际情况配置,可以适当大一些。
-
逻辑超时。一般情况下是不会发生网络层面的读写超时的,压测情况下超时大部分都是由于逻辑超时引起的。Golang 原生包支持了
TimeoutHandler。它可以控制逻辑的超时。可惜 beego 目前不支持设置逻辑超时。而我也没有想到太好的方法把 beego 中接入它。func TimeoutHandler(h Handler, dt time.Duration, msg string) Handler
参考文献
- 【1】Linux 中每个 TCP 连接最少占用多少内存? - 陈硕
- 【2】The complete guide to Go net/http timeouts - Filippo Valsorda