GCD Global队列创建线程进行耗时操作的风险
先思考下如下几个问题:
- 新建线程的方式有哪些?各自的优缺点是什么?
- dispatch_async 函数分发到全局队列一定会新建线程执行任务么?
- 如果全局队列对应的线程池如果满了,后续的派发的任务会怎么处置?有什么风险?
答案大致是这样的:dispatch_async 函数分发到全局队列不一定会新建线程执行任务,全局队列底层有一个的线程池,如果线程池满了,那么后续的任务会被 block 住,等待前面的任务执行完成,才会继续执行。如果线程池中的线程长时间不结束,后续堆积的任务会越来越多,此时就会存在 APP crash的风险。
比如:
- (void)dispatchTest1 {
for (NSInteger i = 0; i< 10000 ; i++) {
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
[self dispatchTask:i];
});
}
}
- (void)dispatchTask:(NSInteger)index {
//模拟耗时操作,比如DB,网络,文件读写等等
sleep(30);
NSLog(@"----:%ld",index);
}
以上逻辑用真机测试会有卡死的几率,并非每次都会发生,但多尝试几次就会复现,伴随前后台切换,crash几率增大。
下面做一下分析:
对于执行的任务来说,所执行的线程具体是哪个线程,是通过 GCD 的线程池(Thread Pool)来进行调度,正如Concurrent Programming: APIs and Challenges文章里给的示意图所示:
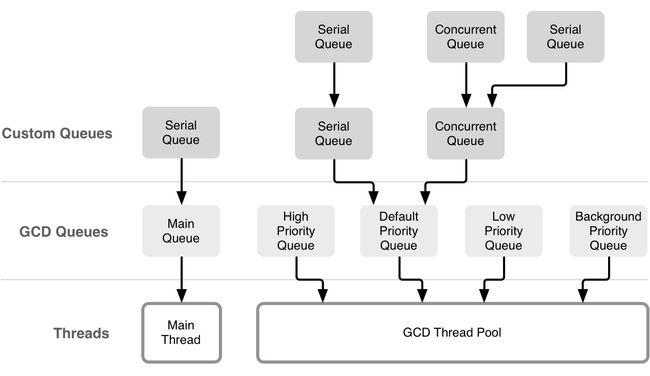
参看 GCD 源码我们可以看到全局队列的相关源码如下:我们关注如下的部分:
其中有一个用来记录线程池大小的字段 dgq_thread_pool_size。这个字段标记着GCD线程池的大小。摘录源码的一部分:
uint32_t j, t_count;
// seq_cst with atomic store to tail
t_count = dispatch_atomic_load2o(qc, dgq_thread_pool_size, seq_cst);
do {
if (!t_count) {
_dispatch_root_queue_debug("pthread pool is full for root queue: "
"%p", dq);
return;
}
j = i > t_count ? t_count : i;
} while (!dispatch_atomic_cmpxchgvw2o(qc, dgq_thread_pool_size, t_count,
t_count - j, &t_count, acquire));
苹果官方文档中说,全局队列的底层是一个线程池,向全局队列中提交的 block,都会被放到这个线程池中执行,如果线程池已满,后续再提交 block 就不会再重新创建线程。这就是为什么 Demo 会造成卡顿甚至冻屏的原因。
避免使用 GCD Global 队列创建 Runloop 常驻线程
在做网络请求时我们常常创建一个 Runloop 常驻线程用来接收、响应后续的服务端回执,比如NSURLConnection、AFNetworking等等,我们可以称这种线程为 Runloop 常驻线程。
正如上文所述,用 GCD Global 队列创建线程进行耗时操作是存在风险的。那么我们可以试想下,如果这个耗时操作变成了 runloop 常驻线程,会是什么结果?下面做一下分析:
先介绍下 Runloop 常驻线程的原理,在开发中一般有两种用法:
- 单一 Runloop 常驻线程:在 APP 的生命周期中开启了唯一的常驻线程来进行网络请求,常用于网络库,或者有维持长连接需求的库,比如: AFNetworking 、 SocketRocket。
- 多个 Runloop 常驻线程:每进行一次网络请求就开启一条 Runloop 常驻线程,这条线程的生命周期的起点是网络请求开始,终点是网络请求结束,或者网络请求超时。
单一 Runloop 常驻线程
先说第一种用法:
以 AFNetworking 为例,AFURLConnectionOperation 这个类是基于 NSURLConnection 构建的,其希望能在后台线程接收 Delegate 回调。为此 AFNetworking 单独创建了一个线程,并在这个线程中启动了一个 RunLoop:
+ (void)networkRequestThreadEntryPoint:(id)__unused object {
@autoreleasepool {
[[NSThread currentThread] setName:@"AFNetworking"];
NSRunLoop *runLoop = [NSRunLoop currentRunLoop];
[runLoop addPort:[NSMachPort port] forMode:NSDefaultRunLoopMode];
[runLoop run];
}
}
+ (NSThread *)networkRequestThread {
static NSThread *_networkRequestThread = nil;
static dispatch_once_t oncePredicate;
dispatch_once(&oncePredicate, ^{
_networkRequestThread = [[NSThread alloc] initWithTarget:self selector:@selector(networkRequestThreadEntryPoint:) object:nil];
[_networkRequestThread start];
});
return _networkRequestThread;
}
多个 Runloop 常驻线程
第二种用法,我写了一个小 Demo 来模拟这种场景,
我们模拟了一个场景:假设所有的网络请求全部超时,或者服务端根本不响应,然后网络库超时检测机制的做法:
#import "Foo.h"
@interface Foo() {
NSRunLoop *_runloop;
NSTimer *_timeoutTimer;
NSTimeInterval _timeoutInterval;
dispatch_semaphore_t _sem;
}
@end
@implementation Foo
- (instancetype)init {
if (!(self = [super init])) {
return nil;
}
_timeoutInterval = 1 ;
_sem = dispatch_semaphore_create(0);
// Do any additional setup after loading the view, typically from a nib.
return self;
}
- (id)test {
// 第一种方式:
// NSThread *networkRequestThread = [[NSThread alloc] initWithTarget:self selector:@selector(networkRequestThreadEntryPoint0:) object:nil];
// [networkRequestThread start];
//第二种方式:
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^(void) {
[self networkRequestThreadEntryPoint0:nil];
});
dispatch_semaphore_wait(_sem, DISPATCH_TIME_FOREVER);
return @(YES);
}
- (void)networkRequestThreadEntryPoint0:(id)__unused object {
@autoreleasepool {
[[NSThread currentThread] setName:@"CYLTest"];
_runloop = [NSRunLoop currentRunLoop];
[_runloop addPort:[NSMachPort port] forMode:NSDefaultRunLoopMode];
_timeoutTimer = [NSTimer scheduledTimerWithTimeInterval:1 target:self selector:@selector(stopLoop) userInfo:nil repeats:NO];
[_runloop addTimer:_timeoutTimer forMode:NSRunLoopCommonModes];
[_runloop run];//在实际开发中最好使用这种方式来确保能runloop退出,做双重的保障[runloop runUntilDate:[NSDate dateWithTimeIntervalSinceNow:(timeoutInterval+5)]];
}
}
- (void)stopLoop {
CFRunLoopStop([_runloop getCFRunLoop]);
dispatch_semaphore_signal(_sem);
}
@end
如果
for (int i = 0; i < 300 ; i++) {
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^(void) {
[[Foo new] test];
NSLog(@"类名与方法名:%@(在第%@行),描述:%@", @(__PRETTY_FUNCTION__), @(__LINE__), @"");
});
}
以上逻辑用真机测试会有卡死的几率,并非每次都会发生,但多尝试几次就会复现,伴随前后台切换,crash几率增大。
其中我们采用了 GCD 全局队列的方式来创建常驻线程,因为在创建时可能已经出现了全局队列的线程池满了的情况,所以 GCD 派发的任务,无法执行,而且我们把超时检测的逻辑放进了这个任务中,所以导致的情况就是,有很多任务的超时检测功能失效了。此时就只能依赖于服务端响应来结束该任务(服务端响应能结束该任务的逻辑在 Demo 中未给出),但是如果再加之服务端不响应,那么任务就永远不会结束。后续的网络请求也会就此 block 住,造成 crash。
如果我们把 GCD 全局队列换成 NSThread 的方式,那么就可以保证每次都会创建新的线程。
注意:文章中只演示的是超时 cancel runloop 的操作,实际项目中一定有其他主动 cancel runloop 的操作,就比如网络请求成功或失败后需要进行cancel操作。代码中没有展示网络请求成功或失败后的 cancel 操作。
Demo 的这种模拟可能比较极端,但是如果你维护的是一个像 AFNetworking 这样的一个网络库,你会放心把创建常驻线程这样的操作交给 GCD 全局队列吗?因为整个 APP 是在共享一个全局队列的线程池,那么如果 APP 把线程池沾满了,甚至线程池长时间占满且不结束,那么 AFNetworking 就自然不能再执行任务了,所以我们看到,即使是只会创建一条常驻线程, AFNetworking 依然采用了 NSThread 的方式而非 GCD 全局队列这种方式。
注释:以下方法存在于老版本AFN 2.x 中。
+ (void)networkRequestThreadEntryPoint:(id)__unused object {
@autoreleasepool {
[[NSThread currentThread] setName:@"AFNetworking"];
NSRunLoop *runLoop = [NSRunLoop currentRunLoop];
[runLoop addPort:[NSMachPort port] forMode:NSDefaultRunLoopMode];
[runLoop run];
}
}
+ (NSThread *)networkRequestThread {
static NSThread *_networkRequestThread = nil;
static dispatch_once_t oncePredicate;
dispatch_once(&oncePredicate, ^{
_networkRequestThread = [[NSThread alloc] initWithTarget:self selector:@selector(networkRequestThreadEntryPoint:) object:nil];
[_networkRequestThread start];
});
return _networkRequestThread;
}
正如你所看到的,没有任何一个库会用 GCD 全局队列来创建常驻线程,而你也应该
避免使用 GCD Global 队列来创建 Runloop 常驻线程。
有个朋友担心“NSThread创建太多,应该也会引起线程调度频繁,资源竞争大吧,global 队列创建太多常驻线程,也可能使得系统在global 队列运行的任务迟迟得不到执行吧”,这个担心是有道理的,这个需要在最外层限制并发数量。无限制也会导致线程泄露。