前言:
上节课我们讲了 MR job的提交YARN的工作流程 与 YARN的架构,本次课程详细讲讲YARN,多多总结。
YARN(主从) 资源 + 作业调度管理
YARN:是一种新的 Hadoop资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
ResourceManager(RM):主要接收客户端任务请求,接收和监控NodeManager(NM)的资源情况汇报,负责资源的分配与调度,启动和监控ApplicationMaster(AM)。
ApplicationManager(作业):应用程序管理,它是负责系统中所有的job,包括job的提交与调度器协商资源来启动ApplicationMaster(AM)和监控(AM)运行状态,并且失败的时候能够重新启动它,更新分配给一个新的Container容器的进度或者状态,除了资源它不管,它就负责job
Scheduler(调度器):更具容量队列的限制条件将我们系统中的资源分配给正在运用的一个应用程序先进先出调度器 :一个作业运行完了,另一个才能运行
yarn的内置调度器:
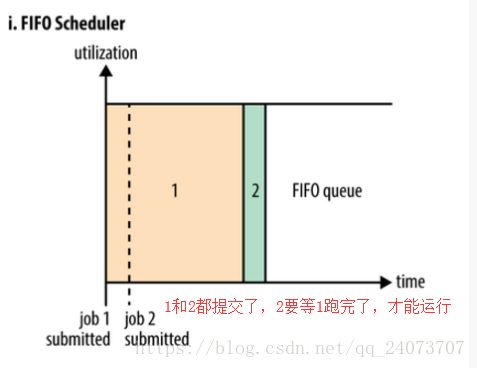
1.FIFO先进先出,一个的简单调度器,适合低负载集群。(适合任务数量不多的情况下使用)
2.Capacity调度器,给不同队列(即用户或用户组)分配一个预期最小容量,在每个队列内部用层次化的FIFO来调度多个应用程序。(适用于有很多小的任务跑,需要占很多队列,不使用队列,会造成资源的浪费)

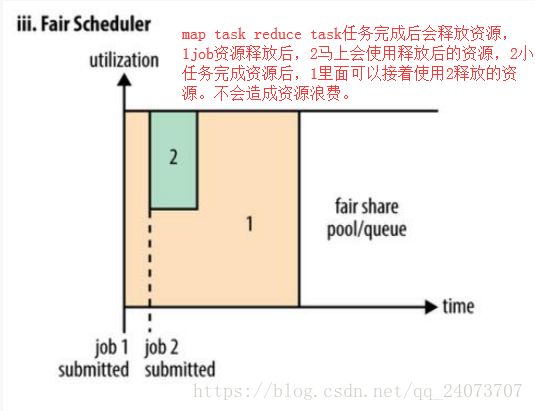
3.Fair公平调度器,针对不同的应用(也可以为用户或用户组),每个应用属于一个队列,主旨是让每个应用分配的资源大体相当。(当然可以设置权重),若是只有一个应用,那集群所有资源都是他的。 适用情况:共享大集群、队列之间有较大差别。(生产使用)
capacity调度器的启用:
在ResourceManager节点上的yarn-site.xml设置
Property===>yarn.resourcemanager.scheduler.class
Value=====>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
capacity调度器的配置:
在目录$HADOOP_HOME/hadoop/etc/hadoop/capacity-scheduler.xml
修改完成后,需要执行下面的命令:
$HADOOP_YARN_HOME/bin/yarn rmadmin -refreshQueues 使功能动态生效。
NodeManager:主要是节点上的资源和作业管理器,启动Container运行task计算,上报资源、container情况给RM和任务处理情况给AM,整个集群有多个。
ApplicationMaster: 它是负责我们作业的监控并跟踪应用执行状态来重启失败任务的,主要是单个Application(Job)的task管理和调度,向RM进行资源的申请,向NM发出launchContainer指令,接收NM的task处理状态信息。一个job只有一个主程序。
Container:是YARN中资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源)。
Memory:
yarn.nodemanager.resource.memory-mb:64*0.8G=50G (如果内存是64G,Yarn只能用到内存的80%也就是50G)
yarn.scheduler.minimum-allocation-mb: 1G
yarn.scheduler.maximum-allocation-mb: 1G 50/1=50(并行度) 数量是多了,并行度大了
一个作业200 MapTask 4轮才能结束,速度快了 作业可能挂了
yarn.scheduler.maximum-allocation-mb: 16G (生产设16G) 50/16=3(并行度) 数量是少了,并行度小了
一个作业200 MapTask 70轮才能结束,速度慢了 作业时间长 稳定不会挂
工作中一个job可以指定 yarn.scheduler.maximum-allocation-mb的值,但一般不指定。

【若泽大数据实战】使用YARN跑一个jar包
先启动Yarn
[hadoop@hadoop-01 sbin]$ ./start-all.sh
[hadoop@hadoop-01 sbin]$ jps
3696 Jps
2772 NameNode
3092 SecondaryNameNode
2884 DataNode
3367 NodeManager
3259 ResourceManager
进入hadoop的bin目录 在hdfs上创建一个新文件夹
[hadoop@hadoop-01 sbin]$ hdfs dfs -mkidr /wordcount/input
创建一个test.log文件
[hadoop@hadoop-01 hadoop-2.8.1]$ vi test.log
a b c
www.ruozedata.com
c b a
~
将当前目录中的某个test.log文件复制到hdfs中(注意要确保当前目录中有该文件)
[hadoop@hadoop-01 hadoop-2.8.1]$ hdfs dfs -put test.log /wordcount/input
查看hdfs中是否有我们刚复制进去的文件
进入share的上层目录,提交单词统计任务,实验环境下我们的提交差不多在15秒左右
生产环境中,应该是30~50之间,调优可以压到10秒之内
[hadoop@hadoop-01 hadoop-2.8.1]$ yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar wordcount /wordcount/input /wrdcount/output
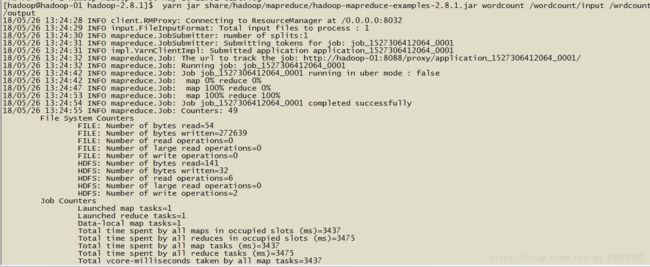
登录网页查看相关信息:http://192.168.137.30:8088/cluste

Yarn的常用命令
yarn application -list
yarn application -killapplication_1513862674371_0003(App的id)
再次回顾一下 YARN的工作流程:
客户端提交job给 Applications Manager 连接Node Manager去申请一个Container的容器,这个容器运行作业的App Mstr的主程序,启动后向App Manager进行注册,然后可以访问URL界面,然后App Mastr向 Resource Scheduler申请资源,拿到一个资源的列表,和对应的NodeManager进行通信,去启动对应的Container容器,去运行 Reduce Task 和 Map Task (两个先后运行顺序随机运行),它们是向App Mstr进行汇报它们的运行状态, 当所有作业运行完成后还需要向Applications Manager进行汇报并注销和关闭
yarn中,它按照实际资源需求为每个任务分配资源,比如一个任务需要1GB内存,1个CPU,则为其分配对应的资源,而资源是用container表示的,container是一个抽象概念,它实际上是一个JAVA对象,里面有资源描述(资源所在节点,资源优先级,资源量,比如CPU量,内存量等)。当一个applicationmaster向RM申请资源时,RM会以container的形式将资源发送给对应的applicationmaster,applicationmaster收到container后,与对应的nodemanager通信,告诉它我要利用这个container运行某个任务。
【若泽大数据面试题】
请问RM节点上有Container容器的这种说法吗?
答:这种说法是错误的,Container容器只运行在 Node Manager上面。
在AM中,job已经被分成一系列的task,并且是为每个task来startContainer。为什么NM上要存一个application的数据结构呢?
答:在YARN看来,他所维护的所有应用程序叫appliction,但是到了计算框架这一层,各自有各自的名字,mapreduce叫job,storm叫topology等等,YARN是资源管理系统,不仅仅运行mapreduce,还有其他应用程序,mapreduce只是一种计算应用。但是yarn内部设有应用程序到计算框架应用程序的映射关系(通常是id的映射),你这里所说的应用程序,job属于不同层面的概念,切莫混淆,要记住,YARN是资源管理系统,可看做云操作系统,其他的东西,比如mapreduce,只是跑在yarn上的application,但是,mapreduce是应用层的东西,它可以有自己的属于,比如job task,但是yarn专业一层是不知道或者说看不到的。
“YARN是资源管理系统,运行在它之上的所有应用程序叫application,例如mapreduce就是运行在YARN上的一个application。在mapreduce内部产生了job、task等等对象”。但是还是有一点疑问:对于Yarn来说,对于每一个运行程序application(例如mapreduce)只维护一个内部application对象么?
比如在Yarn上运行了一个mapreduce(它是跑在yarn上的application这里我能理解),例如当mapreduce中的某个job与NM发生交互时,YARN只能知道是mapreduce这个application再与它进行交互,而无法得知是这个application中的某一个对象再与之进行交互么?这样的话,例如当不同的job(一个application中可以有很多job)与NM进行交互时,Yarn怎样去区别当前job。或者Yarn在维护的那个application数据结构中能够表示该application的哪部分正在运行?
答:YARN不需要知道是job还是其他东西与它交互,在他看来,只有application,YARN为这些applicaiton提供了两类接口,一个是申请资源,具体申请到资源后,applicaiton用来干啥,跑map task还是跑MPI task,YARN不管,二是运行container的命令(container里面包的是task或者其他application内部要跑的东西),一般是一个shell命令,用于启动container(即启动task)。YARN看不到application什么时候运行完,他还有几个task没跑,这些只有applicaiton自己知道,当application运行结束后,会告诉YARN,YARN再将他所有信息抹掉。
是否只有负责启动ApplicationMaster的NodeManager才会维护一个Application对象?其他的NodeManager是否是根据ApplicationMaster发起的请求来启动属于这个Application的其他Container,这些NodeManager不需要维护Application的状态机?
答:都需要维护,通过Application状态机可将节点上属于这个App的所有Container聚集在一起,当需要特殊操作,比如杀死Application时,可以将对应的所有Container销毁。
另外,需要注意,一个应用程序的ApplicationMaster所在的节点也可以运行它的container,这都是随机的。
Container的节点随机性?
答:Container的节点随机性,我的理解是Container运行的节点是由分配资源时集群中哪些节点正好是空闲的来决定的,ResourceManager在为ApplicationMaster分配所需的Container的时候,完全有可能出现ApplicationMaster的本地节点上出现了空闲资源,这样,如果分配成功之后,ApplicationMaster就和所属的Container运行在一个节点上了。
Memory 资源的调度和隔离:
基于以上考虑,YARN允许用户配置每个节点上可用的物理内存资源,注意,这里是“可用的”,因为一个节点上的内存会被若
干个服务共享,比如一部分给YARN,一部分给HDFS,一部分给HBase等,YARN配置的只是自己可以使用的,配置参数如下:
(1)yarn.nodemanager.resource.memory- - mb
表示该节点上YARN可使用的物理内存总量,默认是8192(MB),注意,如果你的节点内存资源不够8GB,则需要调减小这个值,而
YARN不会智能的探测节点的物理内存总量。
(2)yarn.nodemanager.vmem- - pmem- - ratio
任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1。
(3)yarn.nodemanager.pmem- - check- - enabled
是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
(4) yarn.nodemanager.vmem- - check- - enabled
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。
(5)yarn.scheduler.minimum- - allocation- - mb
单个任务可申请的最少物理内存量,默认是1024(MB),如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。
(6)yarn.scheduler.maximum- - allocation- - mb
单个任务可申请的最多物理内存量,默认是8192(MB)。
默认情况下,YARN采用了线程监控的方法判断任务是否超量使用内存,一旦发现超量,则直接将其杀死。由于Cgroups对内存的控
制缺乏灵活性(即任务任何时刻不能超过内存上限,如果超过,则直接将其杀死或者报OOM),而Java进程在创建瞬间内存将翻
倍,之后骤降到正常值,这种情况下,采用线程监控的方式更加灵活(当发现进程树内存瞬间翻倍超过设定值时,可认为是正常
现象,不会将任务杀死),因此YARN未提供Cgroups内存隔离机制。
CPU资源的调度和隔离:
目前的CPU被划分成虚拟CPU(CPU virtual Core),这里的虚拟CPU是YARN自己引入的概念,
初衷是,考虑到不同节点的CPU性能可能不同,每个CPU具有的计算能力也是不一样的,比如某个物
理CPU的计算能力可能是另外一个物理CPU的2倍,这时候,你可以通过为第一个物理CPU多配置几个
虚拟CPU弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟CPU个数。在YARN中,CPU
相关配置参数如下:
(1) yarn.nodemanager.resource.cpu- - vcores
表示该节点上YARN可使用的虚拟CPU个数,默认是4,注意,目前推荐将该值设值为与物理CPU核数
数目相同。如果你的节点CPU核数不够8个,则需要调减小这个值,而YARN不会智能的探测节点的物
理CPU总数。
(2) yarn.scheduler.minimum- - allocation- - vcores
单个任务可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数少于该数,则该对应
的值改为这个数。
(3) yarn.scheduler.maximum- - allocation- - vcores
单个任务可申请的最多虚拟CPU个数,默认是32。
默认情况下,YARN是不会对CPU资源进行调度的,你需要配置相应的资源调度器。
【若泽大数据】生产场景:
内存改完参数 Yarn是要重启的
1.计算及时性要求比较高:memory不够,cpu是足够的,作业肯定是要挂掉的,立即手工调整oom,设置大,快速出结果,
2.计算机及时性不高:memory够,cpu不够,计算慢,
需求5分钟出1个job:job运行1分钟的时候,oom了内存不够,shell脚本里面可以改参数,修改脚本内存就自动加,
生产:cpu物理和虚拟的比例是1:2的关系(默认), 有的生产会设置1:1
1.YARN架构设计(mr的提交到Yarn的流程)
RM:调度器 + APPS Manager
NM:
Container(容器):
1个NM --> 多个容器 --> 只能运行一个task
APP Master |maptask | reduce task
1台机器64G内存16核 -->8个容器 -->8G +2核
1台机器64G内存:DN + NM =64*(75%~85%)
数据本地化
生产:
DN:4G
NM:50G
2.调优
NM:yarn.nodemanager.resource.memory-mb:50 * 1024MB(生产调)
container:memory+cpu
Memory:
任务计算最小是1024MB:
yarn.scheduler.minimum-allocation-mb: 1024 1G-->2G-->3G (生产调)
任务计算最多是8192MB,如果超过就kill:
yarn.scheduler.maximum-allocation-mb: 8192<=50G (生产调)
每次增加2048M,默认是1024MB:
yarn.scheduler.increment-allocation-mb: 2048 (CDH平台)
增加到最大时执行kill,默认为true;
yarn.nodemanager.pmem-check-enabled:true
yarn.nodemanager.vmem-pmem-ratio 2.1 使用1G内存 2.1虚拟内存
yarn.nodemanager.vmem-check-enabled true
SWAP:硬盘做的,说白了,就是拿一个比如20G的盘作为内存
参数:http://blog.csdn.net/javastart/article/details/51375287
高度计算
1.不允许计算慢,允许挂掉:swap 没有
2.允许计算慢,不允许任务挂掉:swap 有
vm.swappiness=0-100
0:不是禁用,说明调用swap的积极性是最差的
10:调用swap的积极性是稍微好点
100:太积极 生产:选择2+vm.swappiness=10
CPU:
yarn.nodemanager.resource.cpu-vcores -1
yarn.scheduler.minimum-allocation-vcores 1
yarn.scheduler.maximum-allocation-vcores4<=32(生产调)
vcore:虚拟核1个物理核为2个虚拟核 CDH有个参数,一般默认就行
http://blog.itpub.net/30089851/viewspace-2127851/
http://blog.itpub.net/30089851/viewspace-2127850/
JVM系列:
http://blog.itpub.net/30089851/cid-180723-abstract-1/
4.queue:队列 见CDH (补充)
需求:
1.项目:
开发
测试
开发/测试队列
部署生产 生产队列
就是一套集群环境
2.多个项目:
项目1生产 队列1资源少点
项目2生产 队列2资源多点
就是一套集群环境
开发和测试就是另外一套
默认:default
调度:
计算调度
公平调度 Fair (生产)
http://dongxicheng.org/mapreduce-nextgen/hadoop-yarn-configurations-fair-scheduler/