kafka
集群开启kafka服务:nohup bin/kafka-server-start.sh config/server.properties >/dev/null 2>&1 &
1)多线程同时从多个分区并行消费:思路:一个分区开启一个线程,多线程的实现方式:
①继承Thread ②实现Runnable接口
多个分区的配置partition:
1)servers.properties配置文件
2)在代码中指定partition的个数
多线程并行消费:
1)一个topic可以有多个分区
2)并行消费
kafka:
官网:kafka.apache.org
首先要明确的一点是kafka是分布式的数据流平台,用来作为消息系统进行数据的推拉操作。
Kafka is run as a cluster on one or more servers.
-- kafka作为集群运行在一台或多态机器上。
The Kafka cluster stores streams of records in categories called topics.
--kafka集群 存储数据流是以topic来分类的。
Each record consists of a key, a value, and a timestamp.
--每一条记录包含一个键值对,以及一个时间戳。
四个核心java代码:
1)producer API:允许一个应用程序发布数据流到kafka的一个或者多个topic中。
2)consumer API:允许一个应用程序订阅一个或多个topic并处理展示给他们的数据流。
3)streams API:允许一个应用程序充当一个数据流加工者,消费一个输入流(该输入流的数据可能是一个或者多个topic传送过来),生产一个输出流输出数据到一个或者多个topic。即有效地将数据从输入流传送到输出流。
4)connector API:连接kafka的topic到已存在的应用程序或者数据系统。例如:利用一个与关系型数据库的连接器可以获取到一张表的任何的变动。

topic的分区:分区中真正保存着数据,消费者消费数据的指标是起始偏移量offset。一个分区可以被多个消费者消费,每个消费者的起始偏移量都会通过日志记录下来,便于下次消费,但同时消费者也可以重置这个偏移量来决定从哪里开始消费数据。
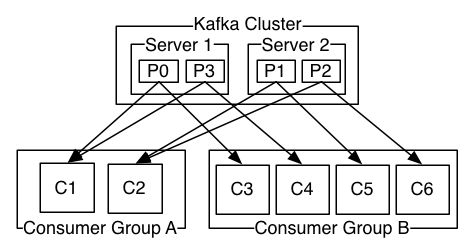
线程必须与分区数一致。
flume:
1)如何让一个flume的数据传到另一个flume
2)source的选择:exec
3)关键是sink的选择
4)一个flume中配置两个sink--对应两个flume
5)一个上游的agent对接两个下游的agent
实现HA:一开始只向下游的agent发送数据,当这个agent出问题之后,自动把数据发送到另外的agent(思路:zookeeper监控目录,如果发现一个agent目录掉了,发送消息给上游的agent,让它去连接另外一个agent。)
flume案例二:
查看tomcat日志最新添加内容,并以回滚的方式输出到hdfs目录
首先写一个配置文件tailcat.properties
# tail.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command=tail -F /home/hadoop/flume1705/tomcat.log
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=/flume/event/%y-%m-%d/%H%M
a1.sinks.k1.hdfs.filePrefix=event-
a1.sinks.k1.hdfs.round=true
a1.sinks.k1.hdfs.roundValue=10
a1.sinks.k1.hdfs.roundUnit=minute
a1.sinks.k1.hdfs.rollInterval=3
a1.sinks.k1.hdfs.rollSize=120
a1.sinks.k1.hdfs.rollCount=3
a1.sinks.k1.hdfs.useLocalTimeStamp=true
a1.sinks.k1.hdfs.fileType=DataStream
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
将该properties文件放到flume/conf目录下
第二步:在文件夹/home/hadoop/flume1705/下创建一个文件tomcat.log--读取路径
第三步:进入flume家目录,执行命令:
bin/flume-ng agent --conf conf --conf-file conf/tailcat.properties --name a1 -Dflume.root.logger=INFO,console