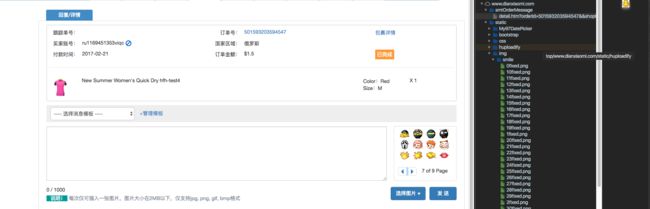
可是这个表情包有接近100个表情嗷、怎么可能一个个下载。于是想到写个爬虫、下载到文件夹里。问题是、我也没写过爬虫啊
一、找了个NodeJS爬虫框架
网上搜到个爬虫框架叫crawler: https://www.npmjs.com/package/crawler#options-reference
上面的示例代码我也试了一下、很方便。加上保存到本地的代码,就是这样:
var fs = require('fs');
var Crawler = require("crawler");
var c = new Crawler({
maxConnections : 10,
callback : function (error, res, done) {
if(error){
console.log(error);
}else{
var $ = res.$;
console.log($("title").text());
}
done();
}
});
c.queue([{
uri: 'http://www.dianxiaomi.com/static/img/smile/11fixed.png',
jQuery: false,
callback: function (error, res, done) {
if(error){
console.log(error);
}else{
console.log('Grabbed', res.body.length, 'bytes');
saveAs(res.body, './smile.png');
}
done();
}
}]);
function saveAs(data, filename){
fs.writeFile(filename, data, 'binary', function(err){
if (err){
console.log('download fail');
} else {
console.log('download success');
}
});
}
只可惜这么保存下来的图片无法打开。字节数也比原图少了好多个。我很怀疑是跟这个是二进制文件有关系。这个方法用来保存个网页文件应该没啥问题。但是没找到怎样配置的方法。
二、用NodeJS的API直接下载网络图片
网上又找到一段“下载网络图片”的代码,比上面的还要简单。修改后就是这样:
var http = require("http");
var fs = require("fs");
function download(url, filename){
http.get(url, function(res){
var imgData = "";
res.setEncoding("binary"); //一定要设置response的编码为binary否则会下载下来的图片打不开
res.on("data", function(chunk){
imgData += chunk;
});
res.on("end", function(){
fs.writeFile(filename, imgData, "binary", function(err){
if(err){
console.log("down fail");
}
console.log("down success");
});
});
});
}
var dir = './smile/';
var baseUrl = 'http://www.dianxiaomi.com/static/img/smile/'; //0fixed.png
for (var i = 0; i < 100; i++){
var url = baseUrl + i + 'fixed.png';
var fileName = dir + i + 'fixed.png';
download(url, fileName);
}
注意其中有很关键的两句,也就是专门处理二进制文件的:
res.setEncoding("binary");
fs.writeFile(filename, imgData, "binary", function(err){...
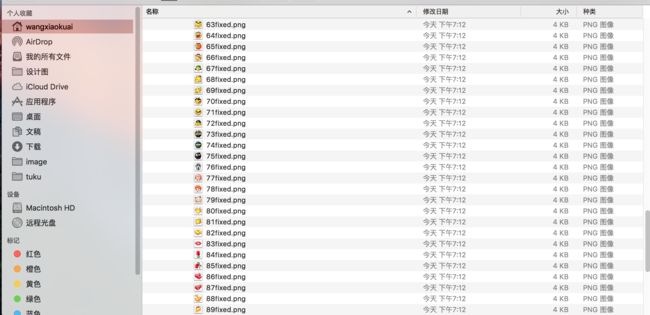
这样下载下来的图片就能正常打开了。看,98张表情“唰”的一下就下来了:
三、关于NodeJS爬虫的进一步
https://github.com/alsotang/node-lessons/tree/master/lesson3 这个项目是架构组的同学推荐的、里面介绍了怎么把一个网站爬下来。有机会可以一试~