1、zookeeper概念
zookeeper是一个分布式协调服务:
Zookeeper是一个高效的分布式协调服务,可以提供配置信息管理、命名、分布式同步、集群管理、数据库切换等服务。它不适合用来存储大量信息,可以用来存储一些配置、发布与订阅等少量信息。Hadoop、Storm、消息中间件、RPC服务框架、分布式数据库同步系统,这些都是Zookeeper的应用场景。
2、zookeeper集群机制
Zookeeper集群中节点个数一般为奇数个(>=3),若集群中Master挂掉,剩余节点个数在半数以上时,就可以推举新的主节点,继续对外提供服务
3、zookeeper特性
- Zookeeper:一个leader,多个follower组成的集群
- 全局数据一致:每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的
- 分布式读写,更新请求转发,由leader实施
- 更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行
- 数据更新原子性,一次数据更新要么成功,要么失败
- 实时性,在一定时间范围内,client能读到最新数据
4、zookeeper数据结构
Zookeeper使用的数据结构为树形结构,根节点为"/"。Zookeeper集群中的节点,根据其身份特性分为leader、follower、observer。leader负责客户端writer类型的请求;follower负责客户端reader类型的请求,并参与leader选举;observer是特殊的follower,可以接收客户端reader请求,但是不会参与选举,可以用来扩容系统支撑能力,提高读取速度。
5、zookeeper原理及内部选举机制
原理:zookeeper在配置文件中并没有指定master和slave,但是,zookeeper在工作时,只有一个节点为leader,其余节点为follower,leader是通过内部的选举机制临时产生的。
选举机制:(两种情况)
(1)全新集群paxos
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的.假设这些服务器依序启动,来看看会发生什么.
1) 服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态
2) 服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1,2还是继续保持LOOKING状态.
3) 服务器3启动,根据前面的理论分析,服务器3成为服务器1,2,3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader.
4) 服务器4启动,根据前面的分析,理论上服务器4应该是服务器1,2,3,4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了.
5) 服务器5启动,同4一样,当小弟.
(2)非全新集群(数据恢复)
初始化的时候,是按照上述的说明进行选举的,但是当zookeeper运行了一段时间之后,有机器down掉,重新选举时,选举过程就相对复杂了。
需要加入数据id、leader id和逻辑时钟。
数据id:数据新的id就大,数据每次更新都会更新id。
Leader id:就是我们配置的myid中的值,每个机器一个。
逻辑时钟:这个值从0开始递增,每次选举对应一个值,也就是说: 如果在同一次选举中,那么这个值应该是一致的 ; 逻辑时钟值越大,说明这一次选举leader的进程更新.
选举的标准就变成:
1、逻辑时钟小的选举结果被忽略,重新投票
2、统一逻辑时钟后,数据id大的胜出
3、数据id相同的情况下,leader id大的胜出
根据这个规则选出leader。
6、zookeeper集群的搭建
- 准备三台机器:hadoop1(192.168.1.11)、hadoop2(192.168.1.12)、hadoop3(192.168.1.13),并且安装jdk(可参照笔记:https://www.cnblogs.com/zhangan/p/10901192.html)。
- 将zookeeper安装包上传到hadoop1的/usr/local中:wget http://apache.fayea.com/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz 。
- 解压:tar -zxvf /usr/local/zookeeper-3.4.5.tar.gz
重命名:mv zookeeper-3.4.5.tar.gz zookeeper
- 修改环境变量
vi /etc/profile
添加内容:export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=.:$ZOOKEEPER_HOME/bin....
刷新环境变量
source /etc/profile
注意:3台机器都要修改
- 修改配置文件
cd /usr/local/zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
添加内容:
maxClientCnxns=60
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper/data
dataLogDir=/data/logs/zookeeper
clientPort=2181 (客户端连接端口)
server.1=192.168.1.11:2888:3888 (主机名, 心跳端口、数据端口)
server.2=192.168.1.12:2888:3888 (都是默认端口)
server.3=192.168.1.13:2888:3888 (2888表示zookeeper程序监听端口,3888表示zookeeper选举通信端口)
创建文件夹
mkdir /usr/local/zookeeper/data
mkdir /usr/local/zookeeper/log
在data文件夹中新建myid文件,myid文件的内容为1(一句话创建:echo 1 > myid)
cd data
vi myid
添加内容:1
- 把zookeeper目录复制到hadoop2和hadoop3中
设置三个机器的本机免密登录(三台机器配置一样):
scp -r /usr/local/zookeeper/ hadoop2:/usr/local/
scp -r /usr/local/zookeeper/ hadoop3:/usr/local/
将hadoop0中的环境变量复制到hadoop2和hadoop3中
scp /etc/profile hadoop2:/etc/
scp /etc/profile hadoop3:/etc/
环境变量复制好了以后,在hadoop2和hadoop3上都要执行source /etc/profile
- 把hadoop2中相应的myid的值改为2
vi /usr/local/zk/data/myid 将里面的值改为2
把hadoop3中相应的myid的值改为3
vi /usr/local/zk/data/myid 将里面的值改为3
- 将三台机器的防火墙关闭掉,service iptables stop ,查看service iptables status,还有selinux。
启动,在三个节点上分别都要执行命令zkServer.sh start
cd /usr/local/zk/bin
ls
zkServer.sh start
启动完了之后,在bin目录下多了一个zookeeper.out
- 检验,jps查看进程,会出现进程QuorumPeerMain
在三个节点上依次执行命令zkServer.sh status(可以看到MODE,谁是leader,谁是follower)
hadoop1:follower
hadoop2:leader
hadoop3:follower
7、zookeeper命令行客户端
执行zkCli.sh,客户端连接上服务器hadoop1。
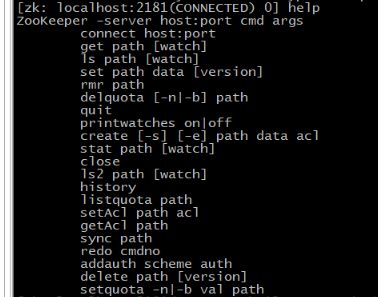
ls / 查找根目录
create /test abc 创建节点并赋值
get /test 获取指定节点的值
set /test cb 设置已存在节点的值
rmr /test 递归删除节点
delete /test/test01 删除不存在子节点的节点
使用 ls 命令来查看当前 ZooKeeper 中所包含的内容:
![]()
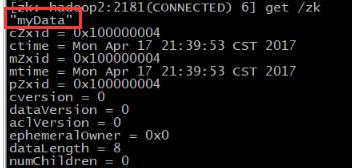
创建一个新的 znode ,使用 create /zk “myData” 。这个命令创建了一个新的 znode 节点“ zk ”以及与它关联的字符串:

我们运行 get 命令来确认 znode 是否包含我们所创建的字符串:
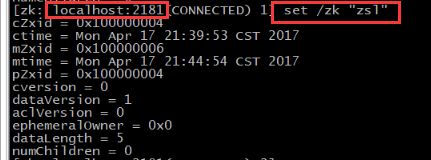
#监听这个节点hadoop2的变化,当另外一个客户端localhost改变/zk时(见4),它会打出下面的
#WATCHER::
#WatchedEvent state:SyncConnected type:NodeDataChanged path:/zk
[zk: localhost:2181(CONNECTED) 4] get /zk watch

下面我们通过 set 命令来对 zk 所关联的字符串进行设置:
下面我们将刚才创建的 znode 删除:

删除节点:rmr
