环境准备(linux虚拟机一台)
1 、java环境(1.7)
2 、 python环境(2.7)
3 、zookeeper环境(3.4.5)
4 、 kafka环境(2.9.2)
5 、 storm环境(0.9.2)
6 、redis
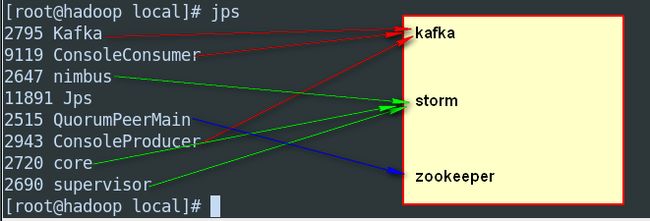
启动环境(这里使用单节点)
2017-04-26_165356.png
【程序逻辑】
kafka模拟随机数据实时发送到“ARF”主题,storm的数据源spout作为kafka的消费者去消费接收到的数据,对数据简单处理后持久化到redis中
【代码】
pom.xml
(pom文件这里要注意的是pom文件中的storm版本要与linux服务器上安装的storm版本一致,包括storm_kafka的整合jar也要一致)
junit
junit
4.10
test
org.apache.storm
storm-core
0.9.2
org.apache.storm
storm-kafka
0.9.2
org.slf4j
slf4j-log4j12
org.slf4j
slf4j-api
commons-collections
commons-collections
org.apache.kafka
kafka_2.11
0.9.0.0
org.slf4j
slf4j-log4j12
log4j
log4j
jmxtools
com.sun.jdmk
jmxri
com.sun.jmx
jms
javax.jms
org.apache.zookeeper
zookeeper
redis.clients
jedis
2.8.1
org.apache.commons
commons-pool2
2.4.2
kafka生产者
(kafka随机获取静态map中的某个单词数据发送给主题ARF)
/**
* kafka生产者类
* @author lvfang
*
*/
public class KafkaProduce extends Thread {
// 主题
private String topic;
// 数据源容器
private static final Map map = new HashMap();
final Random random = new Random();
static {
map.put(0, "java");
map.put(1, "php");
map.put(2, "groovy");
map.put(3, "python");
map.put(4, "ruby");
}
public KafkaProduce(String topic){
super();
this.topic = topic;
}
//创建生产者
private Producer createProducer(){
Properties properties = new Properties();
//zookeeper单节点
properties.put("zookeeper.connect","192.168.1.201:2181");
//kafka单节点
properties.put("metadata.broker.list", "192.168.1.201:9092");
properties.put("serializer.class", StringEncoder.class.getName());
return new Producer(new ProducerConfig(properties));
}
@Override
public void run() {
//创建生产者
Producer producer = createProducer();
//循环发送消息到kafka
while(true){
producer.send(new KeyedMessage(topic, map.get(random.nextInt(5))));
try {
//发送消息的时间间隔
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
// 使用kafka集群中创建好的主题 test
new KafkaProduce("ARF").start();
}
}
kafka消费者
(kafka消费者从主题ARF中实时获取数据)
/**
* kafka消费者类
* @author lvfang
*
*/
public class KafkaCusumer extends Thread {
private String topic;//主题
private long i;
public KafkaCusumer(String topic){
super();
this.topic = topic;
}
//创建消费者
private ConsumerConnector createConsumer(){
Properties properties = new Properties();
//zkInfo
properties.put("zookeeper.connect","192.168.1.201:2181");
//必须要使用别的组名称, 如果生产者和消费者都在同一组,则不能访问同一组内的topic数据
properties.put("group.id", "group1");
return Consumer.createJavaConsumerConnector(new ConsumerConfig(properties));
}
@Override
public void run() {
//创建消费者
ConsumerConnector consumer = createConsumer();
//主题数map
Map topicCountMap = new HashMap<>();
// 一次从topic主题中获取一个数据
topicCountMap.put(topic, 1);
//创建一个获取消息的消息流
Map>> messageStreams = consumer.createMessageStreams(topicCountMap);
// 获取每次接收topic主题到的这个数据
KafkaStream stream = messageStreams.get(topic).get(0);
ConsumerIterator iterator = stream.iterator();
try {
//循环打印
while (iterator.hasNext()) {
String message = new String(iterator.next().message());
i++;
System.out.println("接收到 " + i + " 条消息: "+ message);
}
} catch (Exception e) {}
}
public static void main(String[] args) {
// 使用kafka集群中创建好的主题 test
new KafkaCusumer("ARF").start();
}
}
先将以上生产消费调通

2017-04-26_171718.png
2017-04-26_171731.png
调通kafka生产消费后就可以整合storm了,这里要注意各个数据的流向
kafka生产消费模式:kafka生产者 ------> kafka消费者
storm数据流模式: spout ---> bolt1 ----> bolt2 ... ...
kafka整合storm模式:kafka生产者 ------> kafkaSpout(kafka的消费者就是storm的数据源)
kafkaSpout
/**
* kafka整合storm作为storm数据源spout
* @author lvfang
*
*/
public class KafkaSpoutMain {
// 主题与zk端口
public static final String TOPIC = "ARF";
public static final String ZKINFO = "192.168.1.201:2181";
public static void main(String[] args) {
TopologyBuilder topologyBuilder = new TopologyBuilder();
//创建zk主机
ZkHosts zkHosts = new ZkHosts(ZKINFO);
//创建spout
SpoutConfig spoutConfig = new SpoutConfig(zkHosts, TOPIC, "","KafkaSpout");
//整合kafkaSpout
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
// 设置storm数据源为kafka整合storm的kafkaSpout
topologyBuilder.setSpout("KafkaSpout", kafkaSpout, 1);
//数据流向,流向dataBolt进行处理
topologyBuilder.setBolt("dataBolt", new DataBolt(), 1).shuffleGrouping("KafkaSpout");
Config config = new Config();
config.setNumWorkers(1);
if (args.length > 0) {
try {
StormSubmitter.submitTopology(args[0], config,topologyBuilder.createTopology());
} catch (Exception e) {
}
} else {
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("getData", config,topologyBuilder.createTopology());
}
}
}
bolt(storm处理数据组件,这里直接将数据存储redis)
/**
* 解析数据持久化
* @author lvfang
*
*/
public class DataBolt extends BaseRichBolt {
public int i = 0;
public static Jedis jedis;
public Map map = new HashMap();
//jedis,生产环境最好用JedisPool
static {
jedis = new Jedis("192.168.1.201",6379);
jedis.auth("cjqc123456");
}
public void execute(Tuple tuple) {
String string = new String((byte[]) tuple.getValue(0));
i++;
String[] datas = string.split(" ");
System.out.println("【收到消息:" + i + " 条数据】" + string);
map.put("a", UUID.randomUUID()+ "_" + string);
map.put("b", UUID.randomUUID()+ "_" + string);
map.put("c", UUID.randomUUID()+ "_" + string);
map.put("d", UUID.randomUUID()+ "_" + string);
jedis.hmset("test", map);
}
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
// 初始化
}
public void declareOutputFields(OutputFieldsDeclarer arg0) {
}
}
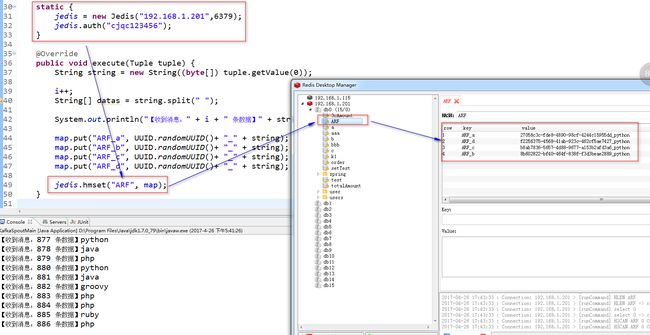
启动kafkaSpoutMain获取kafka的数据,并查看redis中是否有数据
2017-04-26_174349.png