哈喽,最近出差比较多,学习放缓,捂脸中...今天主要说一些scikit-learn中支持向量机SVM相关的算法模型。基于支持向量(support vector),scikit-learn主要是包含s三大方面:分类(Classification,SVC、NuSVC、LinearSVC)回归(Regression,SVR、NuSVR、LinearSVR)、异常检测(Outliers detection)。
1、SVM多种分类时的两种分类方法
首先,需要说明,前几篇SVM方法都是针对二分类问题(r如前几篇中的-1和1,支持向量机(Support Vector Machines-SVM)算法笔记(一)-Python,支持向量机SVM-补充完整SMO算法应用(二)-Python),但是,很多时候,往往存在很多类,这时候,sklearn中的SVM模型方法主要有两类分类方式:'one-against-one'和'one-vs-the-rest'(这个也叫'one-vs-all'),具体说明如下:
one-vs-the-rest(one-vs-all)->>训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类,具体见图1
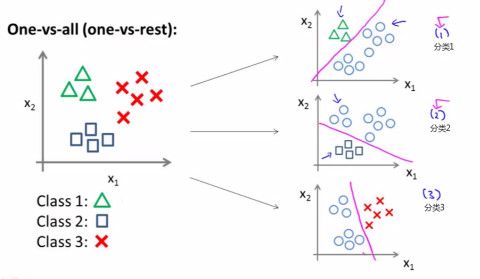
如图1所示,假如有三类要划分,他们是A、B、C。于是我在抽取训练集的时候,分别抽取:1)A所对应的向量作为正集,B,C所对应的向量作为负集;2)B所对应的向量作为正集,A,C所对应的向量作为负集;3)C所对应的向量作为正集,A,B所对应的向量作为负集;使用这三个训练集分别进行训练,然后的得到三个训练结果文件。在测试的时候,把对应的测试向量分别利用这三个训练结果文件进行测试。最后每个测试都有一个结果f1(x),f2(x),f3(x)。于是最终的结果便是这三个值中最大的一个作为分类结果。这种方法有种缺陷,因为训练集是1:M,这种情况下存在偏见.因而不是很实用。可以在抽取数据集的时候,从完整的负集中再抽取三分之一作为训练负集。
one-vs-one(one-against-one)->>其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计k(k-1)/2个SVM。当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。假设有四类A,B,C,D四类。在训练的时候我选择A,B; A,C; A,D; B,C; B,D;C,D所对应的向量作为训练集,然后得到六个训练结果,在测试的时候,把对应的向量分别对六个结果进行测试,然后采取投票形式,最后得到一组结果。投票是这样的:A=B=C=D=0;(A,B)-classifier 如果是A win,则A=A+1;otherwise,B=B+1;(A,C)-classifier 如果是A win,则A=A+1;otherwise, C=C+1;(C,D)-classifier 如果是A win,则C=C+1;otherwise,D=D+1;
最终的结果是A、B、C、D这四个数值中最大的。这种方法虽然好,但是当类别很多的时候,model的个数是n*(n-1)/2,代价还是相当大的。
在sklearn中的多类分类问题中,SVC、NuSVC采用'one-against-one'(即在模型中采用multi_class='ovo'),LinearSVC采用'one-vs-the-rest'多类分类机制(即在模型中采用multi_class='ovr')。
2、SVM核函数
sklearn中的SVM模型涉及的核函数主要如下图2所示:

3、SVC核心算法模型

其实,该算法模型是对应于支持向量机(Support Vector Machines-SVM)算法笔记(一)-Python提到的线性支持向量机,引入了松弛因子。
好哒,简单介绍到这里,接下来,将结合具体的例子来看看SVC、NuSVC、LinearSVC的应用。
4、SVC
class sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=None, random_state=None)
1)该模型是基于线性支持向量机,时间复杂度是n^2(n表示样本数目),因此样本数不要超过10000;2)decision_function_shape ->> ‘ovo’, ‘ovr’ or None, default=None;
5、NuSVC
class sklearn.svm.NuSVC(nu=0.5, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=None, random_state=None)


6、LinearSVC
class sklearn.svm.LinearSVC(penalty='l2', loss='squared_hinge', dual=True, tol=0.0001, C=1.0, multi_class='ovr', fit_intercept=True, intercept_scaling=1, class_weight=None, verbose=0, random_state=None, max_iter=1000)
下面这个实例对比了SVM中采用不同的核函数以及LinearSVC算法的分类效果:


针对上面的实验结果,在sklearn中提到了下面的解释:

在比较SVM(linear kernel)和LinearSVC,提到了hinge loss function(合页损失函数),这是个啥东东呢?好吧,再简单学学机器学习里的损失函数的概念。
在机器学习中,损失函数(loss function)是用来估算模型的预测值(f(x))与真实值y的不一致程度,一般可以表示为如图9所示的经验风险损失项(loss term)和正则化项(regularization term)(关于为什么是这样的和的形式,我感觉监督学习过程的本质目的-误差函数(Loss Function)讲的浅不错),损失函数越小,模型的鲁棒性越好(损失函数的内容参考自Loss functions; a unifying view):
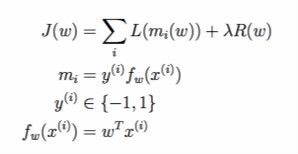
其中,Loss term(L(m_i(w)))主要包含以下形式:Gold Standard(ideal case,也叫做0-1损失函数)、合页损失函数(Hinge loss function,主要是应用在SVM中,在线性支持向量机中,软间隔)、对数损失函数(log loss function,也叫做交叉熵损失函数(cross-entropy loss),主要是应用在logistic regression)、平方损失函数(squared loss function,主要是线性回归中)、指数损失函数(主要应用在Boosting等学习算法中),简介如下:
其中,m_i的存在表示的意义是:如果预估值和实际值同号,那么估计很可能是正确的;如果预估值和实际值符号不同,那么肯定错误,因此,Gold Standard(L_01)提出了如下的函数:
1)Gold Standard(L_01):
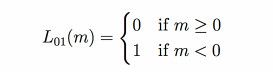
2)合页损失函数(Hinge loss function)(这个主要是在线性SVM中,由于存在软间隔,所以损失函数称为合页损失函数):

3)对数损失函数(log loss function)(主要是在logistic regression应用):

4)平方损失函数(squared loss term):
5)指数损失函数(exponential loss term):
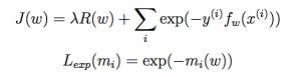
将上述所提到的损失函数的图像表示在图15中,具体如下:
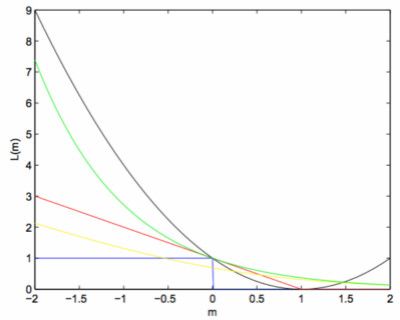
图例说明:Gold Standard(L_01)-》蓝色曲线;合页损失函数(Hinge loss function)-》红色曲线;对数损失函数(log loss function)-》黄色曲线;平方损失函数(squared loss term)-》黑色曲线;指数损失函数(exponential loss term)-》绿色曲线
从上面的红色曲线来看,合页函数在m=1处没有导数,为了便于后续函数可能涉及到的优化,将其变为平方合页函数,其中的一种平方合页函数见图16,来自于维基百科:

此处遗留一个问题,关于合页函数的:针对图8提出的对比说明,'squared hinge loss'和'regular hinge loss'在SVM分类中产生的不同影响是什么?
敬请懂得大神指点,非常感谢~~