摘要: 最近在学习Flink的Fault Tolerance,了解到Flink在Chandy Lamport Algorithm的基础上扩展实现了一套分布式Checkpointing机制,这个机制在论文"Lightweight Asynchronous Snapshots for Distributed Dataflows"中进行了详尽的描述。
阿里巴巴实时计算部-昆仑
最近在学习Flink的Fault Tolerance,了解到Flink在Chandy Lamport Algorithm的基础上扩展实现了一套分布式Checkpointing机制,这个机制在论文"Lightweight Asynchronous Snapshots for Distributed Dataflows"中进行了详尽的描述。怀着对Lamport大神的敬仰,我分别下载研读了两篇论文,在这里把一些阅读的收获记录下来,希望能对学习Flink/Blink的同学能有些帮助。
Chandy Lamport Algorithm
我们先来看看Chandy Lamport Algorithm,“Distributed Snapshots: Determining Global States of a Distributed System”,此文应该是分布式SnapShot的开山之作,发布于1985年(很多同学还没有出生-_-),按照Lamport自己的说法,这篇文章是这么来的:
“The distributed snapshot algorithm described here came about when I visited Chandy, who was then at the University of Texas in Austin. He posed the problem to me over dinner, but we had both had too much wine to think about it right then. The next morning, in the shower, I came up with the solution. When I arrived at Chandy's office, he was waiting for me with the same solution.”
所以说,大神的世界我们不懂,一言不合就写一篇论文。我们言归正传,开始介绍论文中描述的算法。
分布式系统模型和状态定义
分布式系统模型
分布式系统是一个包含有限进程和有限消息通道的系统,这些进程和通道可以用一个有向图描述,其中节点表示进程,边表示通道。如下图所示:p、q分别是进程,c, c'则是消息通道。

另外为了问题描述的简洁,对上述模型还做了假设:消息通道只包含有限的buffer、消息保序、通道可靠等
分布式系统状态(State)
所谓的Distributed Snapshot,就是为了保存分布式系统的State,那么首先我们需要定义清楚什么是分布式系统的State。考虑到上述分布式模型的定义,分布式系统State同样是由“进程状态”和“通道状态”组成的。
Event:分布式系统中发生的一个事件,在类似于Flink这样的分布式计算系统中从Source输入的新消息相当于一个事件。在论文中作者给出了数学化的定义,具体参考论文。
进程状态:包含一个初始状态(initial state),和持续发生的若干Events。初始状态可以理解为Flink中刚启动的计算节点,计算节点每处理一条Event,就转换到一个新的状态。
通道状态:我们用在通道上传输的消息(Event)来描述一个通道的状态。
在某一个时刻的某分布式系统的所有进程和所有通道状态的组合,就是这个分布式系统的全局状态。基于上述的双进程双通道的最简分布式系统,为了描述算法,作者设计了一个“单令牌状态”转换系统,两个进程通过接收和发出令牌,会在S0、S1两个State之间转换,整个分布式系统则会在如下所示的4种全局状态(Global State)之间转换。


Distributed Snapshots
有了系统状态和模型的定义,终于可以开始介绍分布式快照的算法了。对于一个分布式快照算法,我们有如下的两点要求:
正确性:能够准确的记录每一个进程、通道的状态,同时通过这些局部状态,能够准确表达一个分布式系统的全局状态。这里碰到的挑战是,每个进程、通道没法同时记录自身的状态,因为我们没有一个全局的时钟来保持状态记录的同步。
并行性:快照操作与分布式系统计算同时运行,但不能影响所有系统的正常功能,对性能、正确性等无影响。
按照上一小节的描述,全局状态是进程和通道状态的组合,在论文中,作者证明了通道状态可以通过记录进程状态来记录和恢复,并提出了下述的分布式snapshot算法:
对于进程p、q,p->q通过通道c连接,通过以下步骤记录global state
// 进程p行为,通过向q发出Marker,发起snapshot
begin
p record its state;
then
send one Marker along c after p records its state and before p sends further messages along c
end
//进程q接受Marker后的行为,q记录自身状态,并记录通道c的状态
if q has not recorded its state then
begin
q records its state;
q records the state c as the empty sequence
end
else q records the state of c as the sequence of messages received along c after q’s state was recorded and before q received the marker along c.
进程p启动这个算法,记录自身状态,并发出Marker。随着Marker不断的沿着分布式系统的相连通道逐渐传输到所有的进程,所有的进程都会执行算法以记录自身状态和入射通道的状态,待到所有进程执行完该算法,一个分布式Snapshot就完成了记录。Marker相当于是一个信使,它随着消息流流经所有的进程,通知每个进程记录自身状态。且Marker对整个分布式系统的计算过程没有任何影响。只要保证Marker能在有限时间内通过通道传输到进程,每个进程能够在有限时间内完成自身状态的记录,这个算法就能在有限的时间内执行完成。
以上就是这个算法的最主要内容,算法本身不是很复杂,但是Chandy和Lamport两位大神在论文中展现的对问题分析和思考的过程真的很值得玩味,定义问题->定义分布式模型->推导算法->分析特例->证明算法的完备性,层层推进,环环相扣,缺一不可,算法的数学之美展露无遗!
关于Chandy-Lamport Algorithm的主要介绍就到这里,论文中还有一些关于某些特殊情况的证明,大家有兴趣可以参考论文。
Flink Checkpointing的实现原理
Flink 分布式Checkpointing是通过Asynchronous Barrier Snapshots的算法实现的,该算法借鉴了Chandy-Lamport算法的主要思想,同时做了一些改进,这些改进在论文"Lightweight Asynchronous Snapshots for Distributed Dataflows"中进行了详尽的描述,结合这篇论文,我们来看看具体的实现。
Flink流式计算模型
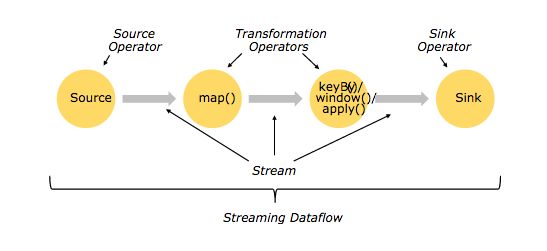
Flink流式计算模型中包含Source Operator、Transformation Operators、Sink Operator等三种不同类型的节点如下图所示,分别负责数据的输入、处理、和输出,对应计算拓扑的起点、中间节点和终点。计算模型的介绍不是我们的重点,细节请参考官方文档-Concepts
Asynchronous Barrier Snapshots
这个算法基本上是Chandy-Lamport算法的变体,只在执行上有一些差别。论文中分别针对有向无环和有向有环的两种计算拓扑图,提出了两种不同的算法,其中后者是在前者的基础上进行了修改,在实际的使用中,绝大部分的系统都是有向无环图,因此我们只会针对前者进行介绍。
在ABS算法中用Barrier代替了C-L算法中的Marker,针对DAG的ABS算法执行流程如下所示:
Barrier周期性的被注入到所有的Source中,Source节点看到Barrier后,会立即记录自己的状态,然后将Barrier发送到Transformation Operator。
当Transformation Operator从某个input channel收到Barrier后,它会立刻Block住这条通道,直到所有的input channel都收到Barrier,此时该Operator就会记录自身状态,并向自己的所有output channel广播Barrier。
Sink接受Barrier的操作流程与Transformation Oper一样。当所有的Barrier都到达Sink之后,并且所有的Sink也完成了Checkpoint,这一轮Snapshot就完成了。
下面这个图展示了一个ABS算法的执行过程:

下面是针对DAG拓扑图的算法伪代码:
// 初始化Operator
upon event (Init | input channels, output
channels, fun, init state)
do
state := init_state;
blocked_inputs := {};
inputs := input_channels;
out_puts := out_put channels;
udf := fun;
// 收到Barrier的行为
upon event (receive | input, (barrier))
do
//将当前input通道加入blocked 集合,并block该通道,此通道的消息处理暂停
if input != Nil then
blocked inputs := blocked inputs ∪ {input};
trigger (block | input);
//如果所有的通道都已经被block,说明所有的barrier都已经收到
if blocked inputs = inputs then
blocked inputs := {};
broadcast (send | outputs, (barrier)); //向所有的outputs发出Barrier
trigger (snapshot | state); //记录本节点当前状态
for each inputs as input //解除所有通道的block,继续处理消息
trigger (unblock | input);
在这个算法中Block Input实际上是有负面效果的,一旦某个input channel发生延迟,Barrier迟迟未到,这会导致Transformation Operator上的其它通道全部堵塞,系统吞吐大幅下降。但是这么做的一个最大的好处就是能够实现Exactly Once。我们来看看Flink文档中的描述:
When the alignment is skipped, an operator keeps processing all inputs, even after some checkpoint barriers for checkpoint n arrived. That way, the operator also processes elements that belong to checkpoint n+1 before the state snapshot for checkpoint n was taken. On a restore, these records will occur as duplicates, because they are both included in the state snapshot of checkpoint n, and will be replayed as part of the data after checkpoint n.
不过Flink还是提供了选项,可以关闭Exactly once并仅保留at least once,以提供最大限度的吞吐能力。
本文仅从原理角度介绍了分布式Snapshot的基本原理以及Flink中的实现,从这篇文章出发,我们还需要阅读相关的源代码以及在实际的开发中去学习和理解。另外本文是基于我自己的理解写就,难免有疏漏和错误,如果大家发现问题,可以留言或者直接联系我,我们一起讨论。
本文为云栖社区原创内容,未经允许不得转载,如需转载请发送邮件至[email protected];如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件至:[email protected] 进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容。
原文链接