第三天主要是讲Pandas、Statsmodels等library,是入门的好材料,但想提高还要多加练习。

前言:
首先,非常感谢Jiang老师将其分享出来!本课件非常经典!
经过笔者亲测,竟然确实只要三天,便可管中窥豹洞见Python及主要库的应用。实属难得诚意之作!
其次,只是鉴于Jiang老师提供的原始课件用英文写成,而我作为Python的爱好者计算机英文又不太熟练,讲义看起来比较慢,为了提高自学课件的效率,故我花了点时间将其翻译成中文,以便将来自己快速复习用。
该版仅用于个人学习之用。
再次,译者因工作中需要用到数据分析、风险可视化与管理,因此学习python,翻译水平有限,请谅解。
在征得原作者Yupeng Jiang老师的同意后,现在我将中文版本分享给大家。
作者:Dr.Yupeng Jiang
- 伦敦大学学院 数学系 (全球顶尖大学,世界排名第7 《2018QS世界大学排名》,英国排名第3)
- 2016年6月5日
- [原版课件来自] https://zhuanlan.zhihu.com/p/21332075
- [中文版的说明] https://zhuanlan.zhihu.com/p/29184240
翻译:Murphy Wan
大纲( Outline)
第1天:Python和科学编程介绍。 Python中的基础知识: 数据类型、控制结构、功能、I/O文件
第2天:用Numpy,Scipy,Matplotlib和其他模块进行计算。 用Python解决一些数学问题。
第3天:时间序列:用Pandas进行统计和实际数据分析。 随机和蒙特卡罗。
开启第三天,首先感谢今天仍在努力的自己

第三天的主要内容
- Pandas
- Stochastics and Monte Carlo (随机与蒙特卡罗)
- Statistical application (统计应用)
- Lab session (实验部分)
01 关于Pandas
- 开发者Wes McKinney从2008年开始专注于开发Pandas,当时在AQR资本管理公司,处理金融数据的定量分析需要高性能和高灵活性的工具。(注释:痛点和需求)
- Pandas是一个开源库,为Python提供高性能,易于使用的数据结构和数据分析工具。
- Python长期以来一直是数据管理和准备的手段,但是对于数据分析和建模来说,确实不太适用。Pandas的诞生填补了这个缺口。
- Pandas线性和面板回归之外没有显著的建模功能。为此,请看Starmodels和Scikit-learn。

Pandas 基础
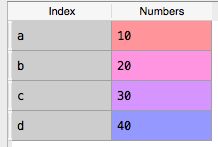
- Numpy通常在Pandas对象上工作。在pandas中,索引和标签数据由DataFrame类管理。它类似于SQL 数据表和电子表格。例如:我们可以创建一个DataFrame对象:
import numpy as np
import pandas as pd
df = pd.DataFrame([10, 20, 30, 40], \
columns = [’Numbers’], \
index = [’a’, ’b’, ’c’, ’d’])
- 让我们看下DataFrame对象。它是显示如下:
- 我们可以执行以下代码在DataFrame对象中显示一些典型的操作。
import pandas as pd
df = pd.DataFrame([10, 20, 30, 40], \
columns = [’Numbers’], \
index = [’a’, ’b’, ’c’, ’d’])
print(df.index) #显示索引 show index
print(df.columns) #显示列名 show column names
print(df.ix[’c’]) #通过索引选择 select via index
print(df.ix[[’a’, ’d’]]) # 多选 multi-select
print(df.ix[df.index[1:3]]) # 其他another
print(df.sum()) # 每列求和 sum per column
ts = df ** 2 # 创建新的DataFrame create new DataFrame
print(ts)
放大DataFrame
import pandas as pd
df = pd.DataFrame([10, 20, 30, 40], \
columns = [’Numbers’], \
index = [’a’, ’b’, ’c’, ’d’])
#add a new column called ’floats’ directly
df[’floats’] = (1.5, 2.5, 3.5, 4.5)
#add a new column called ’names’ by index
df[’names’] = pd.DataFrame([’Dan’, \
’Cox’, ’Ale’, ’Bob’], \
index = [’d’, ’c’, ’a’, ’b’])
# add a new object to df
df = df.append(pd.DataFrame({ \
’Numbers’:66, ’floats’:5.5, \
’names’:’Yor’}, index=[’y’,]))
处理缺失的数据
- 我们通过"join"函数添加一个名为\squares的新列。
df = df.join(pd.DataFrame([1,4,9,16,25], \
index=[’a’, ’b’, ’c’, ’d’, ’x’], \
columns=[’squares’,]),how=’outer’) #<--squares
- 我们注意到没有由“\x”索引的行,且由“\y”索引的行在新列中没有被分配值。这里,我们使用
how=’outer’
- 用来显示所有的潜在数据。
(注释:没太搞清楚这几段话的意思。不过,看代码倒是很清楚,即通过外链outer方式join两张表,会显示所有数据,缺失数据的地方会显示nan。)
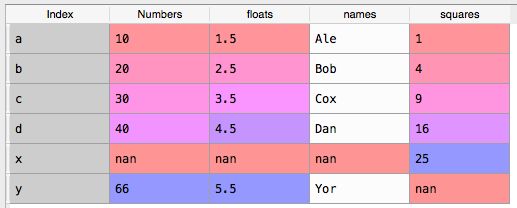
处理金融数据
- Pandas内置函数DataReader从以下网站检索数据:
- Yahoo! Finance (Yahoo)
- Google Finance (Google)
- St. Louis FED (Fred)
- Kenneth French’s data library (Famafrench)
- World Band (via pandas.io.wb)
- 要使用DataReader函数,我们需要
import pandas.io.data as web
富时100数据(FTSE 100 data)
import pandas as pd
import pandas.io.data as web
FT = web.DataReader(name = ’^FTSE’, \
data_source = ’yahoo’, \
start = ’2000-1-1’)
print(FT.info()) # show information
print(FT.tail()) # show last 5 rows
# plot the FTSE 100 graph
FT[’Close’].plot(figsize = (8, 6), \
grid = True)
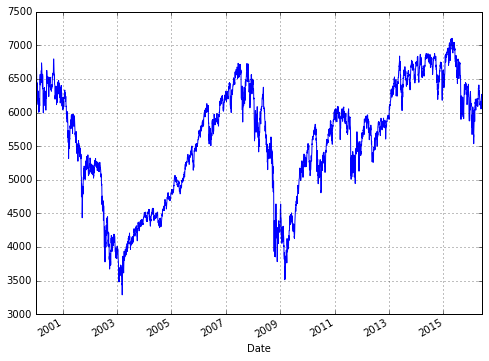
计算每日回报 (Calculate the daily return)
import pandas as pd
import pandas.io.data as web
import numpy as np
FT = web.DataReader(name = ’^FTSE’, \
data_source = ’yahoo’, \
start = ’2000-1-1’)
FT[’Return’] = np.log(FT[’Close’] \
/ FT[’Close’].shift(1))
FT[’Return’].plot(figsize = (8, 6), \
grid = True)
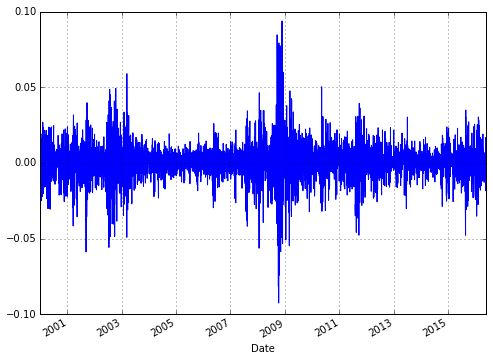
显示数据并同时返回(Show data and return simultaneously)
import pandas as pd
import pandas.io.data as web
import numpy as np
FT = web.DataReader(name = ’^FTSE’, \
data_source = ’yahoo’, \
start = ’2000-1-1’)
![Uploading datasub_463200.png . . .]
FT[’Return’] = np.log(FT[’Close’] \
/ FT[’Close’].shift(1))
FT[[’Close’, ’Return’]].plot( \
subplots = True, style = ’b’, \
figsize = (8, 6), grid = True)

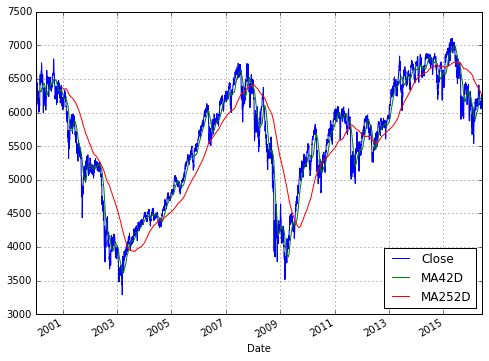
算术交易:移动平均(Algorithmic trading: Moving average)
import pandas as pd
import pandas.io.data as web
import numpy as np
FT = web.DataReader(name = ’^FTSE’, \
data_source = ’yahoo’, \
start = ’2000-1-1’)
FT[’MA42D’] = pd.rolling_mean(FT[’Close’], \
window = 42)
FT[’MA252D’] = pd.rolling_mean(FT[’Close’], \
window = 252)
FT[[’Close’, ’MA42D’, ’MA252D’]].plot( \
figsize = (8, 6), grid = True)
波动率:年化日志回报标准差?(Volatility: Annualised log return StD)
import pandas as pd
import pandas.io.data as web
import numpy as np
FT = web.DataReader(name = ’^FTSE’, \
data_source = ’yahoo’, \
start = ’2000-1-1’)
FT[’Return’] = np.log(FT[’Close’] \
/ FT[’Close’].shift(1))
FT[’Vol’] = np.sqrt(252) * \
pd.rolling_std(FT[’Return’],\
window = 252)
FT[’Vol’].plot(figsize = (8, 6), \
grid = True)

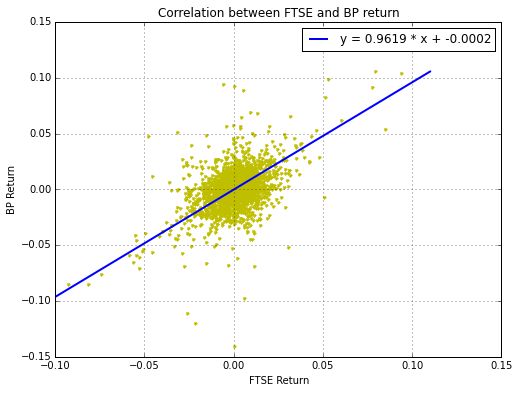
相关和线性回归
-
我们实现一个符合以下目标的代码
捕获富时100指数和英国石油BP(伦敦)的历史价格。
评估这两种资产的历史回报。
对两个回报做线性回归,并获得其回归函数。
(代码在datacorr.py里)
应用实例:配对交易 (pair trading)
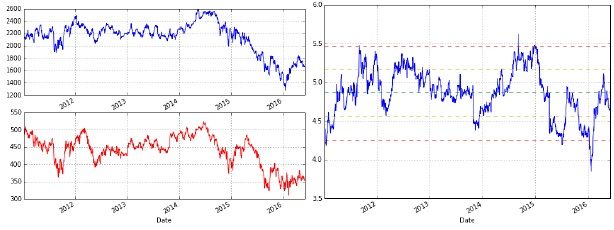
图:
左:从2011-01-01开始,壳牌(B)和BP(伦敦)的历史股价。
右:壳牌和BP的相对性能。
自学Pandas
Pandas的官方文件可以在这里找到:http://pandas.pydata.org/pandas-docs/stable/
官方文档为初学者提供了详细的结构化材料。
与其他软件包类似,只要遇到错误,请检查第一个错误消息。 如果您无法解决问题,请先尝试Google。 大量的人在互联网上问同样的问题。
02随机与蒙特卡罗
用Python产生随机数
- 随机数可以通过numpy.random生成。
import numpy.random as npr
import matplotlib.pyplot as plt
import numpy as np
X = npr.standard_normal((5000))
Y = npr.normal(1, 1, (5000))
Z = npr.uniform(-3, 3, (5000))
W = npr.lognormal(0, 1, (5000))
- 我们可以绘制直方图来检查分布。
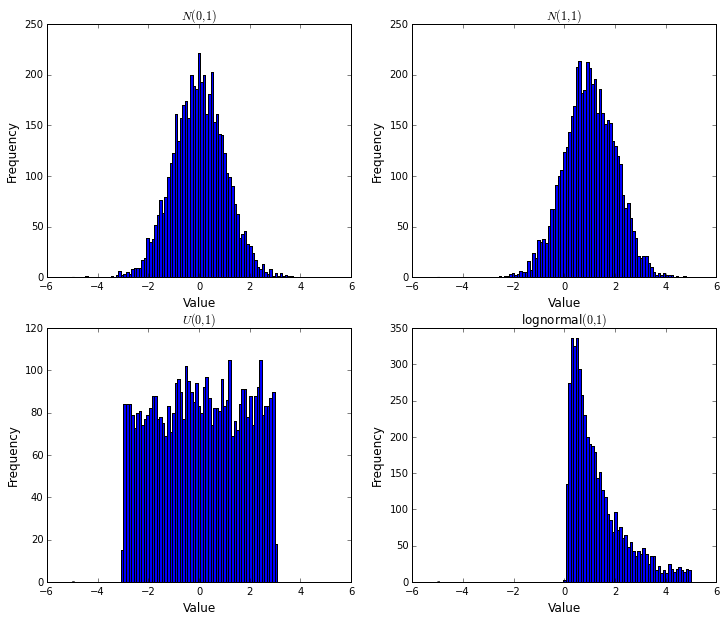
![Uploading FThist_677874.png . . .]
- 图:在前一张幻灯片中生成的随机数的直方图。
蒙特卡洛
- 蒙特卡罗是摩纳哥的一个地区和赌场......

蒙特卡罗方法
第一次人们开始研究蒙特卡罗方法是要评估π。
通过概率论,蒙特卡罗可以用作数值积分法。 例如,
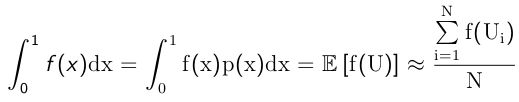
其中p(x)是U(0;1)的概率密度函数。
实践中,蒙特卡罗广泛应用于统计力学,量子物理学,金融衍生产品定价和风险管理。
一个MC示例:期权定价
蒙特卡洛通常用于评估期权价格。
我们不会涉及任何理论推论。 对于欧式看涨期权,其价格可以通过公式给出
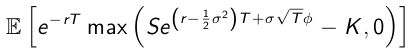
其中S为当前基本股票价格,σ为股票波动率,r为利率,T为期权期权,K为行使价,Φ为标准正态随机变量。
对于这个例子。 让我们假设S = 100,K = 100,
σ= 50%,T = 1,r = 0.05。
通过Python实现MC (MC by Python)
import numpy as np
import numpy.random as npr
from scipy.stats import norm
S = 100; K = 100; T = 1
r = 0.05; vol = 0.5
I = 10000 # MC paths
Z = npr.standard_normal(I)
ST = S * np.exp((r - 0.5 * vol**2) \
* T + vol * np.sqrt(T) * Z)
V = np.mean(np.exp(-r * T) \
* np.maximum(ST - K, 0))
print(V)
蒙特卡罗路径图
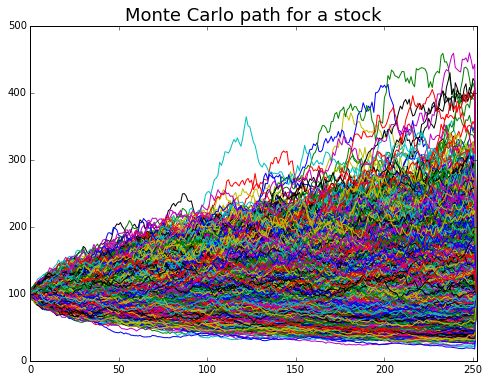
图:一幅蒙特卡罗模拟股票的图。
MC的准确度如何?
-
您运行的所有MC都应同时输出方差或标准偏差。 对于最后一张幻灯片中的代码,我们有结果
- V ≈ 21.54 , std ≈ 0.40
- 实际上,我们有一个封闭式的欧式看涨期权方案
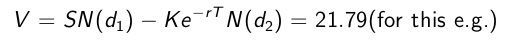
当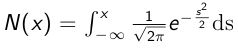

(看到公式不要慌,先冷静哈!慢慢来。)
03统计应用 (Statistical application)
直方图 (Histogram plot)
import pandas as pd
import pandas.io.data as web
import numpy as np
FT = web.DataReader(name = ’^FTSE’,\
data_source = ’yahoo’,\
start = ’2000-1-1’)
FT[’Return’] = np.log(FT[’Adj Close’] \
/ FT[’Adj Close’].shift(1))
FT[’Return’].hist(bins = 100, \
figsize = (8,6))

正态检验:QQ图
我们通常使用分位数分布图(QQ图)来验证该分布是否正常。
-
为了实现QQ图,我们需要一个名为statsmodels的库。 我们导入相应的库
- import statsmodel.api as sm
statsmodels 是一个非常有用的统计分析库,但我们不会给出太多的介绍。
另一个有用的库被称为scikit-learning,它是一个统计和机器学习库。
QQ-plot
import pandas as pd
import pandas.io.data as web
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
FT = web.DataReader(name = ’^FTSE’,\
data_source = ’yahoo’,\
start = ’2000-1-1’)
FT[’Return’] = np.log(FT[’Adj Close’] \
/ FT[’Adj Close’].shift(1))
sm.qqplot(FT[’Return’].dropna(),line=’s’)
plt.grid(True)
plt.xlabel(’Theoretical quantiles’)
plt.ylabel(’Sample quantiles’)
QQ-plot
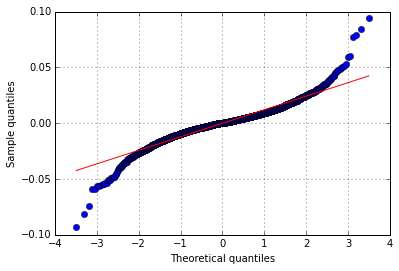
Skew and kurtosis (斜度与峰值?)
import pandas.io.data as web
import numpy as np
import scipy.stats as scs
FT = web.DataReader(name = ’^FTSE’,\
data_source = ’yahoo’,\
start = ’2000-1-1’)
FT[’Return’] = np.log(FT[’Adj Close’] \
/ FT[’Adj Close’].shift(1))
data = FT[’Return’].dropna() # 将缺失值丢掉 leave nan
print(’Skew is %f’ %scs.skew(data))
print(’Skew test p-value is %f’ \
%scs.skewtest(data)[1])
print(’Kurt is %f’ %scs.kurtosis(data))
print(’Kurt test p-value is %f’ \
%scs.kurtosistest(data)[1])
print(’Normal test p-value is %f’ \
%scs.normaltest(data)[1])
- 较小的p值意味着否决数据是正态分布的假设。
04 实验部分 (Lab session)
目标1:蒙特卡罗模拟
-
我有一个随机过程
-
-
其中Φ〜N(0,1)(标准正态分布),t是自变量,表示时间(x轴),参数为
- x0 = 1,θ = 1, μ = 1, σ = 0.5
-
尝试为 t = 10 生成10000个Monte Carlo路径。然后评估您的MC路径的平均值,用解析平均(analytical mean)进行检查
-
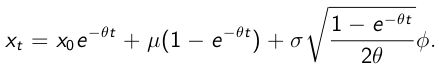
目标2:P&L分析
- 去雅虎网站,试图用Pandas获取以下股票调整后的收盘价
['RDSB.L','BP.L','AAPL','MSFT']
- 然后绘制股票价格。
-
让我们假设两个静态交易策略:
- 原油策略:买1'RDSB.L',卖5'BP.L'
- 科技策略:买3'AAPL', 卖4'MSFT'
尝试获得两个Pandas series,存储的价值两个不同策略的组合。(Try to obtain two pandas series, which stored the value two portfolios of di erent strategies.)
- 尝试评估两种策略的每日损益(P&L)。 每日P&L由以下公式定义:
- 分析两个投资组合的日常损益,分别采用不同的正态检验。 绘制直方图和QQ图。
三天全部结束,辛苦了!想必你也获得了不少收获!继续加油,让我们做的更好!
传送门-->回到第二天(Day1)
传送门-->回到第一天(Day2)
