1 概述
HashMap 是 Java Collection Framework 的重要成员,也是Map族(如下图所示)中我们最为常用的一种。不过遗憾的是,HashMap是无序的。也就是说,迭代HashMap所得到的元素顺序并不是它们最初放置到HashMap的顺序。HashMap的这一缺点往往会造成诸多不便,因为在有些场景中,我们确需要用到一个支持有序的Map。庆幸的是,JDK为我们解决了这个问题,它为HashMap提供了一个子类 —— LinkedHashMap。
LinkedHashMap支持元素迭代时按照插入顺序或者访问顺序进行排序。同时可以作为一个支持LRU算法的缓存容器。
1.1 LRU算法
缓存是一种提高数据读取性能的技术,在硬件设计、软件开发中都有着非常广泛的应用,比如常见的 CPU 缓存、数据库缓存、浏览器缓存等等。
缓存的大小有限,当缓存被用满时,哪些数据应该被清理出去,哪些数据应该被保留?这就需要缓存淘汰策略来决定。常见的策略有三种:先进先出策略 FIFO(First In,First Out)、最少使用策略 LFU(Least Frequently Used)、最近最少使用策略 LRU(Least Recently Used)。
2 使用LinkHashMap
2.1 默认情况按照插入顺序排序
这段代码打印的结果是 3,1,5,2。按照插入顺序排序,最近访问的放在排序的末尾。
HashMap m = new LinkedHashMap<>();
m.put(3, 11);
m.put(1, 12);
m.put(5, 23);
m.put(2, 22);
for (Map.Entry e : m.entrySet()) {
System.out.println(e.getKey());
}
2.2 选择使用访问顺序排序
这段代码打印的结果是 1,2,3,5。按照访问顺序排序,最近访问的放在排序的末尾。
// 10 是初始大小,0.75 是装载因子,true 是表示按照访问时间排序
HashMap m = new LinkedHashMap<>(10, 0.75f, true);
m.put(3, 11);
m.put(1, 12);
m.put(5, 23);
m.put(2, 22);
m.put(3, 26);
m.get(5);
for (Map.Entry e : m.entrySet()) {
System.out.println(e.getKey());
}
2.3 使用LinkHashMap作为支持LRU缓存容器
/**
* 使用LinkedHashMap实现LRU算法
*/
public class LRU extends LinkedHashMap implements Map{
private static final long serialVersionUID = 1L;
public LRU(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor, accessOrder);
}
/**
* 插入元素时触发调用,如果返回true,会自动清理掉排序末尾的元素
**/
@Override
protected boolean removeEldestEntry(java.util.Map.Entry eldest) {
/** 容器中元素超过6,插入前删除排序末尾的元素 **/
if(size() > 6){
return true;
}
return false;
}
public static void main(String[] args) {
LRU lru = new LRU(
16, 0.75f, true);
String s = "abcdefghijkl";
for (int i = 0; i < s.length(); i++) {
lru.put(s.charAt(i), i);
}
System.out.println("LRU中key为h的Entry的值为: " + lru.get('h'));
System.out.println("LRU的大小 :" + lru.size());
System.out.println("LRU :" + lru);
}
}
3 实现原理
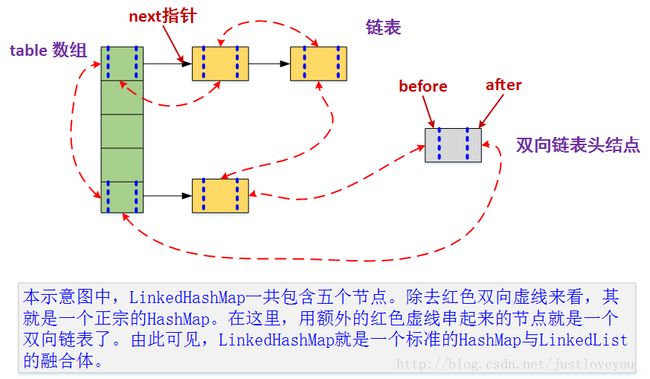
LinkedHashMap之所以能实现Map中元素得排序,从名字就我们就可以看出一些端倪,相比HashMap于LinkedHashMap多一个Link(链表),通过额外维护的双向循环链表保证了迭代顺序。
3.1 实现插入排序
LinkedHashMap通过额外维护的双向循环链表保证了迭代顺序。例如将一个数据对应的Entry添加到哈希表时,同时将其添加到一个链表尾部。这样在链表中保留了元素插入时的顺序。在遍历时只需要从链表中头部开始顺序遍历就可以实现Map中元素按插入顺序排序。
3.2 实现访问排序
和实现插入排序一样,访问排序同样维护一个额外的双向链表保证了迭代顺序,核心思想是在访问Map中元素时,将对应的Entry移动到链表尾部。
// 10 是初始大小,0.75 是装载因子,true 是表示按照访问时间排序
HashMap m = new LinkedHashMap<>(10, 0.75f, true);
m.put(3, 11);
m.put(1, 12);
m.put(5, 23);
m.put(2, 22);
m.put(3, 26);
m.get(5);
for (Map.Entry e : m.entrySet()) {
System.out.println(e.getKey());
}
每次调用 put() 函数,往 LinkedHashMap 中添加数据的时候,都会将数据添加到链表的尾部,所以,在前四个操作完成之后,链表中的数据是下面这样:(和插入排序相同)
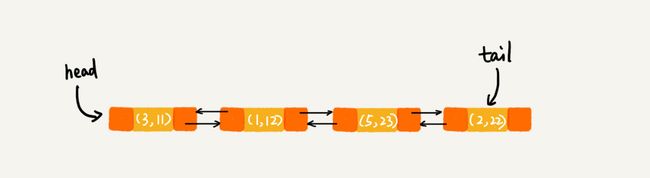
在第 8 行代码中,再次将键值为 3 的数据放入到 LinkedHashMap 的时候,会先查找这个键值是否已经有了,然后,再将已经存在的 (3,11) 删除,并且将新的 (3,26) 放到链表的尾部。所以,这个时候链表中的数据就是下面这样:
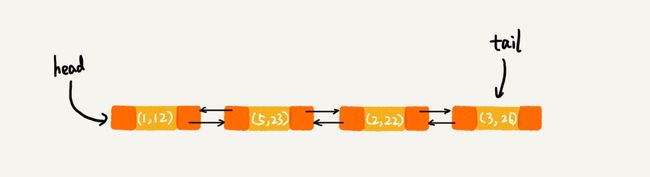
当第 9 行代码访问到 key 为 5 的数据的时候,我们将被访问到的数据移动到链表的尾部。所以,第 9 行代码之后,链表中的数据是下面这样:
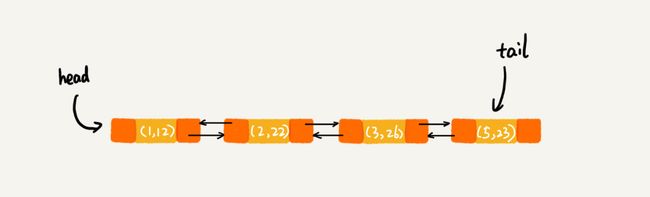
所以,最后打印出来的数据是 1,2,3,5。
3.3 实现LRU
如果理解如何实现访问排序,那么实现LRU只需要在插入元素时判断容器是否已满,如果已满则获取链表头部元素(排序末尾元素),将其从哈希表和链表中删除。
总结一下,实际上,LinkedHashMap 是通过双向链表和散列表这两种数据结构组合实现的。
4 源码解析
4.1 类定义
LinkedHashMap继承于HashMap,其在JDK中的定义为:
public class LinkedHashMap
extends HashMap
implements Map
4.2 核心属性
与HashMap相比,LinkedHashMap增加了两个属性用于保证迭代顺序,分别是 双向链表头结点header 和 标志位accessOrder (值为true时,表示按照访问顺序迭代;值为false时,表示按照插入顺序迭代)。
/**
* 双向链表header节点
*/
private transient Entry header;
/**
* 哈希表的迭代排序方式
* true 表示访问顺序
* false 表示插入顺序。默认为插入顺序
* @serial
*/
private final boolean accessOrder;
基本元素 Entry
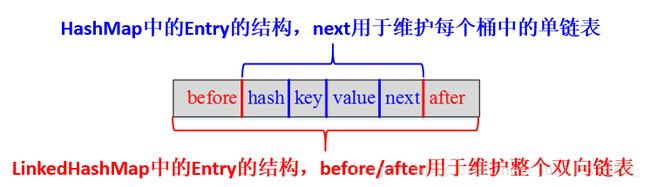
LinkedHashMap采用的hash算法和HashMap相同,但是它重新定义了Entry。LinkedHashMap中的Entry增加了两个指针 before 和 after,它们分别用于维护双向链接列表。特别需要注意的是,next用于维护HashMap各个桶中Entry的连接顺序,before、after用于维护Entry插入的先后顺序的。
/**
* LinkedHashMap 哈希表和双向链表的节点
*/
private static class Entry extends HashMap.Entry {
/** 用于表示双向链表前后节点 **/
Entry before, after;
/** 实例化Entry **/
Entry(int hash, K key, V value, HashMap.Entry next) {
super(hash, key, value, next);
}
形象地,HashMap与LinkedHashMap的Entry结构示意图如下图所示:
4.3 实例化LinkHashMap
LinkHashMap实例化前会先构造父类HashMap,并设置排序方式accessOrder,同时通过重写init方法用来初始用于初始化它所维护的双向链表。
/**
* 用指定的初始容量,装载因子实例化一个空的哈希表
* @param initialCapacity 初始容量
* @param loadFactor 装载因子
*/
public LinkedHashMap(int initialCapacity, float loadFactor) {
/** 调用父类HashMap 构造函数 **/
super(initialCapacity, loadFactor);
/** 设置默认排序方式为插入顺序 **/
accessOrder = false;
}
/**
* 用指定的初始容量和默认装载因子实例化一个空的哈希表
* @param initialCapacity 初始容量
*/
public LinkedHashMap(int initialCapacity) {
/** 调用父类HashMap 构造函数 **/
super(initialCapacity);
/** 设置默认排序方式为插入顺序 **/
accessOrder = false;
}
/**
* 用默认初始容量,默认装载因子实例化一个空的哈希表
*/
public LinkedHashMap() {
/** 调用父类HashMap 构造函数 **/
super();
/** 设置默认排序方式为插入顺序 **/
accessOrder = false;
}
/**
* 用指定哈希映射实例化一个新的哈希表
*/
public LinkedHashMap(Map m) {
super(m);
accessOrder = false;
}
/**
* 用指定的初始容量和默认装载因子已经排序方式实例化一个空的哈希表
*
* @param initialCapacity 初始容量
* @param loadFactor 装载因子
* @param accessOrder 排序方式
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
4.3.1 重写init
HashMap的构造函数都会在最后调用一个init()方法进行初始化,只不过这个方法在HashMap中是一个空实现,而在LinkedHashMap中重写了它用于初始化它所维护的双向链表。
/**
* 实例化哈希表过程中调用的模板方法
*/
@Override
void init() {
/** 初始化双向链表头节点 **/
header = new Entry<>(-1, null, null, null);
header.before = header.after = header;
}
4.4 插入数据
LinkedHashMap没有对 put(key,vlaue) 方法进行任何直接的修改,完全继承了HashMap的 put(Key,Value) 方法,也就是继承了HashMap插入数据的主流程,同时对部分方法功能进行重写用来维护双向链表结构。
具体流程如下:
1 第一次put时哈希表并为创建,调用inflateTable(threshold)构建哈希表
2 如果添加key为null,调用putForNullKey处理,放入哈希表数组table[0]位置
3 计算key hash值,并计算hash对应哈希表桶位置i。
-
4 判断table[i]是否存在元素Entry,如果存在则从Entry开始,作为链表的头部元素,向后遍历查找key&hash相同元素Entry(用来表示插入的key-value以存在于Map中)如果找到则覆盖Entry.value,并调用Entry对象recordAccess方法,返回原始值。
- LinkedHashMap.Entry重写了HashMap.Entry recordAccess方法.将元素对应Entry从链表原始位置移动到链表的尾部。
-
5 重写父类中HashMap.addEntry方法
- 调用父类addEntry方法,其内部重写调用createEntry方法,创建一个Entry,next指向的原始table[bucketIndex],储到table[bucketIndex]指定下标位置,并插入双向链表尾部,支持扩容
- 预留removeEldestEntry方法判断是否将链表头部节点元素从Map中删除,用来淘汰排序末尾的元素
- 调用父类removeEntryForKey方法,从Map获取指定的key对应Entry节点,并将Entry节点从哈希表中剔除,并调用Entry对象recordRemoval,LinkedHashMap.Entry类重写了 Hash.Entry类中recordRemoval,将Entry节点从链表中删除
/**
* 向Map添加一个key-value结构,如果key存在返回于Map中,会覆盖value返回原始值
*/
public V put(K key, V value) {
/** 1 第一次put时哈希表并为创建,调用inflateTable(threshold)构建哈希表 **/
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
/** 2 如果添加key为null,调用putForNullKey处理,放入哈希表数组table[0]位置 **/
if (key == null)
return putForNullKey(value);
/** 3 计算key hash值,并计算hash值映射哈希表下标位置。 **/
int hash = hash(key);
int i = indexFor(hash, table.length);
/**
* 4 判断table[i]是否存在元素Entry,如果存在则从Entry开始,作为链表的头部元素,
* 向后遍历查找key&hash相同元素Entry(用来表示插入的key-value以存在于Map中)
* 如果找到则覆盖Entry.value,并调用重写recordAccess,返回原始值
*/
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
/** 修改次数+1 **/
modCount++;
/** 调用重写addEntry方法 **/
addEntry(hash, key, value, i);
return null;
}
private static class Entry extends HashMap.Entry {
/** 用于表示双向链表前后节点 **/
Entry before, after;
/** 实例化Entry **/
Entry(int hash, K key, V value, HashMap.Entry next) {
super(hash, key, value, next);
}
/**
* 如果链表中元素按照访问顺序排序,则将当前访问的Entry从链表的原始位置移动到双向循环链表的尾部,
* 如果是按照插入的先后顺序排序,则不做任何事情。
*/
void recordAccess(HashMap m) {
LinkedHashMap lm = (LinkedHashMap)m;
/** 如果链表中元素按照访问顺序排序,则将当前访问的Entry从链表的原始位置移动到双向循环链表的尾头部,**/
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
重写addEntry
public class LinkedHashMap
extends HashMap
implements Map
{
...省略代码
/**
* 重写父类中HashMap.addEntry方法
* 1 调用父类addEntry方法,其内部重写调用createEntry方法,创建一个Entry,next指向的原始table[bucketIndex],
* 储到table[bucketIndex]指定下标位置,并插入双向链表尾部,支持扩容
* 2 预留removeEldestEntry方法判断是否将链表尾部节点元素从Map中删除,用来淘汰排序末尾的元素
* 3 调用父类removeEntryForKey方法,从Map获取指定的key对应Entry节点,并将Entry节点从哈希表中剔除,并调用Entry对象recordRemoval,
* LinkedHashMap.Entry类重写了 Hash.Entry类中recordRemoval,将Entry节点从链表中删除
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
/**
* 1 调用父类addEntry方法,其内部重写调用createEntry方法,创建一个Entry,next指向的原始table[bucketIndex],
* 储到table[bucketIndex]指定下标位置,并插入双向链表头部,支持扩容 **/
super.addEntry(hash, key, value, bucketIndex);
/** 获取链表头部节点Entry **/
Entry eldest = header.after;
/** 2 预留removeEldestEntry方法判断是否将链表头部节点元素从Map中删除,用来淘汰访问排序末尾的元素 **/
if (removeEldestEntry(eldest)) {
/**
* 3 从Map获取指定的key对应Entry节点,并将Entry节点从哈希表中剔除,并调用Entry对象recordRemoval,
* LinkedHashMap.Entry类重写了 Hash.Entry类中recordRemoval,将Entry节点从链表中删除 **/
removeEntryForKey(eldest.key);
}
}
...省略代码
}
public class LinkedHashMap
extends HashMap
implements Map
{
...省略代码
/**
* 从Map获取删除指定的key对应Entry,并将Entry从哈希表中剔除,并调用Entry对象recordRemoval
*/
final Entry removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
/** 计算key hash值 **/
int hash = (key == null) ? 0 : hash(key);
/** 计算hash值映射哈希表下标位置 **/
int i = indexFor(hash, table.length);
Entry prev = table[i];
Entry e = prev;
/** 从Map获取删除指定的key对应Entry,并将Entry从哈希表中剔除,并调用e.recordRemoval **/
while (e != null) {
Entry next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
protected boolean removeEldestEntry(Map.Entry eldest) {
return false;
}
...省略代码
}
private static class Entry extends HashMap.Entry {
/** 用于表示双向链表前后节点 **/
Entry before, after;
/** 实例化Entry **/
Entry(int hash, K key, V value, HashMap.Entry next) {
super(hash, key, value, next);
}
...省略代码
/**
* 将当前节点Entry从链表删除
*/
void recordRemoval(HashMap m) {
remove();
}
/**
* 将当前节点Entry从链表删除
*/
private void remove() {
before.after = after;
after.before = before;
}
...省略代码
}
重写createEntry
/**
* 重写父类中HashMap.createEntry方法
* 创建一个Entry,next指向的原始table[bucketIndex],存储到table[bucketIndex]指定下标位置,并插入双向链表尾部
*/
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry old = table[bucketIndex];
Entry e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
}
private static class Entry extends HashMap.Entry {
/** 用于表示双向链表前后节点 **/
Entry before, after;
/** 实例化Entry **/
Entry(int hash, K key, V value, HashMap.Entry next) {
super(hash, key, value, next);
}
...省略代码
/**
* 将当前节点Entry添加到链表head到链表的尾部。
*/
private void addBefore(Entry existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
...省略代码
4.4 查询数据
LinkHashMap重写父类get方法,首先调用父类getEntry获取哈希表中的节点
Entry,同时调用Entry对象recordAccess方法,LinkedHashMap.Entry重写了HashMap.Entry recordAccess方法.将元素对应Entry从链表原始位置移动到链表的尾部。最后返回value
public V get(Object key) {
Entry e = (Entry)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}
4.5 删除数据
LinkedHashMap没有对 remove(key,vlaue) 方法进行任何直接的修改,完全继承了HashMap的 remove(Key,Value) 方法
,在删除元素前会调用recordRemoval,LinkedHashMap.Entry类重写了 Hash.Entry类中recordRemoval,将Entry节点从链表中删除
/**
* 从Map删除指定的key
*/
public V remove(Object key) {
Entry e = removeEntryForKey(key);
return (e == null ? null : e.value);
}
/**
* 从Map获取指定的key对应Entry节点,并将Entry节点从哈希表中剔除,并调用Entry对象recordRemoval,
*/
final Entry removeEntryForKey(Object key) {
if (size == 0) {
return null;
}
/** 计算key hash值 **/
int hash = (key == null) ? 0 : hash(key);
/** 计算hash值映射哈希表下标位置 **/
int i = indexFor(hash, table.length);
Entry prev = table[i];
Entry e = prev;
/** 从Map获取删除指定的key对应Entry,并将Entry从哈希表中剔除,并调用e.recordRemoval **/
while (e != null) {
Entry next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
4.6 重写迭代器
/**
* LinkedHashMap迭代器
* 相对于HashMap,LinkedHashMap通过遍历双向链表来获取元素
*/
private abstract class LinkedHashIterator implements Iterator {
Entry nextEntry = header.after;
Entry lastReturned = null;
int expectedModCount = modCount;
/**
* 是否还有下一个元素
*/
public boolean hasNext() {
return nextEntry != header;
}
/**
* 删除当前元素
*/
public void remove() {
if (lastReturned == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
LinkedHashMap.this.remove(lastReturned.key);
lastReturned = null;
expectedModCount = modCount;
}
/**
* 获取下一个元素
*/
Entry nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (nextEntry == header)
throw new NoSuchElementException();
Entry e = lastReturned = nextEntry;
nextEntry = e.after;
return e;
}
}
private class KeyIterator extends LinkedHashIterator {
public K next() { return nextEntry().getKey(); }
}
private class ValueIterator extends LinkedHashIterator {
public V next() { return nextEntry().value; }
}
private class EntryIterator extends LinkedHashIterator> {
public Map.Entry next() { return nextEntry(); }
}