1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
学习笔记
0周介绍这门课主要掌握定向网络数据爬取还有网页解析的基本能力 ,这个课程 主要内容有自动爬取HTML页面 还有自动网络数据的请求提交,还有爬虫需要注意的合法规则,解析HTML页面,还有最后实在项目a/b,最后用一个正则表达式详解来提取页面相关关键信息 还有网络爬虫原理的介绍 专业爬虫框架介绍
第二节介绍了常用的python IDE工具 有文本类的自带IDE,还有sublime text,还有集成工具类的IDE有pycharm ,anaconda和Spyder 适合自己的工具使用
第一周
导读介绍和0周一样
{第一单元}
第一章request库的安装 最好简单 安装方法 pip安装 我也跟视频安装了 这是截图

然后是调试截图
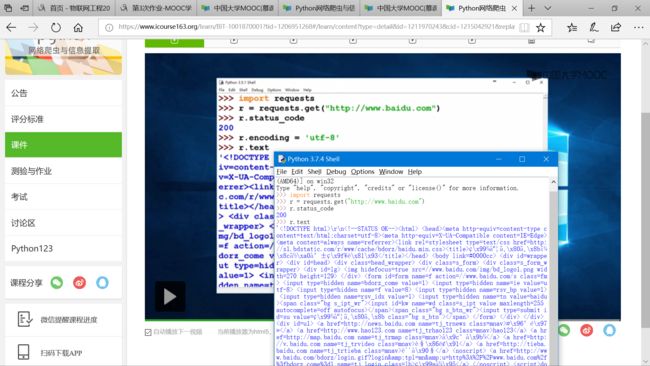
然后有7个主要方法接下来介绍详细7个方法
第二章
介绍requests.get的介绍
requests.ge(url,params=None,**kwarges)
url获取页面的url链接
Params url中额外参数 可选
**kwarges 12个控制访问参数
介绍response对象的属性 有五个,
分别是
r.status_code,返回200表示连接成功 其他数据都是失败
r.text, url对应页面内容
r.encoding, 猜测响应内容的编码 可能不准 iso-8859-1就是不准
r.apparent_encoding,响应内容的编码方式,比较准
r.content HTTP响应二进制内容、
第三章
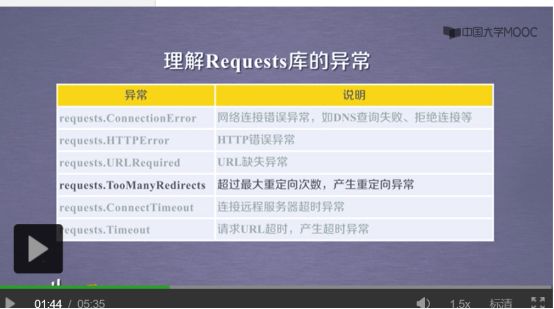
理解Requests库的异常有6种


第三章
爬取网页代码框架
第四章
http协议及Requests库方法
先理解HTTP协议
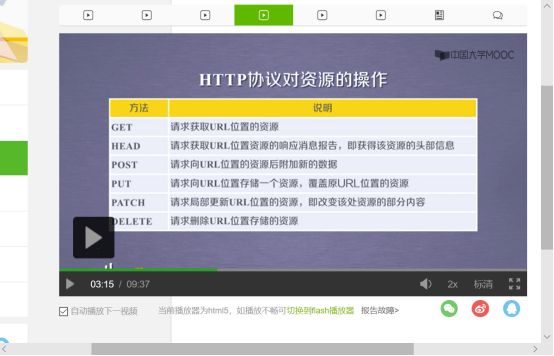

单元小结
重点requests.get和requests.head
通用框架

第二单元
网络爬虫引发的问题,3类,网页requests,网站scrapy和全网(定制开发)
法律风险,骚扰问题,网络爬虫限制
robots协议 网络爬虫限制标准
遵守方式
可以不遵守,但需要负法律责任 类人行为可以不参考 让我们遵守
第三单元
实战
搜索和图片的爬取和存储
获取IP地址
第二周
安装Beautiful Soup库安装还是正常的pip安装,然后就是了解
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
Tag NavigableString BeautifulSoup Comment
3种遍历方式:
上行遍历,下行遍历,平行遍历。bs4库还有三种信心标记的方法:XML:标签:
第三周
讲的都是实战部分主要讲Re库:
正则表达式:是用来简洁表达一组字符串的表达式;是一种通用的字符串表达框架;进一步,正则表达式是一种针对字符串表达“简洁”和“特征”思想的工具,可以用来判断某字符串的特征归属。
对Re库的主要功能函数(search、match、findall、finditer、sub)进行了解和使用,Re库的函数式法为一次性操作,还有一种为面向对象法,通过compile生成的regex对象
第四周:
讲解了Scrapy的爬虫框架结构, 爬虫框架是实现爬虫功能的一个软件结构和功能组件集合,同时爬虫框架是一个半成品, 能够帮助用户实现专业
网络爬虫。在和request库相比中,如果是非常小的需求,则使用request库。不太小的需求则用Scrapy库。而且Scrapy库并发性好,性能较高
应用Scrapy爬虫框架主要是编写配置型代码:
进入工程目录,执行scrapy genapider demo pyth
该命令作用:
(1)生成一个名称为demo的spider
(2)在spiders目录下增加代码文件demo.py(该命令仅用于生成demo.py,该文件也可以手工生成)
运行爬虫,获取网页命令:scrapy crawl demo
yield关键字的使用:
包含yield语句的函数是一个生成器,生成器每次产生一个值(yield),函数被冻结,被唤醒后再产生一个值,生成器是一个不断产生值得函数