引言
Intel新的SKYLAKE微处理架构自15年发布至今,已经相对成熟可以进入商用阶段,最近很多供货商也都在积极推广;公司之前用的主要都是Sandy bridge架构,18年据说也要停产了,所以需要考虑升级相关事宜。从供货商那边选了两款样机,准备详细测试下网络性能,是否有针对之前架构有性能提升,及提升效能能到多少。
本文主要记录下测试方法,以及测试过程中遇到的问题和解决步骤,具体的测试对比结果只在内部开放,请谅解。
理论知识
Intel Skylake是英特尔第六代微处理器架构,采用14纳米制程,是Intel Haswell微架构及其制程改进版Intel Broadwell微架构的继任者, 提供更高的CPU和GPU性能并有效减少电源消耗。
主要特性包括:
- 14纳米制程,6th Gen processor
- 同时支持DDR3L和DDR4-SDRAM两种内存规格,最高支持64GB;
- PCIE支持3.0,速度最高支持8GT/s;
- 去掉了Haswell引入的FIVR,使用分离的PCH,DMI3.0
测试拓扑及环境准备
| 项目 | 描述 |
|---|---|
| 操作系统 | linux,内核2.6.X (影响不大) |
| CPU | Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz |
| 内存 | 32GB |
| 网卡芯片 | intel x710,4口10G |
| dpdk版本 | dpdk-16.04 |
| 测试程序 | l2fwd,l3fwd |
| 测试套件 | Spirent RFC 2544套件 |
使用dpdk sample程序前需要做一些初始化动作,加载对应的module、驱动,配置对应的大页内存等,写了个初始化脚本如下:
#!/bin/bash
mount -t hugetlbfs nodev /mnt/huge
#set hugepage memory
echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
#add kernel module
modprobe uio
insmod /root/dpdk-16.04/x86_64-native-linuxapp-gcc/kmod/igb_uio.ko
#down interfaces to disable routes
#ifconfig eth0 down
#display netcard driver before bind
/root/dpdk-16.04/tools/dpdk_nic_bind.py -s
#bind driver
/root/dpdk-16.04/tools/dpdk_nic_bind.py -b igb_uio 0000:01:00.0
/root/dpdk-16.04/tools/dpdk_nic_bind.py -b igb_uio 0000:01:00.1
/root/dpdk-16.04/tools/dpdk_nic_bind.py -b igb_uio 0000:01:00.2
/root/dpdk-16.04/tools/dpdk_nic_bind.py -b igb_uio 0000:01:00.3
#display netcard driver after bind
/root/dpdk-16.04/tools/dpdk_nic_bind.py -s
具体的测试拓扑如下:

测试过程及问题解决
由于dpdk的sample运行时需要手动绑定端口和CPU核的关系,所以在运行前最好能了解当前的核分布情况:
root>python cpu_layout.py
============================================================
Core and Socket Information (as reported by '/proc/cpuinfo')
============================================================
cores = [0, 1, 2, 3]
sockets = [0]
Socket 0
--------
Core 0 [0, 4]
Core 1 [1, 5]
Core 2 [2, 6]
Core 3 [3, 7]
可以看出cpu有一个物理核,4个逻辑核,已经开启了超线程。
一个口自收自发
先测试最简单的情况,一个口自收自发,看能否达到线速。
- 使用l2fwd测试,1口1队列
l2fwd -c0xf -n4 -- -p0x1
测试结果(两组数据,后面的效果更好但没测全,但都无法达到线速):


- 使用l2fwd测试,1口4队列(标准的l2fwd不支持,需要修改代码支持)
l2fwd -c0xf -n4 -- -p0x1 -q4
测试结果:
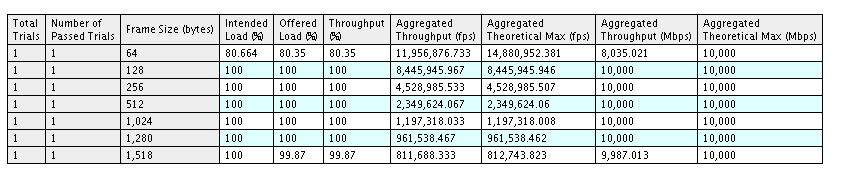
理论上应该还能提升的,待进一步优化。
- 使用l3fwd测试,1口1队列
命令如下:
l3fwd -l 0 -n4 -- -p1 -P --config="(0,0,0)"
测试结果:

- 使用l3fwd测试,1口2队列
命令如下:
./l3fwd -l 0,1 -n4 -- -p1 -P --config="(0,0,0)(0,1,1)"
使用lcore 0,1, 端口1两个队列,每个队列绑定一个lcore
测试结果:
结论:性能瓶颈和每个端口上的队列有关系,和CPU基本没关系。当使用l3fwd测试时,小包可以达到限速。使用l2fwd测试时,标准版本效果不是特别满意,估计还是l2fwd的单队列和转发模型太过简单。
两个口互相转发
接着测试两个口互相转发,看能否限速转发。
直接测试最优的情况,使用l3fwd每个端口2队列
./l3fwd -l 0,1,2,3 -n4 -- -p0xf -P --config="(0,0,0)(0,1,1)(1,0,2)(1,1,3)"
测试结果:
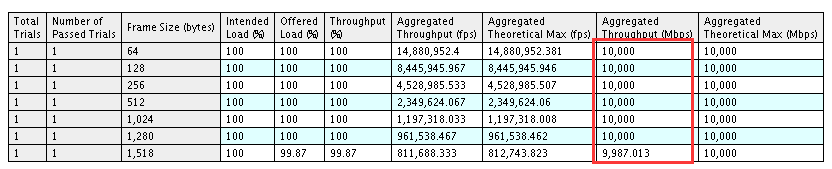
在这个测试过程中遇到一个问题,两个完全相同的平台,一个平台64字节可以线速转发,另外一个只能到9%左右,如下图:

排查思路:
- 首先确定接口绑定是否正确,测试的软件版本等是否一致。
- 查看网卡芯片的参数,确保使用PCI3 Gen3 x8 or Gen3 x16
lspci -s 01:00.1 -vv | grep LnkSta
LnkSta: Speed 8GT/s, Width x4, TrErr- Train- SlotClk+ DLActive- BWMgmt- ABWMgmt-
LnkSta2: Current De-emphasis Level: -6dB, EqualizationComplete-,
本次排查过程中发现出问题的网卡width参数为x4, 正常的网卡参数为x8. 这块需要重点跟踪下,x4的通道直接就减半了,通过和厂家沟通主板上拉出的通道是支持x8的,可能的原因是网卡金手指上贴了胶带,经过排查果然如此,之前测试x4的插槽时,做了相关动作。

- 网卡参数正常后,发现测试结果仍然无法达到另外一个平台测试的理想结果,此时可以查看l3fwd的启动日志,看看网口启动选择rx和tx函数是否一致:
发现正常的平台log信息如下:
Initializing rx queues on lcore 4 ... rxq=1,1,0 PMD: check_rx_burst_bulk_alloc_preconditions(): Rx Burst Bulk Alloc Preconditions: rxq->nb_rx_desc=4096, I40E_MAX_RING_DESC=4096, RTE_PMD_I40E_RX_MAX_BURST=32
PMD: check_rx_burst_bulk_alloc_preconditions(): Rx Burst Bulk Alloc Preconditions: rxq->nb_rx_desc=4096, I40E_MAX_RING_DESC=4096, RTE_PMD_I40E_RX_MAX_BURST=32
PMD: i40e_dev_rx_queue_setup(): Rx Burst Bulk Alloc Preconditions are not satisfied, Scattered Rx is requested, or RTE_LIBRTE_I40E_RX_ALLOW_BULK_ALLOC is not enabled on port=1, queue=1.
PMD: i40e_set_tx_function(): Vector tx finally be used.
PMD: i40e_pf_config_rss(): Max of contiguous 2 PF queues are configured
PMD: i40e_set_rx_function(): Port[0] doesn't meet Vector Rx preconditions
PMD: i40e_set_rx_function(): Rx Burst Bulk Alloc Preconditions are not satisfied, or Scattered Rx is requested (port=0).
PMD: i40e_set_tx_function(): Vector tx finally be used.
PMD: i40e_pf_config_rss(): Max of contiguous 2 PF queues are configured
PMD: i40e_set_rx_function(): Port[1] doesn't meet Vector Rx preconditions
PMD: i40e_set_rx_function(): Rx Burst Bulk Alloc Preconditions are not satisfied, or Scattered Rx is requested (port=1).
而异常的平台log信息如下:
Initializing rx queues on lcore 0 ... rxq=0,0,0 PMD: i40e_dev_rx_queue_setup(): Rx Burst Bulk Alloc Preconditions are satisfied. Rx Burst Bulk Alloc function will be used on port=0, queue=0.
Initializing rx queues on lcore 1 ... rxq=0,1,0 PMD: i40e_dev_rx_queue_setup(): Rx Burst Bulk Alloc Preconditions are satisfied. Rx Burst Bulk Alloc function will be used on port=0, queue=1.
Initializing rx queues on lcore 2 ... rxq=1,0,0 PMD: i40e_dev_rx_queue_setup(): Rx Burst Bulk Alloc Preconditions are satisfied. Rx Burst Bulk Alloc function will be used on port=1, queue=0.
Initializing rx queues on lcore 3 ... rxq=1,1,0 PMD: i40e_dev_rx_queue_setup(): Rx Burst Bulk Alloc Preconditions are satisfied. Rx Burst Bulk Alloc function will be used on port=1, queue=1.
PMD: i40e_set_tx_function(): Vector tx finally be used.
PMD: i40e_pf_config_rss(): Max of contiguous 2 PF queues are configured
PMD: i40e_set_rx_function(): Port[0] doesn't meet Vector Rx preconditions
PMD: i40e_set_rx_function(): Rx Burst Bulk Alloc Preconditions are satisfied. Rx Burst Bulk Alloc function will be used on port=0.
PMD: i40e_set_tx_function(): Vector tx finally be used.
PMD: i40e_pf_config_rss(): Max of contiguous 2 PF queues are configured
PMD: i40e_set_rx_function(): Port[1] doesn't meet Vector Rx preconditions
PMD: i40e_set_rx_function(): Rx Burst Bulk Alloc Preconditions are satisfied. Rx Burst Bulk Alloc function will be used on port=1.
可以看出应该是nb_rx_desc 和 nb_tx_desc的设置不一样导致的rx模式选择不一样,正常的选择的是rx_recv_pkts,异常的选择的是i40e_recv_pkts_bulk_alloc。现修改成一致的,测试通过。
结论:2端口互相转发,64字节也能达到线速转发;存疑点:Burst模式应该是优于普通模式的,但实际的测试结果却不是,应该有优化选项没设置对,后续还要跟踪下。
四个口互相转发
接着测试四口相互转发,重点关注小包是否能够线速
测试命令:
- 每个口一个队列,一个核:
./l3fwd -l 0,1,2,3 -n4 -- -p0xf -P --config="(0,0,0)(1,0,1)(2,0,2)(3,0,3)"
测试结果:


两个平台测试参数略有差异,最高也就到53%~55%左右。
- 使用超线程,每个口两个队列,每个队列一个核
l3fwd -l 0,1,2,3,4,5,6,7 -n4 -- -p0xf -P --config="(0,0,0)(0,1,1)(1,0,2)(1,1,3)(2,0,4)(2,1,5)(3,0,6)(3,1,7)"
测试结果:


- 使用超线程,每个口两个队列,每个口一个核
./l3fwd -l 0,1,2,3,4,5,6,7 -n4 -- -p0xf -P --config="(0,0,0)(0,1,0)(1,0,1)(1,1,1)(2,0,2)(2,1,2)(3,0,3)(3,1,3)"
测试结果:
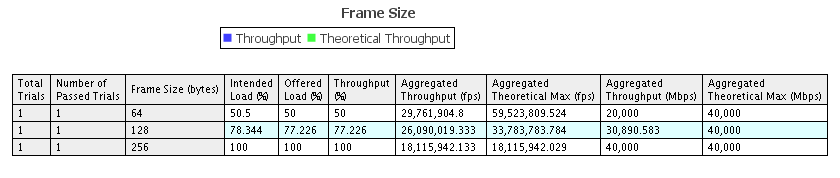
而此时cpu的利用情况如下:

结论:4个口小包无法达到线速转发,此时CPU已经满负载(瓶颈所在),256字节之后可以。另外,发现开启超线程对性能没有太大提升,如果核的分配出现竞争的情况(如最后一次测试),性能反而会下降。
总结
以上是完整的测试过程,以及测试过程中遇到和解决问题的思路,希望能对大家有益。 关于l2fwd测试的效率低下这块,后续还会再修改代码继续研究,如果有成果,再和大家分享。