本文为《Flink大数据项目实战》学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程:
Flink大数据项目实战:http://t.cn/EJtKhaz
1. Kafka-connector概述及FlinkKafkaConsumer(kafka source)
1.1回顾kafka
1.最初由Linkedin 开发的分布式消息中间件现已成为Apache顶级项目
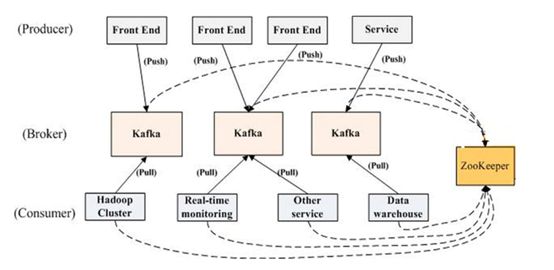
2.面向大数据
3.基本概念:
1.Broker
2.Topic
3.Partition
4.Producer
5.Consumer
6.Consumer Group
7.Offset( 生产offset , 消费offset , offset lag)
1.2引入依赖
Flink读取kafka数据需要通过maven引入依赖:

1.3Flink KafkaConsumer
Flink KafkaConsumer目前已经出现了4个大的版本:FlinkKafkaConsumer08、FlinkKafkaConsumer09、FlinkKafkaConsumer10和FlinkKafkaConsumer11.
FlinkKafkaConsumer08和FlinkKafkaConsumer09都继承FlinkKafkaConsumerBase,FlinkKafkaConsumerBase内部实现了CheckpointFunction接口和继承RichParallelSourceFunction类。
FlinkKafkaConsumer11继承FlinkKafkaConsumer10,FlinkKafkaConsumer10继承FlinkKafkaConsumer09。FlinkKafkaConsumer081和FlinkKafkaConsumer082继承FlinkKafkaConsumer08。
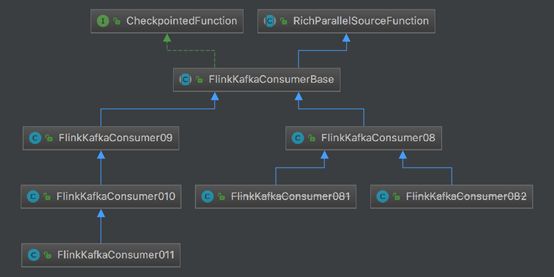
1.4 FlinkKafkaConsumer010
FlinkKafkaConsumer010(String topic, DeserializationSchema
FlinkKafkaConsumer010(String topic, KeyedDeserializationSchema
FlinkKafkaConsumer010(List
FlinkKafkaConsumer010(List
FlinkKafkaConsumer010(Pattern subscriptionPattern, KeyedDeserializationSchema
三个构造参数:
1.要消费的topic(topic name / topic names/正表达式)
2.DeserializationSchema / KeyedDeserializationSchema(反序列化Kafka中的数据)
3.Kafka consumer的属性,其中三个属性必须提供:
a)bootstrap.servers (逗号分隔的Kafka broker列表)
b)zookeeper.connect (逗号分隔的Zookeeper server列表) (仅Kafka 0.8需要)
c)group.id(consumer group id)
1.5反序列化Schema类型
作用:对kafka里获取的二进制数据进行反序列化
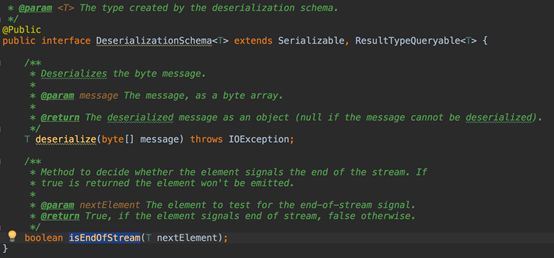
FlinkKafkaConsumer需要知道如何将Kafka中的二进制数据转换成Java/Scala对象,DeserializationSchema定义了该转换模式,通过T deserialize(byte[] message)
FlinkKafkaConsumer从kafka获取的每条消息都会通过DeserializationSchema的T deserialize(byte[] message)反序列化处理
反序列化Schema类型(接口):
1.DeserializationSchema(只反序列化value)
2.KeyedDeserializationSchema
1.6 DeserializationSchema接口
1.7 KeyedDeserializationSchema接口

1.8常见反序列化Schema
SimpleStringSchema
JSONDeserializationSchema / JSONKeyValueDeserializationSchema
TypeInformationSerializationSchema/ TypeInformationKeyValueSerializationSchema(适合读写均是flink的场景)
AvroDeserializationSchema
1.9 FlinkKafkaConsumer010最简样版代码

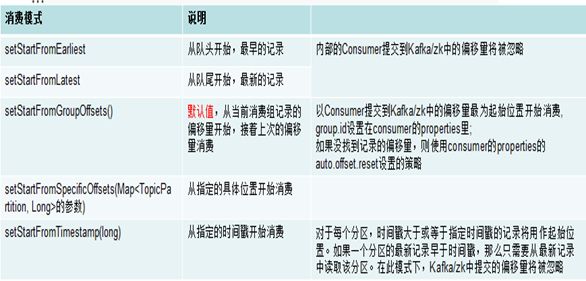
1.10 FlinkKafkaConsumer消费模式设置(影响从哪里开始消费)
设置FlinkKafkaConsumer消费模式示例代码如下所示:

不同消费模式的解释如下所示:
注意1:kafka 0.8版本, consumer提交偏移量到zookeeper,后续版本提交到kafka(一个特殊的topic: __consumer_offsets)
注意2:当作业从故障中恢复或者从savepoint还原时,上述设置的消费策略将不能决定开始消费的位置,真正的起始位置由保存点或检查点中存储的偏移量。
1.11理解FlinkKafkaSource的容错性(影响消费起始位置)

如果Flink启用了检查点,Flink Kafka Consumer将会周期性的checkpoint其Kafka偏移量到快照。
通过实现CheckpointedFunction。
ListState
保证仅一次消费。
如果作业失败,Flink将流程序恢复到最新检查点的状态,并从检查点中存储的偏移量开始重新消费Kafka中的记录。(此时前面所讲的消费策略就不能决定消费起始位置了,因为出故障了)。
1.12 Flink Kafka Consumer Offset提交行为
Flink Kafka Consumer Offset提交行为分为以下两种:

1.13不同情况下消费起始位置的分析

1.14动态Partition discovery
Flink Kafka Consumer支持动态发现Kafka分区,且能保证exactly-once。
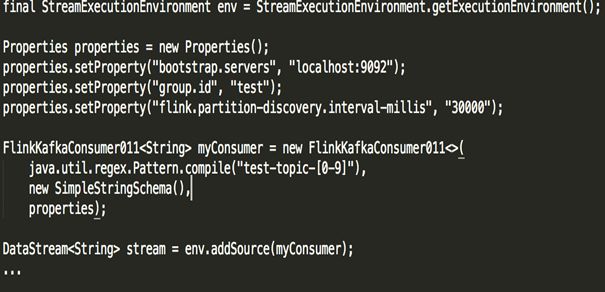
默认禁止动态发现分区,把flink.partition-discovery.interval-millis设置大于0即可启用:
properties.setProperty(“flink.partition-discovery.interval-millis”, “30000”)
1.15动态Topic discovery
Flink Kafka Consumer支持动态发现Kafka Topic,仅限通过正则表达式指定topic的方式。
默认禁止动态发现分区,把flink.partition-discovery.interval-millis设置大于0即可启用。
2. FlinkKafkaProducer(kafka sink)
2.1 Flink KafkaProducer
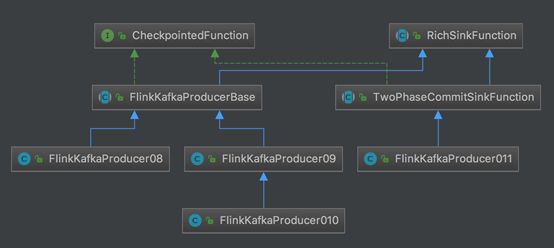
FlinkKafkaProducerBase实现CheckpointFunction接口实现容错,同时也继承了RichSinkFunction类。FinkKafkaProducer08继承FlinkKafkaProducerBase。FinkKafkaProducer09继承FlinkKafkaProducerBase,FinkKafkaProducer10继承FinkKafkaProducer09.
FinkKafkaProducer011已经支持事务,它继承TowPhaseCommitSinkFunction。TowPhaseCommitSinkFunction继承RichSinkFunction。
2.2FlinkKafkaProducer
FlinkKafkaProducer包含了如下不同的构造方法:
FlinkKafkaProducer010(String brokerList, String topicId, SerializationSchema
FlinkKafkaProducer010(String topicId, SerializationSchema
FlinkKafkaProducer010(String brokerList, String topicId, KeyedSerializationSchema
FlinkKafkaProducer010(String topicId, KeyedSerializationSchema
FlinkKafkaProducer010(String topicId,SerializationSchema
FlinkKafkaProducer010(String topicId,KeyedSerializationSchema
Value序列化接口SerializationSchema,如果实现这个接口就需要实现如下方法:
byte[] serialize(T element);
如果key也需要实现序列化,则需要实现序列化接口KeyedSerializationSchema,然后重新如下方法:
byte[] serializeKey(T element);
byte[] serializeValue(T element);
String getTargetTopic(T element)
2.3常见序列化Schema
常见的序列化Schema:
1.TypeInformationSerializationSchema/ TypeInformationKeyValueSerializationSchema(适合读写均是flink的场景)
2.SimpleStringSchema
2.4 producerConfig
FlinkKafkaProducer内部KafkaProducer的配置,具体配置可以参考官网地址:
https://kafka.apache.org/documentation.html
2.5 FlinkKafkaPartitioner
默认使用FlinkFixedPartitioner,即每个subtask的数据写到同一个Kafka partition中。
自定义分区器:继承FlinkKafkaPartitioner(partitioner的状态在job失败时会丢失,不会checkpoint)。
2.6 FlinkKafkaProducer容错

