目录
1、Spark UI
2、Spark History UI
3、REST API
工作中需要监控Spark作业的运行情况,发现问题,来进行调优。
Monitoring and Instrumentation
监控指标:
1)Launtime 启动时间
2)Duration 持续时间
3)GC Time 垃圾收集时间
4)Shuffle Read Size/Record等

![]()
监控Spark 应用程序的有三种方式:
1)Spark UI
2)Spark History UI
3)REST API
1、Spark UI
地址:http://hadoop001:4040
Spark UI界面标签:
1)Jobs:提交的job、stage信息、DAG图等。
2)Stages:stage信息、task信息。
3)Storage:数据存储进内存的信息。
4)Environment:环境、配置、jar等信息。
5)Executors:executors 、driver相关信息。

![]()
问题:
1)如果在同一个机器上运行了多个sc,Spark UI端口是依次递增的:4040、4041、4042....
2)确定:Spark程序运行结束之后就不能再看这个UI了,因为生命周期结束了,所以应该启动Spark History服务。
2、Spark History UI
需要将Spark的操作记录下来,即开启 spark.eventLog.enabled=true参数。
并且要设置Spark History可以共享Spark的操作日志,这样Spark History服务就可以构建应用程序的UI了。
操作步骤:
1)创建日志写入路径
hadoop fs -mkdir -p hdfs://hadoop001:9000/directory
2)配置spark-default.conf
cd $SPARk-HOME/conf
cp spark-default.conf.temlate spark-default.conf
vi spark-default.conf
spark.eventLog.enabled true spark开启将操作日志记录下来的功能
spark.eventLog.dir hdfs://hadoop001:9000/directory spark操作记录日志的位置(与History读的一样)
spark.eventLog.compress true
spark.history.fs.logDirectory hdfs://hadoop001:9000/directory History读取的日志的位置也可以开启压缩(默认使用lz4压缩,压缩的块大小默认是32k,建议设置成320K以上):
//spark.eventLog.compress true
//spark.io.compression.codec lz4
//spark.io.compression.lz4.blockSize 32k
3)配置spark-env.sh
cd $SPARK-HOME/conf
cp spark-env.sh.temlate spark-env.sh
vi spark-env.sh
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://hadoop001:9000/directory -Dspark.history.retainedApplications=15"也可以配置打开日志自动清理功能
//-Dspark.history.fs.cleaner.enabled=true
也可以设置在History Server显示的Application历史记录个数,超过这个值,旧的job信息将被删除
//spark.history.retainedApplications4)启动Spark History服务:
cd /home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0/sbin
[hadoop@hadoop001 sbin]$ ./start-history-server.sh5)对应的Spark History UI界面:http://hadoop001:18080
默认情况下,列出未完成和已完成的应用程序。Show completed applications、Show incomplete applications。6)日志文件的位置:$SPARK_HOME/log
Spark History出现异常的时候可以去查看日志文件。7)Spark History服务启动成功之后,对应HistoryServer进程,然后就可以去启动Spark作业了,这样Spark作业停止之后,也可以再Spark History UI查看到作业的信息。
8)去HDFS路径的日志目录下查看:/directory/application_1564065468412_0001,里面的文件对应的就是每个Spark作业的应用ID,文件内容是json格式的,所以要知道本质:Spark History、rest api等读取的就是这里的json数据。
9)停止Spark History服务:./sbin/stop-history-server.sh
更多Spark History配置信息(spark-default.conf文件参考):
Spark History Server Configuration Options
# spark.history.fs.logDirectory file:/tmp/spark-events 默认读取日志的位置
# spark.history.fs.update.interval 10s 默认刷新时间是10秒
# spark.history.ui.port 18080 默认的WebUI端口
# spark.history.fs.cleaner.enabled false 是不是自动清理日志的开关
# spark.history.fs.cleaner.interval 1d 自动清理的周期
# spark.history.fs.cleaner.maxAge 7d 自动清理保存的最大历史
# spark.history.retainedApplications 50
# 缓存中保留数据的应用的数量
# 如果数量超限,最老的应用会被LRU
# 如果访问一个不在缓存中的应用,则会从磁盘加载该应用信息到缓存
配置Spark History的定期清理:
1)在Spark-default.xml中配置:
## yarn日志收集
yarn.log-aggregation.retain-seconds = 1209600
yarn.log-aggregation.retain-check-interval-seconds = 86400## spark-history日志(本人使用的是Spark)
spark.history.fs.cleaner.enabled = true
spark.history.fs.cleaner.interval = 1d
spark.history.fs.cleaner.maxAge = 14d
## spark2-history日志
spark.history.fs.cleaner.enabled = true
spark.history.fs.cleaner.interval = 1d
spark.history.fs.cleaner.maxAge = 14d2)在spark-env.xml中配置:
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs:///spark_eventLog -Dspark.history.fs.cleaner.enabled=true"
3、REST API
REST API
有非常多的Endpoint可以选择:
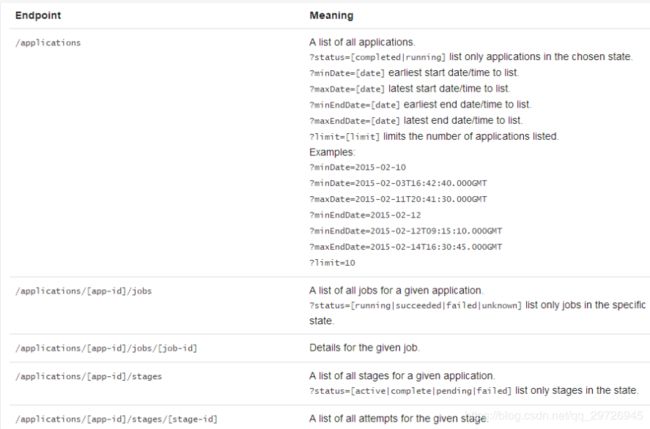
![]()
比如:
hadoop000:18080/api/v1/applications?status=completed 已经完成的job
hadoop000:18080/api/v1/applications?status=running 正在运行的job
hadoop000:18080/api/v1/applications/application-id/jobs 查看一个应用下的所有job
hadoop000:18080/api/v1/applications/application-id/jobs/job-id 具体一个应用下一个job信息
hadoop000:18080/api/v1/applications/application-id/stages 一个应用下所有的stage
读取到的是json的内容,本质是读取的HDFS上作业的json记录。
可以自己定制化界面,类似于Spark History UI的形式。