celery的简介
celery是一个基于分布式消息传输的异步任务队列,它专注于实时处理,同时也支持任务调度。它的执行单元为任务(task),利用多线程,如Eventlet,gevent等,它们能被并发地执行在单个或多个职程服务器(worker servers)上。任务能异步执行(后台运行)或同步执行(等待任务完成)。
在生产系统中,celery能够一天处理上百万的任务。它的完整架构图如下:
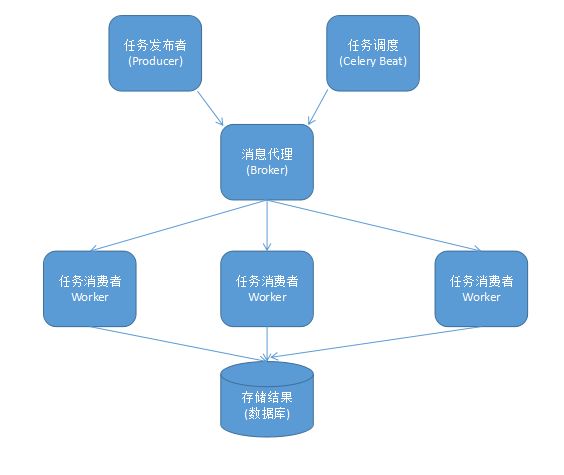
组件介绍:
- Producer:调用了Celery提供的API、函数或者装饰器而产生任务并交给任务队列处理的都是任务生产者。
- Celery Beat:任务调度器,Beat进程会读取配置文件的内容,周期性地将配置中到期需要执行的任务发送给任务队列。
- Broker:消息代理,又称消息中间件,接受任务生产者发送过来的任务消息,存进队列再按序分发给任务消费方(通常是消息队列或者数据库)。Celery目前支持RabbitMQ、Redis、MongoDB、Beanstalk、SQLAlchemy、Zookeeper等作为消息代理,但适用于生产环境的只有RabbitMQ和Redis, 官方推荐 RabbitMQ。
- Celery Worker:执行任务的消费者,通常会在多台服务器运行多个消费者来提高执行效率。
- Result Backend:任务处理完后保存状态信息和结果,以供查询。Celery默认已支持Redis、RabbitMQ、MongoDB、Django ORM、SQLAlchemy等方式。
在客户端和消费者之间传输数据需要序列化和反序列化。 Celery 支出的序列化方案如下所示:

准备工作
在本文中,我们使用的celery的消息代理和后端存储数据库都使用redis,序列化和反序列化选择msgpack。
首先,我们需要安装redis数据库,具体的安装方法可参考:http://www.runoob.com/redis/redis-install.html 。启动redis,我们会看到如下界面:
在redis可视化软件rdm中,我们看到的数据库如下:
里面没有任何数据。
接着,为了能够在python中使用celery,我们需要安装以下模块:
- celery
- redis
- msgpack
这样,我们的准备工作就完毕了。
一个简单的例子
我们创建的工程名称为proj,结构如下图:
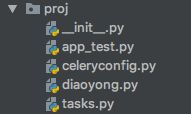
首先是主程序app_test.py,代码如下:
from celery import Celery
app = Celery('proj', include=['proj.tasks'])
app.config_from_object('proj.celeryconfig')
if __name__ == '__main__':
app.start()分析一下这个程序:
- "from celery import Celery"是导入celery中的Celery类。
- app是Celery类的实例,创建的时候添加了proj.tasks这个模块,也就是包含了proj/tasks.py这个文件。
- 把Celery配置存放进proj/celeryconfig.py文件,使用app.config_from_object加载配置。
接着是任务函数文件tasks.py,代码如下:
import time
from proj.app_test import app
@app.task
def add(x, y):
time.sleep(1)
return x + ytasks.py只有一个任务函数add,让它生效的最直接的方法就是添加app.task这个装饰器。add的功能是先休眠一秒,然后返回两个数的和。
接着是配置文件celeryconfig.py,代码如下:
BROKER_URL = 'redis://localhost' # 使用Redis作为消息代理
CELERY_RESULT_BACKEND = 'redis://localhost:6379/0' # 把任务结果存在了Redis
CELERY_TASK_SERIALIZER = 'msgpack' # 任务序列化和反序列化使用msgpack方案
CELERY_RESULT_SERIALIZER = 'json' # 读取任务结果一般性能要求不高,所以使用了可读性更好的JSON
CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24 # 任务过期时间
CELERY_ACCEPT_CONTENT = ['json', 'msgpack'] # 指定接受的内容类型最后是调用文件diaoyong.py,代码如下:
from proj.tasks import add
import time
t1 = time.time()
r1 = add.delay(1, 2)
r2 = add.delay(2, 4)
r3 = add.delay(3, 6)
r4 = add.delay(4, 8)
r5 = add.delay(5, 10)
r_list = [r1, r2, r3, r4, r5]
for r in r_list:
while not r.ready():
pass
print(r.result)
t2 = time.time()
print('共耗时:%s' % str(t2-t1))在这个程序中,我们调用了add函数五次,delay()用来调用任务。
例子的运行
到此为止,我们已经理解了整个项目的结构与代码。
接下来,我们尝试着把这个项目运行起来。
首先,我们需要启动redis。接着,切换至proj项目所在目录,并运行命令:
celery -A proj.app_test worker -l info界面如下:
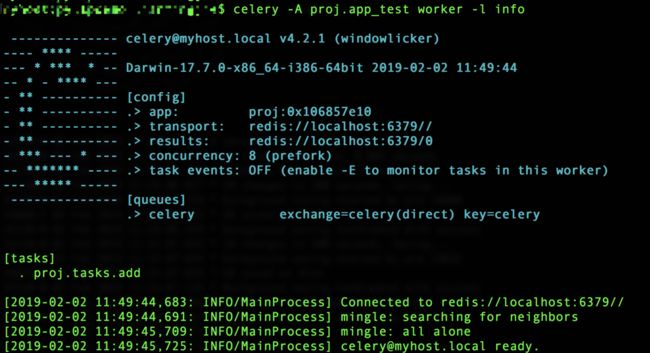
然后,我们运行diaoyong.py,输出的结果如下:
3
6
9
12
15
共耗时:1.1370790004730225后台输出如下:
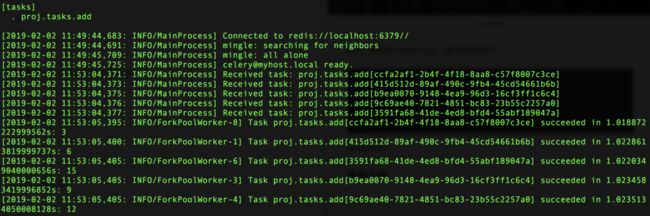
接着,我们看一下rdm中的数据:
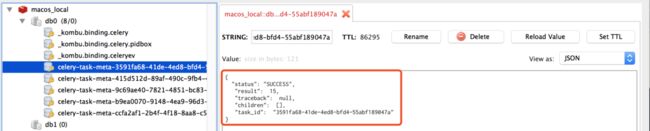
至此,我们已经成功运行了这个项目。
下面,我们尝试着对这个运行结果做些分析。首先,我们一次性调用了五次add函数,但是运行的总时间才1秒多。这是celery异步运行的结果,如果是同步运行,那么,至少需要5秒多,因为每调用add函数一次,就会休眠一秒。这就是celery的强大之处。
从后台输出可以看到,程序会先将任务分发出来,每个任务一个ID,在后台统一处理,处理完后会有相应的结果返回,同时该结果也会储存之后台数据库。可以利用ready()判断任务是否执行完毕,再用result获取任务的结果。
本文项目的github地址为:https://github.com/percent4/celery_example 。
本次分享到此结束,感谢阅读~
注意:本人现已开通微信公众号: Python爬虫与算法(微信号为:easy_web_scrape), 欢迎大家关注哦~~
参考文献
- Celery 初步:http://docs.jinkan.org/docs/celery/getting-started/first-steps-with-celery.html#first-steps
- 使用Celery:https://zhuanlan.zhihu.com/p/22304455
- 异步神器celery:https://www.jianshu.com/p/9be4d8d30d8e