1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
学习笔记:
通过学习老师推荐的中国大学慕课的北京理工大学嵩天老师的《Python网络爬虫与信息提取》课程,让我对把爬虫运用到生活中更加的了解。
作为专门为网络爬虫的讲解课程,嵩天老师讲解得十分详细。在学习理论知识的前提下结合实操是最有效的学习方法。
第0周:老师讲解了python语言和所应用到的开发工具,提及到了几个常用的库。例如requests,BeautifulSoup等。
第1周:讲解的是网络爬虫之规则,针对Requests库入门,并一步一步带领大家做了有关后面Requests库网络爬虫的个实战实例,使我对Requests库有了一些深刻的了解和掌握,熟知了requests库7个主要方法有:
1.requests.request() 构造一个请求,支撑以下各方法的基础方法
2.requests.get() 获取HTML网页的主要方法,对应于HTTP的GET
3.requests.head() 获取HTML网页头信息的方法,对应于HTTP的HEAD
4.requests.post() 向HTML网页提交POST请求的方法,对应于HTTP的POST
5.requests.put() 向HTML网页提交PUT请求的方法,对应于HTTP的PUT
6.requests.patch() 向HTML网页提交局部修改请求,对应于HTTP的PATCH
7.requests.delete() 向HTML页面提交删除请求,对应于HTTP的DELETE 。
同时老师讲解了进行网络爬虫需要遵守的一些规则,以及不规范使用网络爬虫所会造成的不良影响。

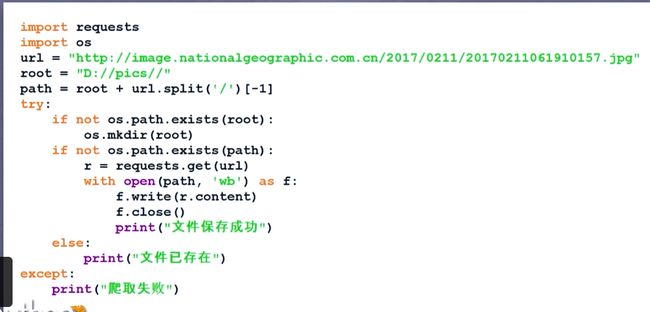
第2周:介绍的是网络爬虫之提取,详细介绍了Beautiful Soup,信息组织和提取方法以及介绍了中国大学排名爬虫的实例。
Beautiful Soup库,也叫bs4,它的四种解析器有:bs4的HTML解析器、lxml的HTML解析器、lxml的XML解析器、html5lib的解析器。
BeautifulSoup类5种基本元素:
1.Tag 标签,最基本的信息组织单元,分别用<>和标明开头和结尾
2.Name 标签的名字,
…
的名字是’p’,格式: 3.Attributes 标签的属性,字典形式组织,格式:
4.NavigableString 标签内非属性字符串,<>…中字符串,格式:
5.Comment 标签内字符串的注释部分,一种特殊的Comment类型,都分别对这些解析器和基本元素进行了更深层次的介绍讲解和举例子,还有介绍了信息标记的三种形式:xml、json、yaml等。
第3周:介绍的是网络爬虫之实战,介绍了正则表达式语法由字符和操作符构成和re库主要功能函数,了解了经典正则表达式有:
(1)^[A‐Za‐z]+由26个字母组成的字符串[A‐Za‐z0‐9]+由26个字母组成的字符串[A‐Za‐z0‐9]+ 由26个字母和数字组成的字符串
(2)^‐?\d+整数形式的字符串[0‐9]∗[1‐9][0‐9]∗整数形式的字符串[0‐9]∗[1‐9][0‐9]∗ 正整数形式的字符串
(3)[1‐9]\d{5} 中国境内邮政编码,6位等这些正则表达式,还通过淘宝商品比价定向爬虫和股票数据定向爬虫两个实例的举例讲解,对这周讲解的内容有了更深层次的理解。
第4周:是最后一周,它讲解的是网络爬虫之框架,Scrapy爬虫框架。Scrapy是一个快速功能强大的网络爬虫框架,爬虫框架是实现爬虫功能的一个软件结构和功能组件集合,爬虫框架是一个半成品,能够帮助用户实现专业网络爬虫。
常用命令有:
1.startproject 创建一个新工程scrapy startproject
2.genspider 创建一个爬虫scrapy genspider [options]
3.settings 获得爬虫配置信息scrapy settings [options]
4.crawl 运行一个爬虫scrapy crawl
5.list 列出工程中所有爬虫scrapy list
6.shell 启动URL调试命令行scrapy shell [url]。
还讲解了它的基本使用,demo.py的一整个过程,以及yield 生成器解释,最后还讲解了股票数据爬虫Scrapy的实例。
上完嵩天老师的课,高效的上课方式,以及能够实时实现自己所学知识的一点点成就感,提起了对python及其他知识自学的兴趣。