1.注册中国大学MOOC
2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
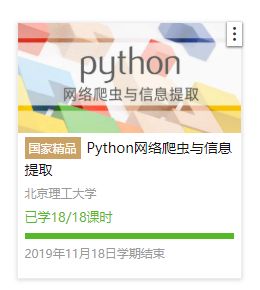
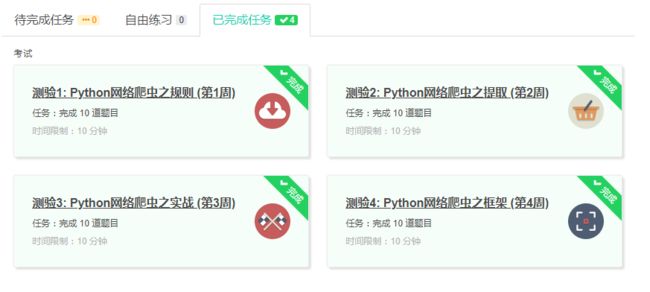
4.提供图片或网站显示的学习进度,证明学习的过程。
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
经过这两周对嵩天老师的《Python网络爬虫及信息提取》的学习,让我了解到python第三方库的强大,以及对网络爬虫前所未有的了解。让我对python有了更深层次的了解。
学完前面四周的课程,嵩天老师的《Python网络爬虫及信息提取》主要通过Requests、robots.txt、BeautifulSoup、Re、Scrapy和对这些库的应用进行讲解
一、Requests库:自动爬取HTML页面与自动网络请求提交。
首先我们学习了如何安装Requests库,在win平台,“以管理员身份运行”cmd,执行 pip install requests,以及Requests库的7个主要方法:request、get、head、post、put、 patch、delete的使用,Requests库的2个重要对象:Request、Response、Response对 象包含爬虫返回的内容的了解及使用。
二、robots.txt:网络爬虫排除标准
在嵩天老师的带领下我们对robots.txt网络爬虫排除标准进行了了解,最主要的是 Robots协议,它的作用是:网站告知网络爬虫哪些页面可以抓取,哪些不行。形式是 在网站根目录下的robots.txt文件,以及Robots协议的使用。网络爬虫“盗亦有道”。
三、BeautifulSoup库:解析HTML页面
首先我们对BeautifulSoup库进行了安装,win平台“以管理员身份运行”cmd执行pip install beautifulsoup4。对BeautifulSoup进行了了解,是解析、遍历、维护“标签数”的功能库,对BeautifulSoup的5个基本元素(Tag、Name、Attributes,NavigableString、comment)及3种遍历功能(下行遍历、上行遍历、平行遍历)进行了了解及使用。基于bs4库的HTML格式输出,使用prettify()方法,为HTML文本<>及其内容增加”\n”并且可用于标签/方法。让我了解到了XML、JSON、YAML的区别:XML可扩展性好,但繁琐;JSON适合程序处理,较XML简洁,有类型的键值对;YAML文本信息比例较高,可读 性好,无类型的键值对;对解析器的优缺点进行了了解:需要标记解析器:优点是解析 准确,缺点是提取繁琐且慢;无视标记形式:优点提取速度快,缺点准确性与信息内容 相关
四、Re库:正则表达式详解提取页面关键信息
在嵩天老师的带领下我们对Re库进行了了解,正则表达式是用来简洁表达一组字符串的表达式,正则表达式是一种通用的字符串表达框架,正则表达式的表示类型为raw string类型(原生字符串类型),对Re库的主要功能函数(search、match、findall、split、finditer、sub)进行了了解及使用,Re库的函数式用法为一次性操作,还有一种为面向对象用法,可在编译后多次操作,通过compile生成的regex对象才能叫做正则表达式。
五、Scrapy库:网络爬虫原理介绍,专业爬虫框架介绍
Scrapy是一个快速功能强大的网络爬虫框架,安装:win平台“以管理员身份运行”cmd执行pip install scrapy。和requests库比较起来,Scripy框架网站级爬虫、并发性好、性能较高、重点在于爬虫结构、一般定制灵活,深度定制困难,入门难。非常小的需求,request库;不太小的需求,scrapy框架
通过嵩天老师的理论与实战相结合的方法,让我对《Python网络爬虫及信息提取》有了更深层次的理解,让我印象最深的是正则表达式,理论和实战结合,让我更快的记住了正则表达式的知识点。通过《Python网络爬虫及信息提取》的学习,让我发现了我所知道的东西还只是冰山一角,希望在接下来的时间内,能够更进一步