1.注册中国大学MOOC

2.选择北京理工大学嵩天老师的《Python网络爬虫与信息提取》MOOC课程
3.学习完成第0周至第4周的课程内容,并完成各周作业
4.提供图片或网站显示的学习进度,证明学习的过程。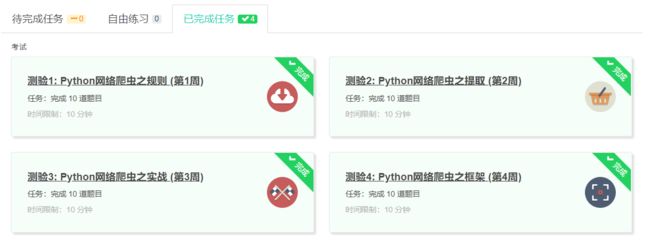
5.写一篇不少于1000字的学习笔记,谈一下学习的体会和收获。
这几天在慕课自学,我从中学到了很多。有一部分是以前学过的基础,但更多的是以前没有接触过的新知识。
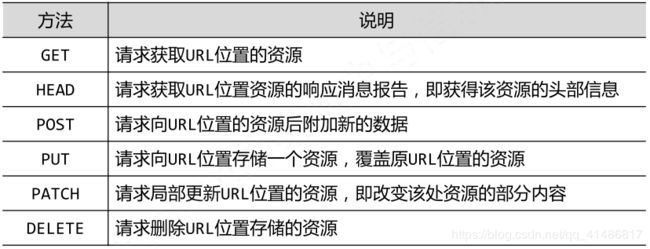
在第一周的学习中,我知道了Requests库的7个主要方法:
方法 说明
requests.request( ) 构造一个请求,支撑以下各方法的基础方法
requests.get( ) 获取HTML网页的主要方法,对应于HTTP的GET
requests.head( ) 获取HTML网页头信息的方法,对应于HTTP的HEAD
requests.post( ) 向HTML页面提交POST请求的方法,对应于HTTP的POST
requests.put( ) 向HTML页面提交PUT请求的方法,对应于HTTP的PUT
requests.patch( ) 向HTML页面提交局部修改请求,对应于HTTP的PATCH
requests.delete( ) 向HTML页面提交删除请求,对应于HTTP的DELETE
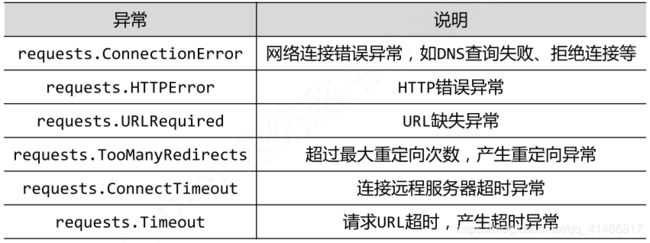
并知道了Requests库的异常与其代表的含义
Requests库的异常
![]()
知道了简单的爬取网页的通用代码框架

复习了HTTP协议与其中的方法
HTTP:超文本传输协议
HTTP URL的理解:URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源
HTTP协议对资源的操作
在第二周,我学习了一个新的库: Beautiful Soup库。Beautiful Soup库是解析、遍历、维护“标签树”的功能库,他的引用方法为from bs4 import BeautifulSoup
知道了基于bs4库的HTML内容遍历方法有三种:
标签树的下行遍历

标签树的上行遍历

标签树的平行遍历(平行遍历发生在同一个父节点下的各节点间)
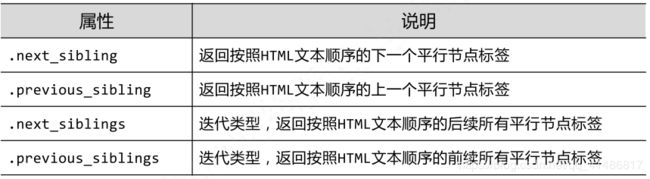
知道了信息提取的两种方法:
方法一:完整解析信息的标记形式,再提取关键信息
XML JSON YAML 需要标记解析器,例如:bs4库的标签树遍历
优点:信息解析准确 缺点:提取过程繁琐,速度慢
方法二:无视标记形式,直接搜索关键信息 搜索
对信息的文本查找函数即可
优点:提取过程简洁,速度较快 缺点:提取结果准确性与信息内容相关
第三周学习了正则表达式re库,re库是python的标准库,正则表达式是用来简洁表达一组字符串的表达式。它使用一组特定的操作符来表示英文,数字,特殊符号还有取值范围等的约束条件。对于一些生活中常用到的字符串如邮编,手机号,IP地址等,可以使用正则表达式来匹配这些特定的字符串。re库采用raw string类型表示正则表达式,表示形式为:r'text'。当一个正则表达式有多种匹配形式时,Re库默认采用贪婪匹配,即输出匹配最长的子串。如果我们想要输出最短的子串,那么就需要用到最小匹配操作符来达到我们想要的结果。其中老师用了淘宝商品比价定向爬虫和股票数据定向爬虫两个实例来让我们更好的学习。
第四周,学习了Scrapy的安装及Scrapy爬虫框架的介绍和解析,“5+2”结构的目的和功能,及requests库和Scrapy爬虫的比较和Scrapy爬虫的常用命令。Scrapy命令行的格式和逻辑。老师还介绍了Scrapy爬虫的第一个实例,yield关键字的使用和Scrapy爬虫的基本使用:使用步骤,数据类型,提取信息的方法,CSS Selector的基本使用。老师还详细讲解了实例:股票数据Scrapy爬虫,功能、框架、实例的编写步骤、执行和优化。
通过学习嵩天老师的课程,使我对python的网络爬虫知识了解更多了,明白了Requests、Beautiful Soup、Re库的相关知识及使用,Scrapy框架的原理和解析及基本使用,老师通过讲解各种实例,让我们对知识点更加明白和理解。