工作中,正则表达式用的可能不是很多,一般使用的时候网上都有现成的实例,很少缺乏比较全面的理解。本文主要以匹配HTML标签为例,简述下正则表达式常用的功能点。匹配HTML片段如下:
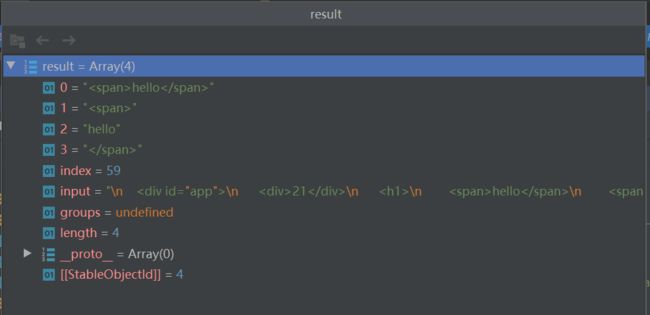
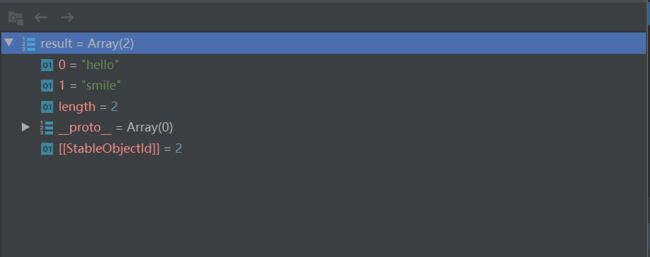
let str = ``;21hello smile
正则匹配本文查看结果主要用String.match(RegExp)方法,常用的正则匹配方法为:RegExp.test(String),RegExp.exec(String)
1、正则表达式的声明
正则表达式的声明方式和普通变量的声明方式类似,一般情况下有两种,字面量和正则构造方法RegExp。以匹配span标签为例,匹配单个span标签的正则如下:
// 字面量方式 let normalPattern = /span/ // 调用正则构造方法 let pattern = new RegExp('span')
2. 修饰符
上述的正则,在匹配测试文本是,输出的结果是一个数组,只有一个元素span,如果我想匹配多个呢,这里就要引入正则修饰符的概念了,常用的就是 i 和 g。
i的含义是忽略大小写,比如用/span/只能去匹配span字符串,SPAN匹配不了,如果想匹配SPAN,就要加上i修饰符
g的含义是global,全局查找,正则默认只匹配第一个符合条件的值,如果要全局匹配,就要加上g修饰符。
具体写法如下:
// 字面量方式 let normalPattern = /span/ig // 调用正则构造方法 let pattern = new RegExp('span', 'ig')
3.字符类别
以上匹配的文本都非常的基础,假如我想匹配所有的HTML标签,该怎么写呢?HTML标签很多,没法一个个全部罗列出来,我们可以使用字符类别,进行快速的匹配。参考列表如下:

字符类别,在某种程度上来说,可以理解为一个字符集,如上述列表所示,\d是数字0-9的集合,如果我们要匹配一段文本中所有的数字,可以直接声明如下正则:
let numberPattern = /\d/g
假如我要匹配所有的HTML标签呢?在匹配一个文本之前,我们需要先分析下HTML标签规律,首先,HTML标签和一般的XML标签,都是以尖括号<大头,以尖括号>结尾,其次,中间只能是英文字母或者数字,最后,数字或字母可能出现一次或者多次。写正则的第一要素是先归纳总结,总结出规律才能去分析正则的写法。正则表达式本质上也是一种规律的解释文本。从我们总结的规律中,我们可以按照如下写法:
let matchTags = /<\w+>/g
匹配结果如下:
[ '', '', '', '', '
\w代表数字或者字母,+代表匹配一次或者多次,g代表全局匹配。我们在匹配文本的时候,一种规律有时候不可能只用一次,正则表达式提供了丰富的数量词语法,能够满足我们绝大多数要求,下面的章节会有介绍。
我们看到,我们匹配的HTML标签只是前面的标签,并没有后面的闭合标签,我们如何匹配闭合标签呢?闭合标签比普通的标签多了一个斜杠/,如果我们单纯的写/,是不可以的,大家可能意识到,正则表达式的字面量写法是两个斜杠/包起来的,如果我们直接写,会有冲突,这时候,我们需要借助转义字符反斜杠\进行转义即可,一些与正则表达式冲突的,都需要用转义字符进行转义,比如特殊字符(),[],还有是一些具有特殊意义的集合,\w,\d....
匹配闭合标签的正则如下:
let matchCloseTags = /<\/\w+>/g匹配结果:
', '', '', '', '', '[ '