1 Geatpy库的由来
由华南农业大学、暨南大学、华南理工大学等一批大佬们研发的超高性能、通用性强、能够轻松应用到实际工程项目之中的、能让用户快速上手进化算法的工具箱(遗传算法工具箱),详情见官网http://geatpy.com/index.php/home/。
2 Geatpy库的用途
Geatpy 是一个高性能实用型进化算法工具箱,提供了许多已实现的进化算法各项操作的函数,如初始化种群、选择、交叉、变异、多目标优化参考点生成、非支配排序、多目标优化 GD、IGD、HV 等指标的计算等等。
3 Geatpy库的案例
3.1 带约束的单目标优化问题
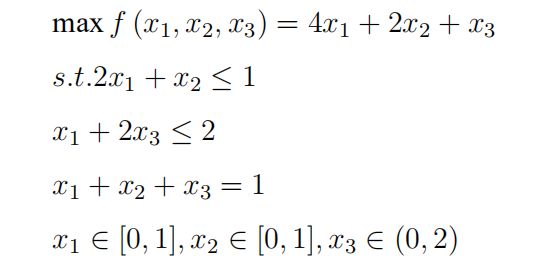
带约束的单目标优化问题
3.1.1 Python程序
问题描述程序
import numpy as np
import geatpy as ea
class MyProblem(ea.Problem): # 继承Problem父类
def __init__(self):
name = 'MyProblem' # 初始化name(函数名称,可以随意设置)
M = 1 # 初始化M(目标维数)
maxormins = [-1] # 初始化目标最小最大化标记列表,1:min;-1:max
Dim = 3 # 初始化Dim(决策变量维数)
varTypes = [0] * Dim # 初始化决策变量类型,0:连续;1:离散
lb = [0,0,0] # 决策变量下界
ub = [1,1,2] # 决策变量上界
lbin = [1,1,0] # 决策变量下边界
ubin = [1,1,0] # 决策变量上边界 # 调用父类构造方法完成实例化
ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)
def aimFunc(self, pop): # 目标函数,pop为传入的种群对象
Vars = pop.Phen # 得到决策变量矩阵
x1 = Vars[:, [0]] # 取出第一列得到所有个体的x1组成的列向量
x2 = Vars[:, [1]] # 取出第二列得到所有个体的x2组成的列向量
x3 = Vars[:, [2]] # 取出第三列得到所有个体的x3组成的列向量
# 计算目标函数值,赋值给pop种群对象的ObjV属性
pop.ObjV = 4*x1 + 2*x2 + x3
# 采用可行性法则处理约束,生成种群个体违反约束程度矩阵
pop.CV = np.hstack([2*x1 + x2 - 1, x1 + 2*x3 - 2, np.abs(x1 + x2 + x3 - 1)]) # 第1.2.3个约束
主程序
import numpy as np
import geatpy as ea
from MyProblem import MyProblem
"""============================实例化问题对象========================"""
problem = MyProblem() # 实例化问题对象
"""==============================种群设置==========================="""
Encoding = 'RI' # 编码方式
NIND = 50 # 种群规模
Field = ea.crtfld(Encoding, problem.varTypes, problem.ranges, problem.borders) # 创建区域描述器
population = ea.Population(Encoding, Field, NIND) # 实例化种群对象(此时种群还没被真正初始化,仅仅是生成一个种群对象)
"""===========================算法参数设置=========================="""
myAlgorithm = ea.soea_DE_best_1_L_templet(problem, population) # 实例化一个算法模板对象
myAlgorithm.MAXGEN = 1000 # 最大遗传代数
myAlgorithm.mutOper.F = 0.5 # 设置差分进化的变异缩放因子
myAlgorithm.recOper.XOVR = 0.5 # 设置交叉概率
myAlgorithm.drawing = 1 # 设置绘图方式
"""=====================调用算法模板进行种群进化====================="""
[population, obj_trace, var_trace] = myAlgorithm.run() # 执行算法模板 # 输出结果
best_gen = np.argmax(obj_trace[:, 1]) # 记录最优种群是在哪一代
best_ObjV = obj_trace[best_gen, 1]
print('最优的目标函数值为:%s'%(best_ObjV))
print('最优的决策变量值为:')
for i in range(var_trace.shape[1]):
print(var_trace[best_gen, i])
print('有效进化代数:%s'%(obj_trace.shape[0]))
print('最优的一代是第 %s 代'%(best_gen + 1))
print('评价次数:%s'%(myAlgorithm.evalsNum))
print('时间已过 %s 秒'%(myAlgorithm.passTime))
3.2 带约束的多目标优化问题

带约束的多目标优化问题
3.2.1 Python程序
问题描述程序
import numpy as np
import geatpy as ea
class MyProblem(ea.Problem): # 继承Problem父类
def __init__(self):
name = 'BNH' # 初始化name(函数名称,可以随意设置)
M = 2 # 初始化M(目标维数)
maxormins = [1] * M # 初始化maxormins
Dim = 2 # 初始化Dim(决策变量维数)
varTypes = [0] * Dim # 初始化varTypes(决策变量的类型,0:实数;1:整数)
lb = [0] * Dim # 决策变量下界
ub = [5, 3] # 决策变量上界
lbin = [1] * Dim # 决策变量下边界
ubin = [1] * Dim # 决策变量上边界
# 调用父类构造方法完成实例化
ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)
def aimFunc(self, pop): # 目标函数
Vars = pop.Phen # 得到决策变量矩阵
x1 = Vars[:, [0]]
x2 = Vars[:, [1]]
f1 = 4*x1**2 + 4*x2**2
f2 = (x1 - 5)**2 + (x2 - 5)**2
# 采用可行性法则处理约束
pop.CV = np.hstack([(x1 - 5)**2 + x2**2 - 25, -(x1 - 8)**2 - (x2 - 3)**2 + 7.7])
# 把求得的目标函数值赋值给种群pop的ObjV
pop.ObjV = np.hstack([f1, f2])
def calBest(self): # 计算全局最优解
N = 10000 # 欲得到10000个真实前沿点
x1 = np.linspace(0, 5, N)
x2 = x1.copy()
x2[x1 >= 3] = 3
return np.vstack((4 * x1**2 + 4 * x2**2, (x1 - 5)**2 + (x2 - 5)**2)).T
主程序
import geatpy as ea # import geatpy
from MyProblem import MyProblem # 导入自定义问题接口
"""=========================实例化问题对象==========================="""
problem = MyProblem() # 实例化问题对象
"""===========================种群设置=============================="""
Encoding = 'RI' # 编码方式
NIND = 100 # 种群规模
Field = ea.crtfld(Encoding, problem.varTypes, problem.ranges, problem.borders) # 创建区域描述器
population = ea.Population(Encoding, Field, NIND) # 实例化种群对象(此时种群还没被真正初始化,仅仅是生成一个种群对象)
"""=========================算法参数设置============================"""
myAlgorithm = ea.moea_NSGA2_templet(problem, population) # 实例化一个算法模板对象
myAlgorithm.MAXGEN = 200 # 最大遗传代数
myAlgorithm.drawing = 1 # 设置绘图方式
"""===================调用算法模板进行种群进化=======================
调用run执行算法模板,得到帕累托最优解集NDSet。
NDSet是一个种群类Population的对象。
NDSet.ObjV为最优解个体的目标函数值;NDSet.Phen为对应的决策变量值。
详见Population.py中关于种群类的定义。
"""
NDSet = myAlgorithm.run() # 执行算法模板,得到非支配种群
NDSet.save() # 把结果保存到文件中 # 输出
print('用时:%f 秒'%(myAlgorithm.passTime))
print('评价次数:%d 次'%(myAlgorithm.evalsNum))
print('非支配个体数:%d 个'%(NDSet.sizes))
print('单位时间找到帕累托前沿点个数:%d 个'%(int(NDSet.sizes // myAlgorithm.passTime)))
# 计算指标
PF = problem.getBest() # 获取真实前沿
if PF is not None and NDSet.sizes != 0:
GD = ea.indicator.GD(NDSet.ObjV, PF) # 计算GD指标
IGD = ea.indicator.IGD(NDSet.ObjV, PF) # 计算IGD指标
HV = ea.indicator.HV(NDSet.ObjV, PF) # 计算HV指标
Spacing = ea.indicator.Spacing(NDSet.ObjV) # 计算Spacing指标
print('GD: %f'%GD)
print('IGD: %f'%IGD)
print('HV: %f'%HV)
print('Spacing: %f'%Spacing)
"""=====================进化过程指标追踪分析========================"""
if PF is not None:
metricName = [['IGD'], ['HV']]
[NDSet_trace, Metrics] = ea.indicator.moea_tracking(myAlgorithm.pop_trace, PF, metricName, problem.maxormins)
# 绘制指标追踪分析图
ea.trcplot(Metrics, labels = metricName, titles=metricName)
4 参考
本文为学习笔记,参考网站为Geatpy官网,网址如下。
首页:http://geatpy.com/index.php/home/
文档:http://geatpy.com/index.php/details/