本文主体部分分为四部分,第一部分简介,对BERT模型进行一个简要概述。第二部分介绍BERT模型的结构,BERT模型在结构上的创新不大,利用的主要是Transformer,以及把OpenAI GPT模型的单向Transformer改为了双向,本文不对Transformer结构进行介绍。第三部分介绍预训练,这是本文的重点,也是BERT模型的重点,以及Google关于BERT模型的paper的最大创新点。在第三部分会详细介绍预训练的两个任务,以及训练数据准备和训练数据格式,还有损失函数的计算方法。第四部分介绍预训练好的BERT模型如何在具体任务中应用。
1. 简介
BERT模型是一个新的语言表达模型(language representation model),全称是Bidirectional Encoder Representation Transformers。可以理解为这是一个通用的NLU(Natural Language Understanding)模型,为不同的NLP任务提供支持。在实际使用时,只需要根据具体任务额外加入一个输出层进行微调即可,而不用为特定任务来修改模型结构。这是预训练的BERT模型的主要优点。
目前,有两种策略来使用预训练的语言表达形式(language representation)为下游任务提供支持:feature-based和fine-tuning。Feature-based方法需要根据不同任务设定模型结构,把预训练的表达形式当作额外特征使用。例如我们熟悉的word embedding就是feature-based方法,以及随后出现的更大粒度的embedding方式,如sentence embedding,paragraph embedding。而Fine-tuning方法则是使用尽量少的特定任务参数,在下游具体任务使用时仅需要微调预训练参数即可,BERT模型就属于这种fine-tuning方法。
无论以上哪种方法,在之前的成果中都是使用的单向语言模型来学习语言的一般表达形式。Google的这篇论文认为,单向语言模型严重限制了预训练表达的能力,尤其是对fine-tuning方法。因此BERT模型利用了双向语言模型,并且得到了巨大的能力提升。为了有效训练双向语言模型这篇论文同时提出了两项新的预训练任务目标:masked language model(MLM)和next sentence prediction,这也是这篇论文的最大创新点。
2. BERT模型结构
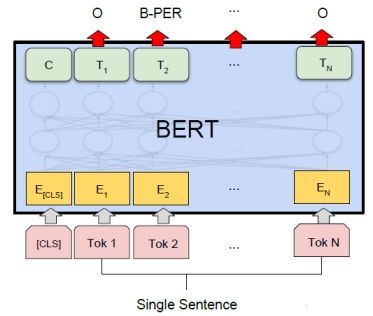
BERT模型的基本结构如Figure 1所示,实质上就是利用Transformer结构构造了一个多层双向的encoder网络,而且Transformer的结构也是直接利用Transformer原作中的结构,并没有做额外的创新(关于Transformer结构可以阅读论文 《Attention is All You Need》)。使用该模型时只需要根据具体任务在Figure 1所示的结构后添加一层输出层即可。在预训练BERT模型时,添加的是一个全连接层,关于预训练我们后面会详细说明。
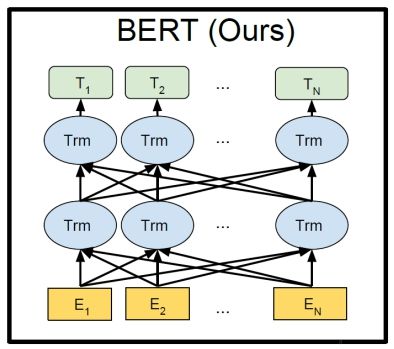
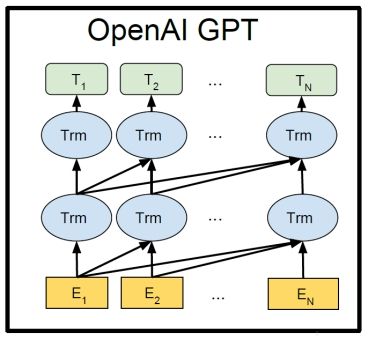
BERT模型结构是对OpenAI GPT模型的优化,将其单向的Transformer结构改成了双向,OpenAI GPT模型的结构如Figure 2所示。
3. 预训练
对Figure 1所示的BERT模型加入一层全连接层后进行训练,就是所谓的BERT预训练。训练之后去掉全连接层的BERT模型就可以被用来进行各种NLP任务。下面介绍介绍如何通过两个预训练任务对加入全连接层后的BERT模型进行训练,从而得到预训练模型。
预训练任务简介
任务1:Masked Language Model
方法:随机遮盖一些词(替换为统一标记[MASK]),然后预测这些被遮盖的词,本文中会随机遮盖每个sequence中的15%的词。
目的:训练双向语言模型,并且使每个词的表达参照上下文信息。
评价:这样做会带来两大缺点:1)会造成预训练和微调时的不一致,因为在微调时[MASK]总是不可见的;2)由于每个batch中只有15%的词会被预测,因此模型的收敛速度比起单向的语言模型会慢,训练花费的时间更长。
对于第一个缺点,本文采取如下策略来应对:把80%需要被替换成[MASK]的词进行替换,10%的随机替换为其他词,10%的不改变。由于Transformer encoder并不知道哪个词需要被预测,哪个词是被随机替换的,这样就强迫每个词的表达需要参照上下文信息。
对于第二个缺点目前没有有效的解决办法,但是对于收益的提升来说付出的代价是值得的。
任务2:Next Sentence Prediction
方法:把50%输入sequence中的句子对的B句子随机替换,然后预测B是否是A的下一句。
目的:获取句子间的信息,这点是语言模型不能直接捕捉到的。
评价:文章结果表明这个简单的任务对QA和NLI任务十分有益。
预训练数据准备
首先对原始语料进行处理,处理具体步骤可以参考附录内容。处理完之后生成训练数据,训练数据形式如Figure 3所示。这种形式既可以把单句(single sentence)表示成一个序列(sequence)也可以把句子对([Question, Answer])表示成一个序列。这里的“sentence”表示任意跨度的连续文本,“sequence”表示BERT模型的输入,既可以是单句,也可以是两句话被打包成一个sequence。一个sequence由三部分相加而来,分别是token embedding,segment embedding和position embedding。被切开的词会标记##符号;每个sequence的开头都会加入特定符号[CLS];用[SEP]分割句子对,并且用segment embedding来标记句子对的两部分,对于单句输入仅使用A embedding。
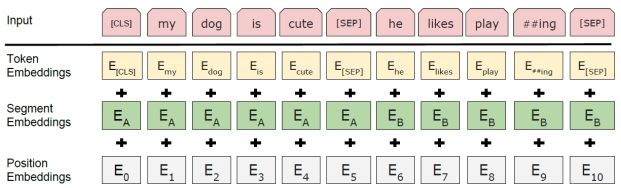
数据例子
数据最终的形式定义如Figure 4所示。
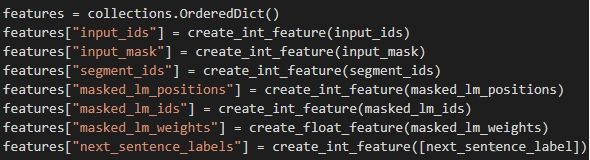
“input_ids”:其大小为设置的最大sequence长度,每个位置表示该位置的token对应的序号,这个序号即是其在词典中的编号,如果这个token是被替换过的,则这个token对应的input_ids是其替换后的token对应的序号。
“input_mask”其大小为设置的最大sequence长度,每个位置只有0和1两种表示,0表示这个位置是通过zero-padding补齐的,1表示这个位置是有token的。
“segment_ids”其大小为设置的最大sequence长度,每个位置只有0和1两种表示,0表示是第一句话,1表示是第二句话,如果1之后又出现0,则表示是被zero-padding补齐的。
“masked_lm_positions”其大小为设置的最大预测tokens数量,每个位置表示需要被预测的token在sequence中的位置,0表示是被zero-padding补齐的。
“masked_lm_ids”其大小为设置的最大预测tokens数量,每个位置表示需要被预测的token在词典中的编号。
“masked_lm_weights”其大小为设置的最大预测tokens数量,每个位置只有0和1两种取值,0表示这个位置是通过zero-padding补齐的,1表示这个位置是有需要预测的token的。
“next_sentence_labels”取值只有0和1,0表示第二句话不是第一句话的下一句,1表示第二句话是第一句话的下一句。
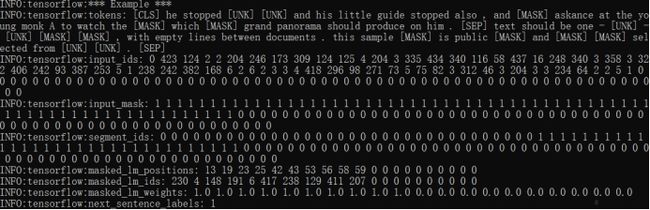
一个生成的预训练输入数据实例如Figure 5所示,这里设置sequence的长度为128,预测最大token数为20,被mask的概率为15%,[UNK]表示词典外的词,[MASK]表示被随机遮盖的词。需要说明的一点是,对输入的语料要求每行一句话,这个对Next Sentence Prediction任务至关重要,然后文档和文档之间通过一个空白行来区分。大家可以通过https://github.com/google-research/bert提供的create_pretraining_data.py脚本来自己生成训练数据,查看结果。
预训练BERT模型
在执行预训练时,会在Figure 1所示结构后添加一层全连接层,然后通过log_softmax输出结果,损失函数是MLM任务和NSP任务两部分的损失之和。
MLM任务损失
全连接层的输入维度为[batch_size * max_predictions_per_seq, hidden_size],其中batch_size表示batch的大小,max_predictions_per_seq表示一个sequence预测的tokens的数量,hidden_size表示Transformer隐藏层维度。全连接层权重矩阵维度[embedding_size, vocab_size],这里embedding_size和hidden_size取相同值。因此全连接层的输出的维度为[batch_size * max_predictions_per_seq, vocab_size],经过log_softmax之后计算每项的算是并求和得到这个batch总损失(由于“masked_lm_weights”的作用,对于zero-padding的token不会计算损失),然后除以需要预测的tokens数,得到的平均损失作为MLM任务的损失输出。
NSP任务损失
这个任务是一个二分类任务,全连接层的权重矩阵维度为[hidden_size, 2],直接与标签的one-hot每项相乘求和,然后平均后当作NSP任务的损失输出。
4. BERT在多种任务中的应用
预训练后的BERT模型可以直接应用于多种任务,包括句子级别的分类任务、问答任务、序列标注任务等等。下面举例几项应用,并说明相应的微调方法。
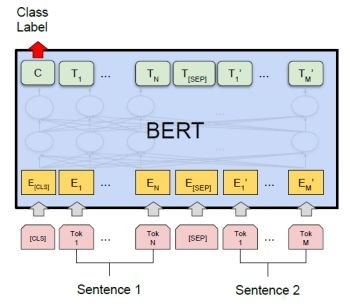
1)句对分类任务
对于句子级别的分类任务,我们采用第一个token(即[CLS])的最后一个隐藏状态的输出作为整个句子的表示,如Figure 6所示:
我们举一个具体的例子,比如给定一句话,然后从4个选项里选择最可能的下一句话:
A girl is going across a set of monkey bars. She
(i) jumps up across the monkey bars.
(ii) struggles onto the bars to grab her head.
(iii) gets to the end and stands on a wooden plank.
(iv) jumps up and does a back flip.
在这项任务里,我们把题目里给的话“A girl is going across a set of monkey bars.”分别与4个选项进行拼接并输入BERT模型,取[CLS]的最后一个隐藏状态的输出分别作为4个句子对的表示。然后我们只需要引入一个维度为隐藏状态个数的向量,然后分别计算4个句子对与这个向量的点乘的结果,并通过softmax进行分类,以此来进行微调训练。
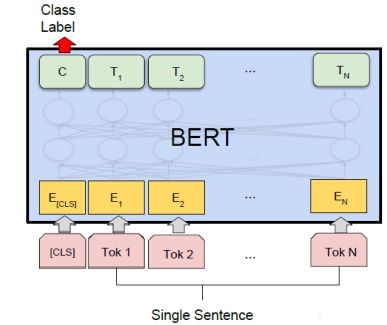
2)单句分类任务
仍然采用第一个token(即[CLS])的最后一个隐藏状态的输出作为整个句子的表示,我们只需引入一层分类层,即一个类别数目*隐藏状态个数的矩阵进行微调即可,如Figure 7所示。
3)序列标注任务
序列标注任务是在token级别进行的,我们用每个token的最后一个隐藏状态的输出作为整个token的表示。以命名实体识别为例,对每个token在NER集合上分类,以此进行模型的微调,如Figure 8所示。