报表应用中实现数据源计算经常会使用存储过程,但同时也带来多方面的问题。首先,存储过程的包只提供一层分类,无法用树形结构组织,容易造成代码管理混乱。程序员更是直接在现场在线修改存储过程,也不利于代码管理。其次,升级存储过程时需要数据库的写权限,容易对数据安全造成影响。另外,由于SQL固有的一些问题(数据无序,缺乏集合,无法引用,分步不彻底,等等),进行存储过程的编程也比较困难。
这主要是因为报表数据的计算一般都比较复杂,很难用SQL直接完成,而是需要通过循环遍历等代码逻辑来控制完成。在这种逻辑中,动辄进行遍历的SQL语句经常会被多次执行,从而使计算要比SQL还慢一个数量级,甚至有些语句的执行速度比外部的Java程序还要低。
另外,还有一个问题,存储过程是存储在数据库内部的,而报表工具的模板一般是文件形式,两者要一起配合工作才能完成报表,但这种分开存储的方式实际上很容易例如,某些报表的模板可能已经被删除了,但对应的存储过程尚未删除。又或者数据库开发者修改了存储过程,却没有通知报表开发者。
为了避免使用存储过程导致上述缺陷端,可以采用润干报表及其内置的集算引擎来完成复杂的数据源计算。两种解决方案的系统结构的对比如下图所示:
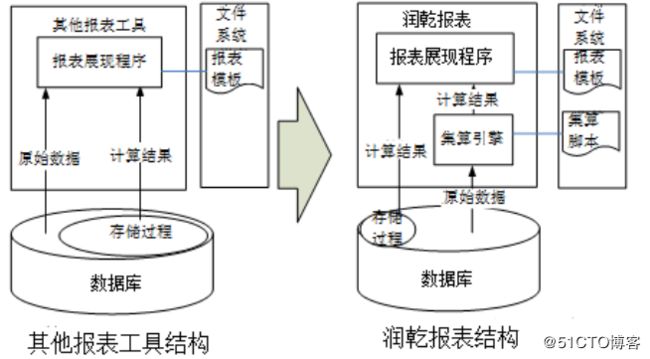
可以看到,润干报表的报表文件(.rpx)和集算脚本(.dfx)是独立的文件,因此可以使用文件系统的树形目录来统一管理,而某些简单脚本还可以直接写进rpx。这样,两者很容易保持一致,方便管理,降低了维护成本。而对于升级过程,润干报表是通过替换这两种文件来完成的,也可以避免在线修改运行环境。同时,集算脚本解决了前面所说的SQL的各种固有问题,编程思维更加自然,比存储过程更加容易。
从性能角度来看,集算引擎提供了并行计算能力,可以充分发挥服务器多CPU多核的性能,也可以连接集算服务器性能,实现多机并行,因此能够在很多情况下获得超过存储过程的性能。
当然,从上图中也可以看到,某些情况下存储过程还是需要的。这是因为涉及数据量大的库内运算时,用存储过程会重新。事实上我们的目标不是完全替代存储过程,甚至利用润干报表尽量减少存储过程的使用,提高综合效率和性能。
下面,我们就通过具体的例子,来看一下润干报表是如何减少存储过程的。
某网络平台需要监测一定周期内部的用户状况,为运营部门出具日报,周报,月报,年报等报表,每类报表都需要进行本期与上期,上上期数据的比较,涉及数据多个杂乱。就以日报为例(月报年报只是统计周期不同)看一下。报表格式如下:

报表分为两部分,上半部分为用户明细数据(本期,上期,上上期在线时长均不为空的用户),而由于用户合并,报表仅显示按本期在线时长时排序的前十名和后十名用户;报表下半部分为本期数据与上期,上上期的比较结果(允许本期,上期,上上期在线时长为空)。
数据来自于两个数据表:
create table T_DW_ZX_ACCOUNT_STATUS_DAY
(
LOGTIME DATE,--日志时间
USERID NUMBER(12),--用户号
ACCOUNT VARCHAR2(50),--账号
ONLINETIME NUMBER(8),--在线时间
PAY NUMBER(11),
EXPEND NUMBER(11),
TOP_LEVEL NUMBER(4)
);
create table T_DW_ZX_VALID_ACCOUNT
(
USERID NUMBER,--用户编号
FIRST_LOGOUT_TIME DATE,--第一次登出时间
STANDARD_7D_TIME DATE,
STANDARD_14D_TIME DATE,
ACCOUNT VARCHAR2(50)
);
首先,看一下存储过程的实现方式(为了说明方便,将其多种颜色不同的四部分):
CREATE OR REPLACE PACKAGE BODY CURSPKG AS
PROCEDURE sp_query_user_status_day(data_date IN varchar2,
top10 OUT T_CURSOR,
last10 in out t_cursor,
var1 out number,
var2 out number,
var3 out number,
var4 out number,
var5 out number,
var6 out number) IS
V_CURSOR1 T_CURSOR; --top10
V_CURSOR2 T_CURSOR; --last10
V_CURSOR T_CURSOR; --temp table
v_ttime date;
temp_num number;
v_valid_user_conti_act1 number;
v_valid_user_back1 number;
v_valid_user_conti_act_lost1 number;
v_valid_user_active_lost1 number;
v_valid_user_add_lost1 number;
v_valid_user_back_lost1 number; BEGIN
v_ttime := to_date(data_date, 'yyyy-mm-dd');
--for temp table
select count(1) into temp_num from account_status_day_temp;
if temp_num > 0 then
delete from account_status_day_temp; --delete first
end if;
insert into account_status_day_temp
select *
from (select v.userid, v.first_logout_time
from t_dw_zx_valid_account v
where v.standard_7d_time is not null) a,
(select userid, sum(onlinetime) onlinetime, max(account)
from t_dw_zx_account_status_day
where logtime >= v_ttime
and logtime < v_ttime + 1
group by userid
having max(account) is not null) b,
(select userid, sum(onlinetime) onlinetime, max(account)
from t_dw_zx_account_status_day
where logtime >= v_ttime - 1
and logtime < v_ttime
group by userid
having max(account) is not null) c,
(select userid, sum(onlinetime) onlinetime, max(account)
from t_dw_zx_account_status_day
where logtime >= v_ttime - 1 - 1
and logtime < v_ttime - 1
group by userid
having max(account) is not null) d
where a.userid = b.userid(+)
and a.userid = c.userid(+);
commit;
--top 10
open V_CURSOR1 for
select *
from (select rownum,
a.auserid userid,
a.first_logout_time,
a.bonlinetime current_onlinetime,
a.conlinetime last_onlinetime,
a.donlinetime last_last_onlinetime
from account_status_day_temp a
order by bonlinetime desc)
where rownum < 11;
--last 10
open V_CURSOR2 for
select *
from (select rownum,
a.auserid userid,
a.first_logout_time,
a.bonlinetime current_onlinetime,
a.conlinetime last_onlinetime,
a.donlinetime last_last_onlinetime
from account_status_day_temp a
order by bonlinetime asc)
where rownum < 11;
top10 := V_CURSOR1;
last10 := V_CURSOR2;
--totalselect
valid_user_conti_act
, valid_user_back
, valid_user_conti_act_lost
, valid_user_active_lost
, valid_user_add_lost
, valid_user_back_lost
into
v_valid_user_conti_act1
, v_valid_user_back1
, v_valid_user_conti_act_lost1
, v_valid_user_active_lost1
, v_valid_user_add_lost1
, v_valid_user_back_lost1
from
(select count(case when buserid is not null and cuserid is not null then 1 else null end) valid_user_conti_act
, count(case when cuserid is null and buserid is not null and first_logout_time < v_ttime-1 then 1 else null end)
, count(case when cuserid is not null and buserid is null then 1 else null end) valid_user_active_lost
, count(case when duserid is not null and cuserid is not null and buserid is null then 1 else null end) valid_user_conti_act_lost
, count(case when duserid is null and cuserid is not null and first_logout_time < v_ttime-1 and buserid is null then 1 else null end) valid_user_back_lost
, count(case when buserid is null and first_logout_time >= v_ttime-1 and first_logout_time < v_ttime then 1 else null end) valid_user_add_lost
from account_status_day_temp);
var1 := v_valid_user_conti_act1;
var2 := v_valid_user_back1;
var3 := v_valid_user_conti_act_lost1;
var4 := v_valid_user_active_lost1;
var5 := v_valid_user_add_lost1;
var6 := v_valid_user_back_lost1;END sp_query_user_status_day;
END CURSPKG;
该存储过程是为日报表服务的,主要计算用户当期和历史时期的比较情况,其中包括明细数据前十名和后十名,用户添加与流失统计等。
第一部分(用于临时表):根据用户明细和状态表过滤汇总数据,按用户统计本期,上期,上上期的情况;中间结果存入临时表(避免重复计算),供后续计算使用。
第二部分(top10部分):根据第一部分的计算结果排序,取前十名,结果以游标返回;
第三部分(last 10部分):与前项类似,倒序排序,获得最后十名,结果以游标返回;
第四部分(总计部分):根据第一部分计算结果完成对相应的综合统计指标计算,结果以六个输出参数返回。
该存储过程综合考虑了报表工具计算能力不足的因素,将尽量多的计算都放到存储过程中完成,这点是值得肯定的。但其中使用较少的复杂sql,以及多结果集的输出方式(游标),这又增加了编程难度。
如果用润干报表来实现这个需求,首先要编写以下集算器脚本:


代码说明:
A1:连接配置好的oracle数据库。
A2-A6:从数据库按照条件和分组汇总,取数。其中的A3,A4,A5的组虽然也可以放到集算脚本中实现,但脚本中还是利用了sql的组,这里的原则是简单的运算尝试还是让数据库去做,这样可以让数据量变少,从而节省JDBC的传输时间;而对于复杂的过程性计算才适合放到集算脚本中做,从而发挥数据库和集算脚本各自的优势。
A7:将以上结果集进行关联。
A8:根据A7建立新序表,用于重复前后十名记录。
A9-A10:通过序号分别取前后十名记录。
A11-A17:计算汇总值。
A19:将前十名,后十名记录以及汇总值分别以不同结果集返回给润干报表。
集算器脚本编写之后,保存为test.dfx,在润干报表中添加集算器数据集进行调用:

润干报表接收集算器脚本返回的三个结果集,其中“ test.dfx”为集算器脚本名称。
下一步,要按照需求重新编制报表模板文件,即可完成报表设计:
