作者:高娜娜 (中南财经政法大学)
Stata 连享会: 知乎 | | 码云
参考文献:Vanlaar W. A shortcut through long loops: An illustration of two alternatives to looping over observations[J]. Stata Journal, 2008, 8(4): 540-553. [PDF]
2020寒假Stata现场班 (北京, 1月8-17日,连玉君-江艇主讲),「+助教招聘」

- Stata连享会 精品专题 || 精彩推文

1. 问题背景
在进行数据处理的时候,我们可能会遇到这样的问题:我们试图将两份数据合并在一起,但是用来合并的唯一可识别的变量却是动态变化的,导致无法依据该变量实现完全的合并。
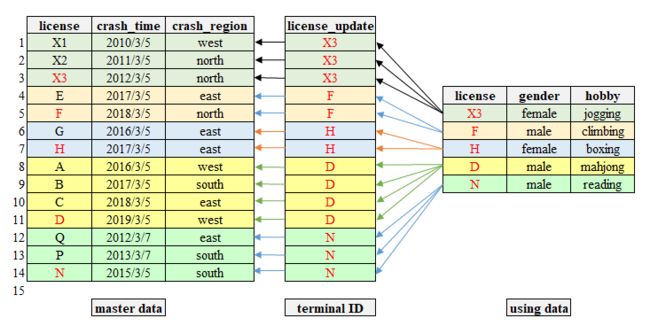
例如,个人的驾驶执照号码发生过变化,在两份与驾驶执照号码有关的数据中,由于数据搜集的过程不同,其中一份数据使用旧的驾驶执照号码,如下图的 master data,第1、2、3 行代表着同一个人,但是有多个驾驶执照号码,每个驾驶执照号码对应一次交通事故。而另一份数据使用最新的驾驶执照号码,如下图的 using data,每个驾驶执照号码对应个人的性别和爱好。
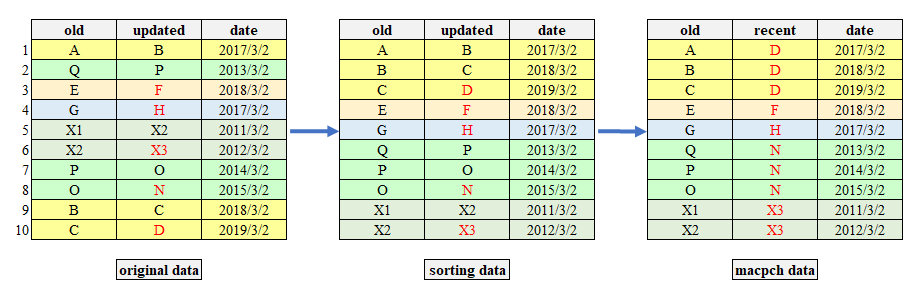
为了成功合并数据,我们需要了解驾驶执照号码的变化过程( 如下图 sorting data ),并得到旧驾驶执照号码( 如下图 mapch data 中的 old 变量 )和最终驾驶执照号码( 如下图 mapch data 中的 recent 变量 )的对应关系。
驾驶执照管理部门能够提供驾驶执照号码的变动,即旧驾驶执照号码( 如下图 sorting data 中的 old 变量 )、更新的驾驶执照号码( 如下图 sorting data 中的 updated 变量 )、驾驶执照号码变动的时间( 如下图 sorting data 中的 date 变量 )。例如,在 sorting data 中,第 1、2 行是同一个人两次更改驾驶执照号码。
如果数据量比较少或者只有少量的驾驶执照号码发生了变化,我们可以手动寻找这些变化,但是如果数据量比较大且大部分人都改变过驾驶执照号码,并且许多人不止改变过一次,用眼寻找的方法将非常耗时。
上图中 sorting data 是我们已经整理好的驾驶执照号码变更过程,比如第 1、2、3 是同一个人驾驶执照号码变化的过程,即 “A-B-C-D”,而实际中,数据的不同行之间是杂乱的,如上图中 original data 所示。
因此,为了得到能够进行数据合并的 mapch data,首先需要对 original data 进行排序,识别每个驾驶员驾驶执照号码的更改过程,即绘制 “事件链” ( mapping the chains of events ),然后需要创建一个新变量 recent,recent 的值为每个 “事件链” 的最终驾驶执照号码。
当我们得到 mapch data 后,便可以根据旧驾驶执照号码( old )将 mapch data 和 master data 合并在一起,然后根据更新的驾驶执照号码( recent )将 master data 和 using data 合并在一起。
在 Stata 中,我们可以通过数据追加、识别和合并一步一步得到最终的 “事件链”,也可以用 mapch 命令直接得到 “事件链” 的信息。下面先用分步的方法识别 “事件链”,再用 mapch 命令实现 “事件链”。
2.分步实现
第一步:构造数据
在 original data 中创建变量 link 并等于 updated 变量,保存此数据;然后在 original data 中创建变量 link 并等于 old 变量;将两份数据追加在一起。根据 link、date 排序后的结果如下所示。
use original,clear
generate link = updated
save original1, replace
use original,clear
generate link = old
append using original1
sort link date
list
+---------------------------------+
| old updated date link |
|---------------------------------|
1. | A B 2017/3/2 A |
2. | A B 2017/3/2 B |
3. | B C 2018/3/2 B |
4. | B C 2018/3/2 C |
5. | C D 2019/3/2 C |
|---------------------------------|
6. | C D 2019/3/2 D |
7. | E F 2018/3/2 E |
8. | E F 2018/3/2 F |
9. | G H 2017/3/2 G |
10. | G H 2017/3/2 H |
|---------------------------------|
11. | O N 2015/3/2 N |
12. | P O 2014/3/2 O |
13. | O N 2015/3/2 O |
14. | Q P 2013/3/2 P |
15. | P O 2014/3/2 P |
|---------------------------------|
16. | Q P 2013/3/2 Q |
17. | X1 X2 2011/3/2 X1 |
18. | X1 X2 2011/3/2 X2 |
19. | X2 X3 2012/3/2 X2 |
20. | X2 X3 2012/3/2 X3 |
+---------------------------------+
第二步:识别 two-step 链
之所以不从识别 one-step 链开始,是因为 original data 本身已经包含了 one-step 链的信息,我们可以通过合并的方式将 original data 中的 one-step 链的信息复制下来。
通过第一步,新构造的数据中增加了两种噪音,即无效的行( 如第 1、16 行 )和 one-step 链的行( 如第 8、10 行 ),需要清理掉这些不需要的数据。
我们根据 link 产生变量 test1,test1 的值是 link 中每个值的个数( 如 “B” 在 link 中出现了 2 次 )。如果 test1 的值不等于2,那么该行或者是 one-step 链,如 link 第 8 行是 “E-F” 的 one-step 链;或者该行对应的 link 值是整条 “事件链” 的最开始的状态,如 link 第 1 行的 A 是 “A-B-C-D” 的开始状态。
bysort link: generate test1=_N
list
+-----------------------------------------+
| old updated date link test1 |
|-----------------------------------------|
1. | A B 2017/3/2 A 1 |
2. | A B 2017/3/2 B 2 |
3. | B C 2018/3/2 B 2 |
4. | B C 2018/3/2 C 2 |
5. | C D 2019/3/2 C 2 |
|-----------------------------------------|
6. | C D 2019/3/2 D 1 |
7. | E F 2018/3/2 E 1 |
8. | E F 2018/3/2 F 1 |
9. | G H 2017/3/2 G 1 |
10. | G H 2017/3/2 H 1 |
|-----------------------------------------|
11. | O N 2015/3/2 N 1 |
12. | P O 2014/3/2 O 2 |
13. | O N 2015/3/2 O 2 |
14. | Q P 2013/3/2 P 2 |
15. | P O 2014/3/2 P 2 |
|-----------------------------------------|
16. | Q P 2013/3/2 Q 1 |
17. | X1 X2 2011/3/2 X1 1 |
18. | X1 X2 2011/3/2 X2 2 |
19. | X2 X3 2012/3/2 X2 2 |
20. | X2 X3 2012/3/2 X3 1 |
+-----------------------------------------+
drop if test1!=2
list
+-----------------------------------------+
| old updated date link test1 |
|-----------------------------------------|
1. | A B 2017/3/2 B 2 |
2. | B C 2018/3/2 B 2 |
3. | B C 2018/3/2 C 2 |
4. | C D 2019/3/2 C 2 |
5. | P O 2014/3/2 O 2 |
|-----------------------------------------|
6. | O N 2015/3/2 O 2 |
7. | Q P 2013/3/2 P 2 |
8. | P O 2014/3/2 P 2 |
9. | X1 X2 2011/3/2 X2 2 |
10. | X2 X3 2012/3/2 X2 2 |
+-----------------------------------------+
现在,我们已经识别了至少包含两个链的 “事件链”,link 中的值均都出现了 2 次,接下来我们创建另一个包含 updated 信息的变量 recent。
recent 变量的值等于每个 link 变量值对应的 updated 变量排序最大的那个值。例如,第1和2行的 link 值为 “B”,其对应的 updated 变量的第 1 和 2 行分别为 “B” 和 “C”,而行数较大的第2行的值为 “C”,因此 link 值为 “B” 时 recent 变量的值为 “C”。
generate str2 recent=""
bysort link: replace recent=updated[_N]
list
+--------------------------------------------------+
| old updated date link test1 recent |
|--------------------------------------------------|
1. | A B 2017/3/2 B 2 C |
2. | B C 2018/3/2 B 2 C |
3. | B C 2018/3/2 C 2 D |
4. | C D 2019/3/2 C 2 D |
5. | P O 2014/3/2 O 2 N |
|--------------------------------------------------|
6. | O N 2015/3/2 O 2 N |
7. | Q P 2013/3/2 P 2 O |
8. | P O 2014/3/2 P 2 O |
9. | X1 X2 2011/3/2 X2 2 X3 |
10. | X2 X3 2012/3/2 X2 2 X3 |
+--------------------------------------------------+
此时,我们已经完成 two-steps 链的识别。例如,从 old 到 link 再到 recent,第1行识别出了 “A-B-C”,第9行识别出了 “X1-X2-X3”。
第三步:识别 three-step 链
在本文的例子中,要将 recent 的值替换为 “事件链” 的结束值,需重复使用识别 two-step 链的步骤。
在重复上述步骤之前,需要清除 two-step 链识别中产生的噪音。例如,上图中的第 2 行、第 8 行的 “事件链” 呈现的是 “B-B-C”、“P-P-O”,而我们需要的是 3 行和第 5 行的 “B-C-D”、“P-O-N”。为了标识出第 2、8 行,我们根据 old 变量产生变量 test2,test2 的值是 old 不同值的个数,test2 的值大于1并且该行对应的 recent 的值和 updated 的值相等时,应该删除该行。
bysort old: generate test3=_N
list
+----------------------------------------------------------+
| old updated date link test1 recent test2 |
|----------------------------------------------------------|
1. | A B 2017/3/2 B 2 C 1 |
2. | B C 2018/3/2 B 2 C 2 |
3. | B C 2018/3/2 C 2 D 2 |
4. | C D 2019/3/2 C 2 D 1 |
5. | O N 2015/3/2 O 2 N 1 |
|----------------------------------------------------------|
6. | P O 2014/3/2 O 2 N 2 |
7. | P O 2014/3/2 P 2 O 2 |
8. | Q P 2013/3/2 P 2 O 1 |
9. | X1 X2 2011/3/2 X2 2 X3 1 |
10. | X2 X3 2012/3/2 X2 2 X3 1 |
+----------------------------------------------------------+
bysort old: drop if updated==recent & test2>1
drop updated test1 test2
save original2, replace
list
+--------------------------------+
| old date link recent |
|--------------------------------|
1. | A 2017/3/2 B C |
2. | B 2018/3/2 C D |
3. | C 2019/3/2 C D |
4. | O 2015/3/2 O N |
5. | P 2014/3/2 O N |
|--------------------------------|
6. | Q 2013/3/2 P O |
7. | X1 2011/3/2 X2 X3 |
8. | X2 2012/3/2 X2 X3 |
+--------------------------------+
接下来通过重复识别 two-step 链的方法识别 three-step 链,即将上图中 recent 的第 1 行和第 6 行分别更改为 D 和 N。
use original2,clear
generate link2 = recent
save original3, replace
use original2,clear
generate link2 = link
append using original3
sort link2 date
list
+----------------------------------------+
| old date link recent link2 |
|----------------------------------------|
1. | A 2017/3/2 B C B |
2. | A 2017/3/2 B C C |
3. | B 2018/3/2 C D C |
4. | C 2019/3/2 C D C |
5. | B 2018/3/2 C D D |
|----------------------------------------|
6. | C 2019/3/2 C D D |
7. | P 2014/3/2 O N N |
8. | O 2015/3/2 O N N |
9. | Q 2013/3/2 P O O |
10. | P 2014/3/2 O N O |
|----------------------------------------|
11. | O 2015/3/2 O N O |
12. | Q 2013/3/2 P O P |
13. | X1 2011/3/2 X2 X3 X2 |
14. | X2 2012/3/2 X2 X3 X2 |
15. | X1 2011/3/2 X2 X3 X3 |
|----------------------------------------|
16. | X2 2012/3/2 X2 X3 X3 |
+----------------------------------------+
bysort link2: generate test1=_N
list
+------------------------------------------------+
| old date link recent link2 test1 |
|------------------------------------------------|
1. | A 2017/3/2 B C B 1 |
2. | A 2017/3/2 B C C 3 |
3. | B 2018/3/2 C D C 3 |
4. | C 2019/3/2 C D C 3 |
5. | B 2018/3/2 C D D 2 |
|------------------------------------------------|
6. | C 2019/3/2 C D D 2 |
7. | P 2014/3/2 O N N 2 |
8. | O 2015/3/2 O N N 2 |
9. | Q 2013/3/2 P O O 3 |
10. | P 2014/3/2 O N O 3 |
|------------------------------------------------|
11. | O 2015/3/2 O N O 3 |
12. | Q 2013/3/2 P O P 1 |
13. | X1 2011/3/2 X2 X3 X2 2 |
14. | X2 2012/3/2 X2 X3 X2 2 |
15. | X1 2011/3/2 X2 X3 X3 2 |
|------------------------------------------------|
16. | X2 2012/3/2 X2 X3 X3 2 |
+------------------------------------------------+
drop if test1!=3
list
+------------------------------------------------+
| old date link recent link2 test1 |
|------------------------------------------------|
1. | A 2017/3/2 B C C 3 |
2. | B 2018/3/2 C D C 3 |
3. | C 2019/3/2 C D C 3 |
4. | Q 2013/3/2 P O O 3 |
5. | P 2014/3/2 O N O 3 |
|------------------------------------------------|
6. | O 2015/3/2 O N O 3 |
+------------------------------------------------+
generate str2 recent2=""
bysort link2: replace recent2=recent[_N]
drop test1
save original4.dta,replace
list
+--------------------------------------------------+
| old date link recent link2 recent2 |
|--------------------------------------------------|
1. | A 2017/3/2 B C C D |
2. | B 2018/3/2 C D C D |
3. | C 2019/3/2 C D C D |
4. | Q 2013/3/2 P O O N |
5. | P 2014/3/2 O N O N |
|--------------------------------------------------|
6. | O 2015/3/2 O N O N |
+--------------------------------------------------+
第四步:形成完整的 mapch data
通过上述数据处理,我们已经形成了包含 one-step 链信息的 original.dta,包含 two-step 链信息的 original2.dta,包含 three-step 链信息的 original4.dta,接下来只需将这些数据合并即可。
use original,clear
merge 1:1 old using original2.dta
drop _merge
replace recent=updated if recent==""
merge 1:1 old using original4.dta
drop _merge
replace recent2=recent if recent2==""
list
+------------------------------------------------------------+
| old updated date link recent link2 recent2 |
|------------------------------------------------------------|
1. | A B 2017/3/2 B C C D |
2. | B C 2018/3/2 C D C D |
3. | C D 2019/3/2 C D C D |
4. | E F 2018/3/2 F F |
5. | G H 2017/3/2 H H |
|------------------------------------------------------------|
6. | O N 2015/3/2 O N O N |
7. | P O 2014/3/2 O N O N |
8. | Q P 2013/3/2 P O O N |
9. | X1 X2 2011/3/2 X2 X3 X3 |
10. | X2 X3 2012/3/2 X2 X3 X3 |
+------------------------------------------------------------+
其中,从 old 到 recent2 便是“事件链”的最终映射。
3. 使用 mapch 命令:更高效的处理方式
mapch 是 “map chains of events” 的简写,语法如下:
mapch begin end [time]
其中,begin 是一个事件的开始状态,正如上文中的 old 变量,end 是一个事件的结束状态,正如上文中的 updated 变量。mapch 可以在包含事件发生时间的数据中使用,也可以应用于没有事件发生时间的数据。
使用 mapch 命令会产生两个新的变量 recent 和 NoofEvents,recent 对应出了 begin 变量的结束状态,NoofEvents 包含从 begin 到 recent 每个链的事件数,同时还报告出了 n-step 链的频率。
use original,clear
mapch old updated date
********************
* Mapping complete *
********************
Frequency of NoOfEvents:
NoOfEvents | Freq. Percent Cum.
------------+-----------------------------------
1 | 2 20.00 20.00
2 | 2 20.00 40.00
3 | 6 60.00 100.00
------------+-----------------------------------
Total | 10 100.00
The number of 1-step chains is equal to 2/1
The number of 2-step chains is equal to 2/2
The number of 3-step chains is equal to 6/3
+----------------------------------------------+
| old updated date recent NoOfEv~s |
|----------------------------------------------|
1. | A B 2017/3/2 D 3 |
2. | B C 2018/3/2 D 3 |
3. | C D 2019/3/2 D 3 |
4. | E F 2018/3/2 F 1 |
5. | G H 2017/3/2 H 1 |
|----------------------------------------------|
6. | Q P 2013/3/2 N 3 |
7. | P O 2014/3/2 N 3 |
8. | O N 2015/3/2 N 3 |
9. | X1 X2 2011/3/2 X3 2 |
10. | X2 X3 2012/3/2 X3 2 |
+----------------------------------------------+
如果数据中不包含事件发生的时间,那么使用 mapch 命令后会产生一个 date 变量。
use original,clear
drop date
mapch old updated
list
+------------------------------------------+
| old updated date recent NoOfEv~s |
|------------------------------------------|
1. | A B 1 D 3 |
2. | B C 2 D 3 |
3. | C D 3 D 3 |
4. | E F . F 1 |
5. | G H . H 1 |
|------------------------------------------|
6. | Q P 1 N 3 |
7. | P O 2 N 3 |
8. | O N 3 N 3 |
9. | X1 X2 1 X3 2 |
10. | X2 X3 2 X3 2 |
+------------------------------------------+
参考文献:Vanlaar W. A shortcut through long loops: An illustration of two alternatives to looping over observations[J]. Stata Journal, 2008, 8(4): 540-553. [PDF]
关于我们
- Stata连享会 由中山大学连玉君老师团队创办,定期分享实证分析经验。
- 推文同步发布于 CSDN 、 和 知乎Stata专栏。可在百度中搜索关键词 「Stata连享会」查看往期推文。
- 点击推文底部【阅读原文】可以查看推文中的链接并下载相关资料。
- 欢迎赐稿: 欢迎赐稿。录用稿件达 三篇 以上,即可 免费 获得一期 Stata 现场培训资格。
- E-mail: [email protected]
- 往期精彩推文:一网打尽
