silk v3录音转olami语音识别和语义处理的api服务(ubuntu16.04服务器上实现)
重要的写在前面
重要事项一:
目前本文中提到的API已支持微信小程序录音文件格式:silk v3、webm/base64。
注:微信小程序开发工具上的录音虽然后辍名也是silk,但不是真正的silk v3格式的(打开xx.silk看头部是“data:audio/webm;base64,”开头的),为了便于调试,这类格式我今天加急给支持上了,所以:微信小程序开发工具也可以调用我的API调试了。
重要事项二:
想要用我这个API,务必先去cn.olami.ai申请appKey和appSecret,然后将appKey告知我,我加进支持列表方可调用,二者缺一不可。文末有将有调用此文提到的API服务的案例以及源码分享文章链接。
调用案例:“遥知之”智能小秘,欢迎扫码体验:

重要事项三:
欢迎转载本文,没有什么别的要求,请保留:
原文链接:http://blog.csdn.net/happycxz/article/details/78016299
本文所有源码对应码云链接:https://gitee.com/happycxz/silk2asr
本文所有源码对应github链接:https://github.com/happycxz/silk2asr
为什么做?
前不久刚发布了一个智能生活信息查询的小助手“遥知之”,可惜只能手动输入来玩,这一点体验很不好,因为微信小程序录音是silk格式的,现在主要的语音识别接口都不支持。
在网上搜了下相应的功能,也只有php做的开源代码实现的silk转wav的服务器代码,首先我不熟悉PHP,其次也不知道后期有没有维护,干脆自己做一个tomcat + java版的,权当学习娱乐一下。
怎么做?
准备环境
先需要有一个支持https的服务器,我目前用的服务器是阿里云秒杀的免费最低配置的服务器,预装的ubuntu16.04 LTS版,然后自己捣鼓一下,配置上了https,具体是用 nginx + let's encrypt + tomcat来提供的https的API。这里不详细介绍,感兴趣的自己研究下。
需要一个silk解码器,网上有一牛在2015年年初曾经发贴讨论过这个话题:silk v3 编码的音频怎么转换成 wav 或 mp3 之类的?
而且此牛后面有持续研究,提供了开源的silk_v3_decoder项目,具体见:kn007大牛的silk_v3_decoder
对了,开源项目是github上的,服务器上装个git,这不用额外再说明了吧。
搭建服务步骤
下载silk-v3-decoder
基本就是在服务器上找个目录,把大牛kn007的项目下载下来。
root@alijod:/home/jod/wechat_app# mkdir download
root@alijod:/home/jod/wechat_app# cd download/
root@alijod:/home/jod/wechat_app/download# git clone https://github.com/kn007/silk-v3-decoder.git
Cloning into 'silk-v3-decoder'...
remote: Counting objects: 634, done.
remote: Total 634 (delta 0), reused 0 (delta 0), pack-reused 634
Receiving objects: 100% (634/634), 72.79 MiB | 9.50 MiB/s, done.
Resolving deltas: 100% (352/352), done.
Checking connectivity... done.
root@alijod:/home/jod/wechat_app/download# ll
total 12
drwxr-xr-x 3 root root 4096 Sep 18 10:11 ./
drwxr-xr-x 7 root root 4096 Sep 18 10:11 ../
drwxr-xr-x 5 root root 4096 Sep 18 10:11 silk-v3-decoder/
root@alijod:/home/jod/wechat_app/download# ls silk-v3-decoder/
converter_beta.sh converter.sh LICENSE README.md silk windows
看上述目录,其实只用到了silk这个目录,和converter.sh这个脚本。silk目录中的C代码需要gcc编译,converter.sh脚本需要修改一下,后续都会提。
编译silk_v3_decoder
根据https://github.com/kn007/silk-v3-decoder上的README,用上这个工具,需要gcc和ffmpeg,gcc是在编译silk时执行make时用到的(普及一下小白),ffmpeg其实是脚本里要用的,与编译无关。事实是,ffmpeg在整个服务搭建过程确实不是必备的,后文将有针对这个额外说明,只是本人偷懒,暂时不想再深入研究了。
gcc的环境,如果没有安装,自己网搜吧,这里不扯了,直接进入正题:
root@alijod:/home/jod/wechat_app/download# cd silk-v3-decoder/silk/
root@alijod:/home/jod/wechat_app/download/silk-v3-decoder/silk# ll
total 32
drwxr-xr-x 5 root root 4096 Sep 18 10:11 ./
drwxr-xr-x 5 root root 4096 Sep 18 10:11 ../
drwxr-xr-x 2 root root 4096 Sep 18 10:11 interface/
-rw-r--r-- 1 root root 3278 Sep 18 10:11 Makefile
drwxr-xr-x 2 root root 12288 Sep 18 10:11 src/
drwxr-xr-x 2 root root 4096 Sep 18 10:11 test/
root@alijod:/home/jod/wechat_app/download/silk-v3-decoder/silk# make
…………
…………(这里是一大段编译过程日志)
…………
a - src/SKP_Silk_scale_vector.o
gcc -c -Wall -enable-threads -O3 -Iinterface -Isrc -Itest -o test/Decoder.o test/Decoder.c
test/Decoder.c: In function ‘main’:
test/Decoder.c:187:9: warning: ignoring return value of ‘fread’, declared with attribute warn_unused_result [-Wunused-result]
fread(header_buf, sizeof(char), 1, bitInFile);
^
g++ -L./ test/Decoder.o -lSKP_SILK_SDK -o decoder
root@alijod:/home/jod/wechat_app/download/silk-v3-decoder/silk# ls
decoder interface libSKP_SILK_SDK.a Makefile src test
root@alijod:/home/jod/wechat_app/download/silk-v3-decoder/silk#
可以看到,上面编译过程中,最后出现了一个warning,不过没关系,ls查一下,第一个“decoder”就是我们要用的binary啦,有它就证明编译成功了。
测试silk_v3_decoder功能
接下来就要验证一下编出来的这个能不能用了。
根据https://github.com/kn007/silk-v3-decoder上的README,摘下来一段:
sh converter.sh silk_v3_file/input_folder output_format/output_folder flag(format)
比如转换一个文件,使用:
sh converter.sh 33921FF3774A773BB193B6FD4AD7C33E.slk mp3
注意:其中33921FF3774A773BB193B6FD4AD7C33E.slk是要转换的文件,而mp3是最终转换后输出的格式。
参考上面那个例子就好了,脚本参数只有两个,一个是源文件相对或绝对路径,另一个是目标格式。
也就是说上述命令会将33921FF3774A773BB193B6FD4AD7C33E.slk(注意,例子里是slk后辍,你自己在获取微信小程序录音重命名时如果是.silk,别疑惑了,linux环境文件后辍名是没有实际意义的,感兴趣自己网搜,to小白)转码成33921FF3774A773BB193B6FD4AD7C33E.mp3。
没有silk源文件?别急,我准备了个silk_v3录音文件,附带着转出来的mp3一起放在我服务器上了,需要的可以去下载(右击后另存即可,mp3可以在线播放,silk播放不了,直接单击会“403”):
微信小程序原始录音文件:sample.silk
converter.sh脚本转码后的文件:sample.mp3
附上我转码的操作过程:
root@alijod:/home/jod/wechat_app/download/silk-v3-decoder# ll
total 48
drwxr-xr-x 5 root root 4096 Sep 18 10:43 ./
drwxr-xr-x 3 root root 4096 Sep 18 10:11 ../
-rw-r--r-- 1 root root 4131 Sep 18 10:11 converter_beta.sh
-rw-r--r-- 1 root root 3639 Sep 18 10:11 converter.sh
drwxr-xr-x 8 root root 4096 Sep 18 10:11 .git/
-rw-r--r-- 1 root root 1076 Sep 18 10:11 LICENSE
-rw-r--r-- 1 root root 3582 Sep 18 10:11 README.md
-rw-r----- 1 root root 6188 Sep 18 10:43 sample.silk
drwxr-xr-x 5 root root 4096 Sep 18 10:26 silk/
drwxr-xr-x 3 root root 4096 Sep 18 10:11 windows/
root@alijod:/home/jod/wechat_app/download/silk-v3-decoder#
root@alijod:/home/jod/wechat_app/download/silk-v3-decoder#
root@alijod:/home/jod/wechat_app/download/silk-v3-decoder# sh converter.sh sample.silk mp3
-e [OK] Convert sample.silk To sample.mp3 Finish.
root@alijod:/home/jod/wechat_app/download/silk-v3-decoder# ll
total 68
drwxr-xr-x 5 root root 4096 Sep 18 10:43 ./
drwxr-xr-x 3 root root 4096 Sep 18 10:11 ../
-rw-r--r-- 1 root root 4131 Sep 18 10:11 converter_beta.sh
-rw-r--r-- 1 root root 3639 Sep 18 10:11 converter.sh
drwxr-xr-x 8 root root 4096 Sep 18 10:11 .git/
-rw-r--r-- 1 root root 1076 Sep 18 10:11 LICENSE
-rw-r--r-- 1 root root 3582 Sep 18 10:11 README.md
-rw-r--r-- 1 root root 17709 Sep 18 10:43 sample.mp3
-rw-r----- 1 root root 6188 Sep 18 10:43 sample.silk
drwxr-xr-x 5 root root 4096 Sep 18 10:26 silk/
drwxr-xr-x 3 root root 4096 Sep 18 10:11 windows/
关于converter.sh脚本
vim打开converter.sh脚本,显示一下行号(vim中输入":set nu"后回车,我为小白操心不少),想要简单使用,其实只需要关注最后面这一段,如果想要深入研究,最好是把脚本完整过程搞懂。
61
62 $cur_dir/silk/decoder "$1" "$1.pcm" > /dev/null 2>&1
63 if [ ! -f "$1.pcm" ]; then
64 ffmpeg -y -i "$1" "${1%.*}.$2" > /dev/null 2>&1 &
65 ffmpeg_pid=$!
66 while kill -0 "$ffmpeg_pid"; do sleep 1; done > /dev/null 2>&1
67 [ -f "${1%.*}.$2" ]&&echo -e "${GREEN}[OK]${RESET} Convert $1 to ${1%.*}.$2 success, ${YELLOW}but not a silk v3 encoded file.${RESET}"&&exit
68 echo -e "${YELLOW}[Warning]${RESET} Convert $1 false, maybe not a silk v3 encoded file."&&exit
69 fi
70 ffmpeg -y -f s16le -ar 24000 -ac 1 -i "$1.pcm" "${1%.*}.$2" > /dev/null 2>&1
71 ffmpeg_pid=$!
72 while kill -0 "$ffmpeg_pid"; do sleep 1; done > /dev/null 2>&1
73 rm "$1.pcm"
74 [ ! -f "${1%.*}.$2" ]&&echo -e "${YELLOW}[Warning]${RESET} Convert $1 false, maybe ffmpeg no format handler for $2."&&exit
75 echo -e "${GREEN}[OK]${RESET} Convert $1 To ${1%.*}.$2 Finish."
76 exit
其实关键的两行也就是Line 62和Line 70。第62行就是调用我们上文编出来的decoder解码silk_v3文件,第70行是将silk_v3文件解码出来的raw data数据转成相应格式。
这里额外说明一下我跟这两行的几个插曲:
插曲一:speex压缩
我做这个SILK语音识别服务的起初目的是让我的“遥知之”支持语音输入功能,“遥知之”上用的OLAMI接口也有语音识别,而且研究了一下他们的JAVA SDK和在线文档,从在线文档(OLAMI 文档中心->语音识别接口文档->“支持的音频格式”)上看是支持wav格式,另外支持speex压缩。
wav格式文件是很占空间的(相当于PCM原始采样数据未经压缩的,加了一个文件头),如下图所示(可能实际speex压缩的效果会更好一点):

如果将数据通过speex压缩,就只需要脚本中的第62行,就不用依赖ffmpeg去转码也可以直接省流量上传到OLAMI语音识别服务器了。这里就是为什么我前面说到,ffmpeg并不是此服务搭建中必备之原因。
如果通过speex会大大降低传输效率,于是期间我有花蛮长时间在研究如何将pcm数据转成speex的,比如怎么调用c代码实现的speex的编码(java下通过JNI调用speex的encoder,研究未果,放弃了这个方案),后来又找了jspeex(java版的speex codec)等等,后面因有另一个省事方案,这里用jspeex的方案就中断未深入研究了,其实应该是行的通的。
在QQ群(群号:656580961)里提了一下,热心的群主“黄眉毛”说olami java sdk里默认是将wav或pcm通过speex压缩传输的,这样一来,我只需要将wav或pcm对接olami java sdk就可以实现“省流量”传输到olami语音识别服务器了。这就是我最终采用的省事方案。
插曲二:采样率不适配
发现通过微信小程序端录音出来的silk v3文件,经过kn007的converter.sh转出来的wav文件,再送到olami语音识别接口,发现识别效果很糟,把wav文件拿出来听听,似乎也正常。
这时候想起来脚本中PCM转wav是按24K转的,转出来的WAV应该是24K的,而olami语音识别端支持的是16K(讯飞还支持8K的),可能是这个采样率不一致导致的识别率差,网搜了一下,还真有前人碰到过相同问题,参见此文文中提到的“误打误撞”那一段:从微信中提取语音文件,并转换成文字的全自动化解决方案 ,他的误打误撞的原理应该是小程序录音就是双通道12K的,然后ffmpeg额外指定一下参数将双通道12K的数据流转成16K的wav。
这下好了,离不开ffmpeg了,需要它帮着转采样率呀,speex压缩又不负责解决采样率转换的问题。
重要的事说三遍:在原始脚本的基础上,修改一下第70行:
重要的事说三遍:在原始脚本的基础上,修改一下第70行:
重要的事说三遍:在原始脚本的基础上,修改一下第70行:
ffmpeg -y -f s16le -ar 12000 -ac 2 -i "$1.pcm" -f wav -ar 16000 -ac 1 "${1%.*}.$2" > /dev/null 2>&1
插曲三:假silk真webm/base64格式
在使用微信小程序开发工具模拟手机做调试时,录音文件不能被silk和ffmpeg转,vim打开一看,头部是“data:audio/webm;base64,”。
由此引伸出一个现象:微信小程序的录音不全是silk v3格式,其中还有刚刚提到的webm/base64的,好像还有AMR格式的,听kn007大神说还有混淆格式,也就是那种一个文件含多种格式混合的,也不知道为什么会有这种情况。
关于webm/base64格式,kn007的回复是,base64 decoder然后直接ffmpeg转,于是我分两步实现:
第一步:用java代码做base64 decoder,再将文件写到 xxx.webm文件中,这部分简单,可参考微信小程序 录音文件格式silk 坑那样做即可。
第二步:再调用ffmpeg命令直接转码成wav,主要是调用一下下述转码命令转成16K的WAV:
ffmpeg -i "$1" -f wav -ar 16000 -ac 1 "${1%.*}.$2" > /dev/null 2>&1
其中调用ffmpeg命令容易出现失败,原因之一可能会是文件读写权限不足,原因之二可能会是调用ffmpeg后,需要等ffmpeg进程消失,即转码任务完成,才退出。 觉得我个人碰到的问题应该是原因之二导致的,因为我确实是将/usr/bin/ffmpeg设置成了777权限,还是会转失败,将调ffmpeg命令的部分在脚本中实现,并且加上kn007大神converter.sh中那样的等待ffmpeg完成的部分,就搞定了。
为了让脚本更通用,我将上述解决采样率不匹配的问题,修改后的脚本基础上,又添加了对webm格式的单独ffmpeg转码支持(通过判断传入第1个参数的后辍是否是webm来判断是不是直接ffmpeg转码然后exit,简单粗暴并且高效!)大概在脚本的上方添加下面这一段:
SOURCE_FILE_SUFFIX=${1##*.}
echo -e "XXXX SOURCE_FILE_SUFFIX:${SOURCE_FILE_SUFFIX}"
if [ "${SOURCE_FILE_SUFFIX}" = "webm" ]; then
## if webm, ffmpeg it directly. webm/base64 had been base64 decoder on my java server already.
echo -e "begin to ffmpeg $2 from webm now..."
ffmpeg -i "$1" -f wav -ar 16000 -ac 1 "${1%.*}.$2" > /dev/null 2>&1
##ffmpeg -i "$1" -f wav "${1%.*}.$2" > /dev/null 2>&1
ffmpeg_pid=$!
while kill -0 "$ffmpeg_pid"; do sleep 1; done > /dev/null 2>&1
[ ! -f "${1%.*}.$2" ]&&echo -e "${YELLOW}[Warning]${RESET} Convert $1 false, maybe ffmpeg no format handler for $2."&&exit
echo -e "${GREEN}[OK]${RESET} Convert $1 To ${1%.*}.$2 Finish."
exit
else
echo -e "begin to silk decoder flow..."
## if not webm, follows default silk decoder road.
fi
至此,converter_cxz.sh修改结束。
搭建web服务及主要代码说明
前面相当于评估可行性,基本验证了从小程序录音文件 xx.silk 到语音识别API能认的数据或文件格式,这条路走通了,接下来就是堆JAVA代码实现细节部分了。
创建sprinMVC工程
大概的工程目录结构如下:
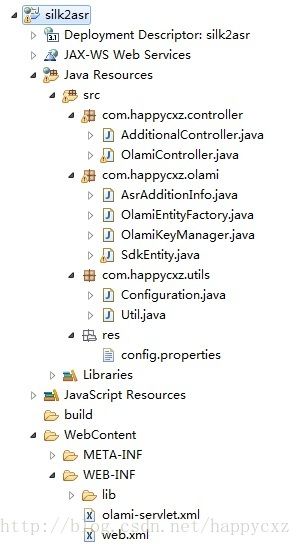
com.happycxz.controller中有两个controller:
第1个,AdditionalController.java是用来查服务器状态和在线更新数据用的,可忽略。
第2个,OlamiController.java是对接微信小程序silk文件上传API接口的,代码如下:
package com.happycxz.controller;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.security.NoSuchAlgorithmException;
import java.util.Map;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.Part;
import org.springframework.stereotype.Controller;
import org.springframework.util.StringUtils;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import com.happycxz.olami.AsrAdditionInfo;
import com.happycxz.olami.OlamiEntityFactory;
import com.happycxz.olami.SdkEntity;
import com.happycxz.utils.Configuration;
import com.happycxz.utils.Util;
import com.sun.org.apache.xml.internal.security.utils.Base64;
/**
* olami与微信小程序 接口相关对接
* @author Jod
*/
@Controller
@RequestMapping("/olami")
public class OlamiController {
//保存linux shell命令字符串
private static final String SHELL_CMD = Configuration.getInstance().getValue("local.shell.cmd", "sh /YOUR_PATH/silk-v3-decoder/converter_cxz.sh %s wav");
//保存silk和wav文件的目录,放在web目录、或一个指定的绝对目录下
private static final String localFilePath = Configuration.getInstance().getValue("local.file.path", "/YOUR/LOCAL/VOICE/PATH/");;
static {
Util.p("OlamiController base SHELL_CMD:" + SHELL_CMD);
Util.p("OlamiController base localFilePath:" + localFilePath);
}
@RequestMapping(value="/asr", produces="plain/text; charset=UTF-8")
public @ResponseBody String asrUploadFile(HttpServletRequest request, HttpServletResponse response, @RequestParam Map p)
throws ServletException, IOException {
AsrAdditionInfo additionInfo = new AsrAdditionInfo(p);
if (additionInfo.getErrCode() != 0) {
//参数不合法,或者appKey没有在支持列表中备录
return Util.JsonResult(String.valueOf(additionInfo.getErrCode()), additionInfo.getErrMsg());
}
String localPathToday = localFilePath + Util.getDateStr() + File.separator;
// 如果文件存放路径不存在,则mkdir一个
File fileSaveDir = new File(localPathToday);
if (!fileSaveDir.exists()) {
fileSaveDir.mkdirs();
}
int count = 1;
String asrResult = "";
for (Part part : request.getParts()) {
String fileName_origin = extractFileName(part);
//这里必须要用原始文件名是否为空来判断,因为part列表是所有数据,前三个被formdata占了,对应文件名其实是空
if(!StringUtils.isEmpty(fileName_origin)) {
String fileName = additionInfo.getVoiceFileName();
String silkFile = localPathToday + fileName;
Util.p("silkFile[" + count + "]:" + silkFile);
part.write(silkFile);
if (webmBase64Decoder2Wav(silkFile)) {
// support webm/base64 in webmBase64Decoder2Wav();
// is webm base64 format, and xxxx.webm file is temporary created, xxxx.wav was last be converted.
} else {
// run script to convert silk(v3) to wav
Util.RunShell2Wav(SHELL_CMD, silkFile);
}
// get wave file path and name, prepare for olami asr
String waveFile = DotSilk2DotOther(silkFile, "wav");
Util.p("OlamiController.asrUploadFile() waveFile:" + waveFile);
if (new File(waveFile).exists() == false) {
Util.w("OlamiController.asrUploadFile() wav file[" + waveFile + "] not exist!", null);
return Util.JsonResult("80", "convert silk to wav failed, NOW NOT SUPPORT WXAPP DEVELOP RECORD because it is not silk_v3 format. anyother reason please tell QQ:404499164.");
}
try {
SdkEntity entity = OlamiEntityFactory.createEntity(additionInfo.getAppKey(), additionInfo.getAppSecret(), additionInfo.getUserId());
asrResult = entity.getSpeechResult(waveFile);
Util.p("OlamiController.asrUploadFile() asrResult:" + asrResult);
} catch (NoSuchAlgorithmException | InterruptedException e) {
Util.w("OlamiController.asrUploadFile() asr NoSuchAlgorithmException or InterruptedException", e);
} catch (FileNotFoundException e) {
Util.w("OlamiController.asrUploadFile() asr FileNotFoundException", e);
return Util.JsonResult("80", "convert silk to wav failed, NOW NOT SUPPORT WXAPP DEVELOP RECORD because it is not silk_v3 format. anyother reason please tell QQ:404499164.");
} catch (Exception e) {
Util.w("OlamiController.asrUploadFile() asr Exception", e);
}
}
count++;
}
//防止数据传递乱码
//response.setContentType("application/json;charset=UTF-8");
return Util.JsonResult("0", "olami asr success!", asrResult);
}
/**
* 将 xxxxx.silk 文件名转 xxxx.wav
* @param silkName
* @param otherSubFix
* @return
*/
private static String DotSilk2DotOther(String silkName, String otherSubFix) {
int removeByte = 4;
if (silkName.endsWith("silk")) {
removeByte = 4;
} else if (silkName.endsWith("slk")) {
removeByte = 3;
}
return silkName.substring(0, silkName.length()-removeByte) + otherSubFix;
}
/**
* 从content-disposition头中获取源文件名
*
* content-disposition头的格式如下:
* form-data; name="dataFile"; filename="PHOTO.JPG"
*
* @param part
* @return
*/
@SuppressWarnings("unused")
private String extractFileName(Part part) {
String contentDisp = part.getHeader("content-disposition");
String[] items = contentDisp.split(";");
for (String s : items) {
if (s.trim().startsWith("filename")) {
return s.substring(s.indexOf("=") + 2, s.length()-1);
}
}
return "";
}
/**
* 通过filePath内容判断是否是webm/base64格式,如果是,先decode base64后,再直接ffmpeg转wav,
* 如果不是,返回false丢给外层继续当作silk v3去解
* @param filePath
* @return
*/
public static boolean webmBase64Decoder2Wav(String filePath) {
boolean isWebm = false;
try {
String encoding = "utf-8";
File file = new File(filePath);
// 判断文件是否存在
if ((file.isFile() == false) || (file.exists() == false)) {
Util.w("webmBase64Decoder2Wav() no file[" + filePath + "] exist.", null);
}
StringBuilder lineTxt = new StringBuilder();
String line = null;
try (
InputStreamReader read = new InputStreamReader(new FileInputStream(file), encoding);
BufferedReader bufferedReader = new BufferedReader(read);) {
while ((line = bufferedReader.readLine()) != null) {
lineTxt.append(line);
}
read.close();
} catch (Exception e) {
Util.w("webmBase64Decoder2Wav() exception0:", e);
return isWebm;
}
String oldData = lineTxt.toString();
if (oldData.startsWith("data:audio/webm;base64,") == false) {
Util.d("webmBase64Decoder2Wav() file[" + filePath + "] is not webm, or already decoded." );
return isWebm;
}
isWebm = true;
oldData = oldData.replace("data:audio/webm;base64,", "");
String webmFileName = DotSilk2DotOther(filePath, "webm");
try {
File webmFile = new File(webmFileName);
byte[] bt = Base64.decode(oldData);
FileOutputStream in = new FileOutputStream(webmFile);
try {
in.write(bt, 0, bt.length);
in.close();
} catch (IOException e) {
Util.w("webmBase64Decoder2Wav() exception1:", e);
return isWebm;
}
} catch (FileNotFoundException e) {
Util.w("webmBase64Decoder2Wav() exception2:", e);
return isWebm;
}
// run cmd to convert webm to wav
Util.RunShell2Wav(SHELL_CMD, webmFileName);
} catch (Exception e) {
Util.w("webmBase64Decoder2Wav() exception3:", e);
return isWebm;
}
return isWebm;
}
public static void main(String[] args) {
webmBase64Decoder2Wav("D:\\secureCRT_RZSZ\\1505716415538_f7d98081-4d21-3b40-a7df-e56c046a784d_b4118cd178064b45b7c8f1242bcde31f.silk");
}
}
利用springMVC的注解,很方便的实现API功能,主要看这个asrUploadFile方法,参数包括request和response之外,还有一个Map结构的p,这个p是用来接收formdata的,即上传录音文件时附带的信息。
我这里强制了必须上传appKey、appSecret以及userId,因为我是直接对接的olami开放平台的接口。
大概的流程是(懒的画流程图了,直接看上面代码,很容易看明白的):
- 接收p中上传的appKey、appSecret以及userId这三个必选参数
- 接收request中的Parts,获取原始silk格式文件及对应的上传文件名
这里面其实是包括file和formdata的,这里还掉进一个坑过,想着不需要调用“extractFileName”来拿原始文件名,直接收以请求,随机生成一个文件名保存了得了,事实是,通过“extractFileName”拿文件名,当文件名为""或null时,这时候是formdata,不是文件,强制保存成文件肯定就出问题了(调试时发现有些录音文件里只有一个很短的数字字母组成的字符串,就是这个原因)。 - 将文件另取个名字保存到服务器指定目录
为什么要另存文件名:微信小程序上传的录音文件统一是wx-file.silk,不像小程序开发工具上录音那样文件名随机生成。 - 这里有个额外判断第3步中保存的xxx.silk是不是webm/base64格式的,如果是,就直接base64 decoder后保存文件 xxx.webm,然后调用converter_cxz.sh将webm格式的文件转码成xxx.wav的,走完流程或异常都跳过下一步,直接到第6步。如果不是webm/base64格式的,返回false,继续走下一步。
- 调用silk_v3_decoder中的脚本(这里是上文提到的修改之后的脚本,我给重命名converter_cxz.sh了)转xxx.wav
- 通过原来的silk文件全路径,计算出wav文件全路径
- 通过上一步得到的wav文件全路径,以及appKey、appSecret以及userId这三个参数,生成一个SdkEntity实体,调用getSpeechResult接口获取语音识别和语义处理的结果
- 组织输出结果返回。
com.happycxz.olami中有四个文件:
第1个,AsrAdditionInfo.java是用来检查https请求中formdata必选的三个参数是否都上传了,是否合法。
这里我额外做了个限制,除了在olami平台上申请的appKey和appSecret之外,appKey还要额外告知我,我在支持列表中加上才可以用,避免被攻击了大家都没法用,没办法,小窝带宽有限。
第2个,OlamiEntityFactory.java是做一个SdkEntity的缓存,如果formdata中上传的userId不一样,这个缓存就没用了:(
第3个,OlamiKeyManager.java是配合第一个文件做appKey限制管理的。
第4个,SdkEntity.java是对接olami接口的部分,主要是从olami java sdk sample代码中拷出来改改的。代码如下:
package com.happycxz.olami;
import java.io.IOException;
import java.security.NoSuchAlgorithmException;
import com.google.gson.Gson;
import com.happycxz.utils.Util;
import ai.olami.cloudService.APIConfiguration;
import ai.olami.cloudService.APIResponse;
import ai.olami.cloudService.CookieSet;
import ai.olami.cloudService.SpeechRecognizer;
import ai.olami.cloudService.SpeechResult;
import ai.olami.nli.NLIResult;
import ai.olami.util.GsonFactory;
public class SdkEntity {
//indicate simplified input
private static int localizeOption = APIConfiguration.LOCALIZE_OPTION_SIMPLIFIED_CHINESE;
// * Replace the audio type you want to analyze with this variable.
private static int audioType = SpeechRecognizer.AUDIO_TYPE_PCM_WAVE;
//private static int audioType = SpeechRecognizer.AUDIO_TYPE_PCM_RAW;
// * Replace FALSE with this variable if your test file is not final audio.
private static boolean isTheLastAudio = true;
private APIConfiguration config = null;
//configure text recognizer
SpeechRecognizer recoginzer = null;
// * Prepare to send audio by a new task identifier.
//CookieSet cookie = new CookieSet();
// json string for print pretty
private static Gson jsonDump = GsonFactory.getDebugGson(false);
// normal json string
private static Gson mGson = GsonFactory.getNormalGson();
public SdkEntity(String appKey, String appSecret, String userId) {
Util.d("new SdkEntity() start. appKey:" + appKey + ", appSecret: " + appSecret + ", userId: " + userId);
try {
config = new APIConfiguration(appKey, appSecret, localizeOption);
recoginzer = new SpeechRecognizer(config);
recoginzer.setEndUserIdentifier(userId);
recoginzer.setTimeout(10000);
recoginzer.setAudioType(audioType);
} catch (Exception e) {
Util.w("new SdkEntity() exception", e);
}
Util.d("new SdkEntity() done");
}
public String getSpeechResult(String inputFilePath) throws NoSuchAlgorithmException, IOException, InterruptedException {
String lastResult = "";
Util.d("SdkEntity.getSpeechResult() inputFilePath:" + inputFilePath);
CookieSet cookie = new CookieSet();
// * Start sending audio.
APIResponse response = recoginzer.uploadAudio(cookie, inputFilePath, audioType, isTheLastAudio);
//
// You can also send audio data from a buffer (in bytes).
//
// For Example :
// ===================================================================
// byte[] audioBuffer = Files.readAllBytes(Paths.get(inputFilePath));
// APIResponse response = recoginzer.uploadAudio(cookie, audioBuffer, audioType, isTheLastAudio);
// ===================================================================
//
Util.d("\nOriginal Response : " + response.toString());
Util.d("\n---------- dump ----------\n");
Util.d(jsonDump.toJson(response));
Util.d("\n--------------------------\n");
//四种结果,full最完整,seg, nli, asr只包括那一部分
String full = "", seg = "", nli = "", asr = "";
// Check request status.
if (response.ok()) {
// Now we can try to get recognition result.
Util.d("\n[Get Speech Result] =====================");
while (true) {
Thread.sleep(500);
// * Get result by the task identifier you used for audio upload.
Util.d("\nRequest CookieSet[" + cookie.getUniqueID() + "] speech result...");
response = recoginzer.requestRecognitionWithAll(cookie);
Util.d("\nOriginal Response : " + response.toString());
Util.d("\n---------- dump ----------\n");
Util.d(jsonDump.toJson(response));
Util.d("\n--------------------------\n");
// Check request status.
if (response.ok() && response.hasData()) {
full = mGson.toJson(response.getData());
// * Check to see if the recognition has been completed.
SpeechResult sttResult = response.getData().getSpeechResult();
if (sttResult.complete()) {
// * Get speech-to-text result
Util.p("* STT Result : " + sttResult.getResult());
asr = mGson.toJson(sttResult);
// * Check to see if the recognition has be
// Because we used requestRecognitionWithAll()
// So we should be able to get more results.
// --- Like the Word Segmentation.
if (response.getData().hasWordSegmentation()) {
String[] ws = response.getData().getWordSegmentation();
for (int i = 0; i < ws.length; i++) {
Util.d("* Word[" + i + "] " + ws[i]);
}
seg = response.getData().getWordSegmentationSingleString();
}
// --- Or the NLI results.
if (response.getData().hasNLIResults()) {
NLIResult[] nliResults = response.getData().getNLIResults();
nli = mGson.toJson(nliResults);
}
// * Done.
break;
} else {
// The recognition is still in progress.
// But we can still get immediate recognition results.
Util.d("* STT Result [Not yet completed] ");
Util.d(" --> " + sttResult.getResult());
}
}
}
} else {
// Error
Util.w("* Error! Code : " + response.getErrorCode(), null);
Util.w(response.getErrorMessage(), null);
}
lastResult = full;
Util.d("\n===========================================\n");
return lastResult;
}
public static void main(String[] args) throws NoSuchAlgorithmException, IOException, InterruptedException {
Util.p("SdkEntity.main() start...");
int argLen = args.length;
Util.d("SdkEntity.main() args.length[" + argLen + "]:");
for (String arg : args) {
Util.d("SpeexPcm.main() arg[" + arg + "]");
}
new SdkEntity("b4118cd178064b45b7c8f1242bcde31f", "7908028332a64e47b8336d71ad3ce9ab", "abdd").getSpeechResult(args[0]);
Util.p("SdkEntity.main() end...");
}
}
com.happycxz.olami中有两个文件,是使用到的一些util、读配置文件、系统日志等部分。
另外WEB-INFO/lib中加载olami的java sdk,如图:

另外,额外附上一张olami-java-client-1.0.1-source.jar中关于默认采用speex压缩的源码部分:

怎么用
接口:
https://api.happycxz.com/test/silk2asr/olami/asr
| 参数 | 是否必选 | 说明 |
|---|---|---|
| appKey | 是 | 从olami.cn上申请的key |
| appSecret | 是 | 从olami.cn上申请的secret |
| userId | 是 | 用户的唯一标识,比如手机号,或唯一性的ID,或IMEI号之类的 |
formdata必选参数:
| 参数 | 是否必选 | 说明 |
|---|---|---|
| appKey | 是 | 从olami.cn上申请的key |
| appSecret | 是 | 从olami.cn上申请的secret |
| userId | 是 | 用户的唯一标识,比如手机号,或唯一性的ID,或IMEI号之类的 |
返回数据res.data就是olami开放平台返回结果完全一致,未经修改,具体参考他们在线文档:
olami开放平台的API接口返回数据格式
大概的是 seg字段是语音识别分段结果,asr是语音识别结果,nli是语义或语义处理的结果。小程序的开发工具上没法DEBUG,就没办法截一段例子说明了。
调用案例:“遥知之”智能小秘
欢迎扫码试用。这一版支持语音识别,博客还没来得及更新,稍后我会把相关代码在这个文章“ 我的微信小程序支持语音识别啦!“遥知之”不再装聋”中分享出来,主要是分享一下微信小程序里如何上传SILK录音部分以及如何解析olami返回的语音识别和语义处理结果的代码。
最后闲话
本文欢迎转载,原文链接:http://blog.csdn.net/happycxz/article/details/78016299
服务端工程的代码分享:
本文所有源码对应码云链接:https://gitee.com/happycxz/silk2asr
本文所有源码对应github链接:https://github.com/happycxz/silk2asr
如果有不明白的都可以在本博客文章后面留言,也欢迎大家指正文中的理解或文字描述错误或不清楚的部分,我将及时更正,避免带人跳坑。
需要用这个接口的,appKey可以在这里留言或私信告诉我,我帮你加进我的白名单你才可以用。